标签:style blog http color 使用 os io strong
Hive架构
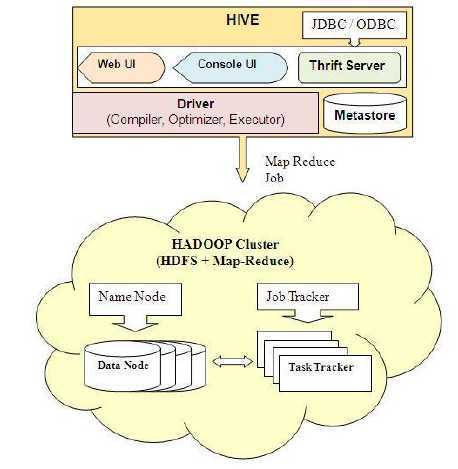
1)用户接口:
CLI(hive shell):命令行工具;启动方式:hive 或者 hive --service cli
ThriftServer:通过Thrift对外提供服务,默认端口是10000;启动方式:hive --service hiveserver
WEBUI(浏览器访问hive):通过浏览器访问hive,默认端口是9999;启动方式:hive --service hwi
2)元数据存储(Metastore):启动方式:hive -service metastore
默认存储在自带的数据库derby中,线上使用时一般采用MySQL;
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、列/分区 属性、表的类型(是否是外部表)、表的数据所在目录等;
database是表(table)的名字空间。默认的数据库是default;
table的原数据信息有:列和它们的类型、拥有者(owner),存储空间和SerDe信息;
partition每个分区都有自己的列,存储空间和SerDe信息等
3)驱动器(Driver):
编译器、优化器、执行器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成;
生成的查询计划存储在HDFS中,并在随后的MapReduce调用执行;
4)Hadoop
用MapReduce计算,用HDFS存储;
Hive的数据存储在HDFS之上,包括Database、Table、Partition等;
Hive的默认数据仓库是/user/hive/warehouse,可以在hive-site.xml中由hive.metastore.warehouse.dir进行配置;
除了外部表外,每个表在数据仓库下都有一个相应的存储目录;
当数据被加载到表中时,不会对数据进行任何转换,只是将数据移动到数据仓库中去;
非外部表被删除时,表数据和元数据都被删除;外部表被删除时,只删除元数据不删除表数据;
分区表的一个Partition对应该表下的一个子目录;
每个Bucket对应一个文件
大部分的查询由MapReduce计算完成;两种情况不跑MapReduce:select * from xxx和select * from xxx where 分区字段不跑mapreduce
5)hiveserver2
启动方式:hive --service hiveserver2
HiveServer2是HiveServer的升级版,提供了新的Thrift API处理JDBC/ODBC、Kerberos身份验证、多客户端并发等;
HiveServer2提供了新的CLI:BeeLine,是hive0.11后引入的,基于SQLLine,可以作为Hive jdbc client端访问HiveServer2,启动一个Beeline对应一个session;
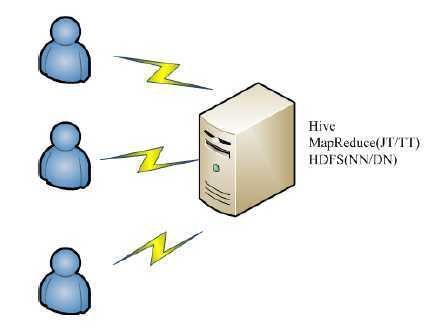
Hive单机环境部署图
Hive集群环境部署图
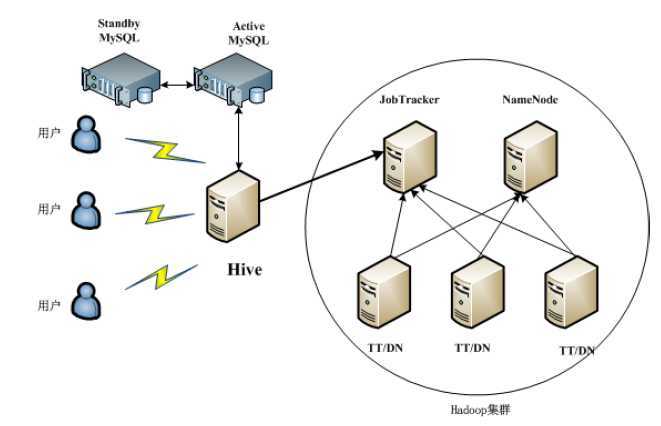
注:在生产环境中元数据需要采用主备服务器的方式防止宕机;
Hive运行模式
Hive运行模式即任务的执行环境,分为:本地和集群两种
可以通过mapred.job.tracker来指定,指定方式:
hive> SET mapred.job.tracker=local
不设置默认为集群方式。
Hive与关系型数据库的区别
Hive和关系型数据库并没有什么关系,只是语法类似而已。
|
|
Hive |
SQL |
|
数据插入 |
支持批量导入 |
支持单条和批量导入 |
|
数据更新 |
不支持(数据导入后就不再支持改变) |
支持 |
|
索引 |
支持 |
支持 |
|
分区 |
支持 |
支持 |
|
执行延迟 |
高 |
低 |
|
扩展 |
好 |
有限 |
Hive基础之Hive体系架构&运行模式&Hive与关系型数据的区别,布布扣,bubuko.com
Hive基础之Hive体系架构&运行模式&Hive与关系型数据的区别
标签:style blog http color 使用 os io strong
原文地址:http://www.cnblogs.com/luogankun/p/3901734.html