标签:
先验概率(prior probability)是指根据以往经验和分析得到的概率,如全概率公式,它往往作为"由因求果"问题中的"因"出现的概率。
在贝叶斯统计中,先验概率分布,即关于某个变量 p 的概率分布,是在获得某些信息或者依据前,对 p 的不确定性进行猜测。例如, p 可以是抢火车票开始时,抢到某一车次的概率。这是对不确定性(而不是随机性)赋予一个量化的数值的表征,这个量化数值可以是一个参数,或者是一个潜在的变量。
先验概率仅仅依赖于主观上的经验估计,也就是事先根据已有的知识的推断,在应用贝叶斯理论时,通常将先验概率乘以似然函数(likelihoodfunction)再归一化后,得到后验概率分布,后验概率分布即在已知给定的数据后,对不确定性的条件分布。
最大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。简单而言,假设我们要统计全国人口的身高,首先假设这个身高服从服从正态分布,但是该分布的均值与方差未知。我们没有人力与物力去统计全国每个人的身高,但是可以通过采样,获取部分人的身高,然后通过最大似然估计来获取上述假设中的正态分布的均值与方差。
最大似然估计中采样需满足一个很重要的假设,就是所有的采样都是独立同分布的。下面我们具体描述一下最大似然估计:
首先,假设 为独立同分布的采样,θ为模型参数,f为我们所使用的模型,遵循我们上述的独立同分布假设。参数为θ的模型f产生上述采样可表示为
为独立同分布的采样,θ为模型参数,f为我们所使用的模型,遵循我们上述的独立同分布假设。参数为θ的模型f产生上述采样可表示为
![]()
回到上面的“模型已定,参数未知”的说法,此时,我们已知的为 ,未知为θ,故似然定义为:
,未知为θ,故似然定义为:

在实际应用中常用的是两边取对数,得到公式如下:

其中 称为对数似然,而
称为对数似然,而 称为平均对数似然。而我们平时所称的最大似然为最大的对数平均似然,即:
称为平均对数似然。而我们平时所称的最大似然为最大的对数平均似然,即:

举个别人博客中的例子,假如有一个罐子,里面有黑白两种颜色的球,数目多少不知,两种颜色的比例也不知。我 们想知道罐中白球和黑球的比例,但我们不能把罐中的球全部拿出来数。现在我们可以每次任意从已经摇匀的罐中拿一个球出来,记录球的颜色,然后把拿出来的球 再放回罐中。这个过程可以重复,我们可以用记录的球的颜色来估计罐中黑白球的比例。假如在前面的一百次重复记录中,有七十次是白球,请问罐中白球所占的比例最有可能是多少?很多人马上就有答案了:70%。而其后的理论支撑是什么呢?
我们假设罐中白球的比例是p,那么黑球的比例就是1-p。因为每抽一个球出来,在记录颜色之后,我们把抽出的球放回了罐中并摇匀,所以每次抽出来的球的颜 色服从同一独立分布。这里我们把一次抽出来球的颜色称为一次抽样。题目中在一百次抽样中,七十次是白球的概率是P(Data | M),这里Data是所有的数据,M是所给出的模型,表示每次抽出来的球是白色的概率为p。如果第一抽样的结果记为x1,第二抽样的结果记为x2...那么Data = (x1,x2,…,x100)。这样,
P(Data | M)
= P(x1,x2,…,x100|M)
= P(x1|M)P(x2|M)…P(x100|M)
= p^70(1-p)^30.
那么p在取什么值的时候,P(Data |M)的值最大呢?将p^70(1-p)^30对p求导,并其等于零。
70p^69(1-p)^30-p^70*30(1-p)^29=0。
解方程可以得到p=0.7。
在边界点p=0,1,P(Data|M)=0。所以当p=0.7时,P(Data|M)的值最大。这和我们常识中按抽样中的比例来计算的结果是一样的。
假如我们有一组连续变量的采样值(x1,x2,…,xn),我们知道这组数据服从正态分布,标准差已知。请问这个正态分布的期望值为多少时,产生这个已有数据的概率最大?
P(Data | M) = ?
根据公式

可得:
对μ求导可得 ,则最大似然估计的结果为μ=(x1+x2+…+xn)/n
,则最大似然估计的结果为μ=(x1+x2+…+xn)/n
由上可知最大似然估计的一般求解过程:
(1) 写出似然函数;
(2) 对似然函数取对数,并整理;
(3) 求导数 ;
(4) 解似然方程
注意:最大似然估计只考虑某个模型能产生某个给定观察序列的概率。而未考虑该模型本身的概率,这点与贝叶斯估计区别。
贝叶斯法则
贝叶斯法则又被称为贝叶斯定理、贝叶斯规则,是指概率统计中的应用所观察到的现象对有关概率分布的主观判断(即先验概率)进行修正的标准方法。当分析样本大到接近总体数时,样本中事件发生的概率将接近于总体中事件发生的概率。
作为一个规范的原理,贝叶斯法则对于所有概率的解释是有效的;然而,频率主义者和贝叶斯主义者对于在应用中概率如何被赋值有着不同的看法:频率主义者根据随机事件发生的频率,或者总体样本里面的个数来赋值概率;贝叶斯主义者要根据未知的命题来赋值概率。
贝叶斯统计中的两个基本概念是先验分布和后验分布:
1、先验分布。总体分布参数θ的一个概率分布。贝叶斯学派的根本观点,是认为在关于总体分布参数θ的任何统计推断问题中,除了使用样本所提供的信息外,还必须规定一个先验分布,它是在进行统计推断时不可缺少的一个要素。他们认为先验分布不必有客观的依据,可以部分地或完全地基于主观信念。
2、后验分布。根据样本分布和未知参数的先验分布,用概率论中求条件概率分布的方法,求出的在样本已知下,未知参数的条件分布。因为这个分布是在抽样以后才得到的,故称为后验分布。贝叶斯推断方法的关键是任何推断都必须且只须根据后验分布,而不能再涉及样本分布。
贝叶斯公式为:
P(A∩B)=P(A)*P(B|A)=P(B)*P(A|B)
P(A|B)=P(B|A)*P(A)/P(B)
其中:
1、P(A)是A的先验概率或边缘概率,称作"先验"是因为它不考虑B因素。
2、P(A|B)是已知B发生后A的条件概率,也称作A的后验概率。
3、P(B|A)是已知A发生后B的条件概率,也称作B的后验概率,这里称作似然度。
4、P(B)是B的先验概率或边缘概率,这里称作标准化常量。
5、P(B|A)/P(B)称作标准似然度。
贝叶斯法则又可表述为:
后验概率=(似然度*先验概率)/标准化常量=标准似然度*先验概率
P(A|B)随着P(A)和P(B|A)的增长而增长,随着P(B)的增长而减少,即如果B独立于A时被观察到的可能性越大,那么B对A的支持度越小。
在更一般化的情况,假设{Ai}是事件集合里的部分集合,对于任意的Ai,贝叶斯定理可用下式表示: 
贝叶斯公式为利用搜集到的信息对原有判断进行修正提供了有效手段。在采样之前,经济主体对各种假设有一个判断(先验概率),关于先验概率的分布,通常可根据经济主体的经验判断确定(当无任何信息时,一般假设各先验概率相同),较复杂精确的可利用包括最大熵技术或边际分布密度以及相互信息原理等方法来确定先验概率分布。
例如,一座别墅在过去的20年里一共发生过2次被盗,别墅的主人有一条狗,狗平均每周晚上叫3次,在盗贼入侵时狗叫的概率被估计为0.9,问题是:在狗叫的时候发生入侵的概率是多少?
我们假设A事件为狗在晚上叫,B为盗贼入侵,则P(A)=3/7,P(B)=2/(20·365)=2/7300,P(A|B)=0.9,按照公式很容易得出结果:P(B|A)=0.9*(2/7300)/(3/7)=0.00058
另一个例子,现分别有A,B两个容器,在容器A里分别有7个红球和3个白球,在容器B里有1个红球和9个白球,现已知从这两个容器里任意抽出了一个球,且是红球,问这个红球是来自容器A的概率是多少?
假设已经抽出红球为事件B,从容器A里抽出球为事件A,则有:P(B)=8/20,P(A)=1/2,P(B|A)=7/10,按照公式,则有:P(A|B)=(7/10)*(1/2)/(8/20)=0.875
最大后验估计是根据经验数据获得对难以观察的量的点估计。与最大似然估计类似,但是最大的不同时,最大后验估计的融入了要估计量的先验分布在其中。故最大后验估计可以看做规则化的最大似然估计。
首先,我们回顾上篇文章中的最大似然估计,假设x为独立同分布的采样,θ为模型参数,f为我们所使用的模型。那么最大似然估计可以表示为:

现在,假设θ的先验分布为g。通过贝叶斯理论,对于θ的后验分布如下式所示:

最后验分布的目标为:

注:最大后验估计可以看做贝叶斯估计的一种特定形式。
举例来说:
假设有五个袋子,各袋中都有无限量的饼干(樱桃口味或柠檬口味),已知五个袋子中两种口味的比例分别是
樱桃 100%
樱桃 75% + 柠檬 25%
樱桃 50% + 柠檬 50%
樱桃 25% + 柠檬 75%
柠檬 100%
如果只有如上所述条件,那问从同一个袋子中连续拿到2个柠檬饼干,那么这个袋子最有可能是上述五个的哪一个?
我们首先采用最大似然估计来解这个问题,写出似然函数。假设从袋子中能拿出柠檬饼干的概率为p(我们通过这个概率p来确定是从哪个袋子中拿出来的),则似然函数可以写作

由于p的取值是一个离散值,即上面描述中的0,25%,50%,75%,1。我们只需要评估一下这五个值哪个值使得似然函数最大即可,得到为袋子5。这里便是最大似然估计的结果。
上述最大似然估计有一个问题,就是没有考虑到模型本身的概率分布,下面我们扩展这个饼干的问题。
假设拿到袋子1或5的机率都是0.1,拿到2或4的机率都是0.2,拿到3的机率是0.4,那同样上述问题的答案呢?这个时候就变MAP了。我们根据公式

写出我们的MAP函数。

根据题意的描述可知,p的取值分别为0,25%,50%,75%,1,g的取值分别为0.1,0.2,0.4,0.2,0.1.分别计算出MAP函数的结果为:0,0.0125,0.125,0.28125,0.1.由上可知,通过MAP估计可得结果是从第四个袋子中取得的最高。
上述都是离散的变量,那么连续的变量呢?假设 为独立同分布的
为独立同分布的 ,μ有一个先验的概率分布为
,μ有一个先验的概率分布为 。那么我们想根据来找到μ的最大后验概率。根据前面的描述,写出MAP函数为:
。那么我们想根据来找到μ的最大后验概率。根据前面的描述,写出MAP函数为:

此时我们在两边取对数可知。所求上式的最大值可以等同于求

的最小值。求导可得所求的μ为

以上便是对于连续变量的MAP求解的过程。
在MAP中我们应注意的是:
MAP与MLE最大区别是MAP中加入了模型参数本身的概率分布,或者说。MLE中认为模型参数本身的概率的是均匀的,即该概率为一个固定值。
以上MLE求的是找出一组能够使似然函数最大的参数,即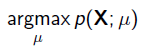 。 现在问题稍微复杂一点点,假如这个参数
。 现在问题稍微复杂一点点,假如这个参数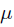 有一个先验概率呢?比如说,在上面抛硬币的例子,假如我们的经验告诉我们,硬币一般都是匀称的,也就是=0.5的可能性最大,=0.2的可能性比较小,那么参数该怎么估计呢?这就是MAP要考虑的问题。
MAP优化的是一个后验概率,即给定了观测值后使概率最大:
有一个先验概率呢?比如说,在上面抛硬币的例子,假如我们的经验告诉我们,硬币一般都是匀称的,也就是=0.5的可能性最大,=0.2的可能性比较小,那么参数该怎么估计呢?这就是MAP要考虑的问题。
MAP优化的是一个后验概率,即给定了观测值后使概率最大:
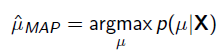
把上式根据贝叶斯公式展开:
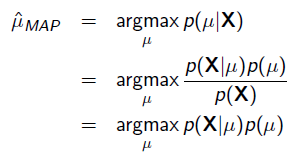
我们可以看出第一项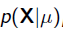 就是似然函数,第二项
就是似然函数,第二项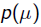 就是参数的先验知识。取log之后就是:
就是参数的先验知识。取log之后就是:
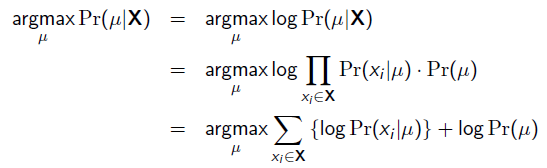
回到刚才的抛硬币例子,假设参数有一个先验估计,它服从Beta分布,即:
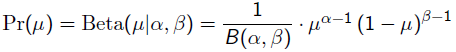
而每次抛硬币任然服从二项分布:
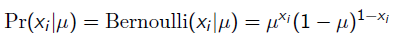
那么,目标函数的导数为:
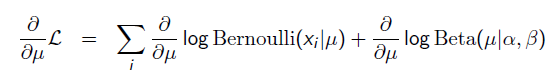
求导的第一项已经在上面MLE中给出了,第二项为:
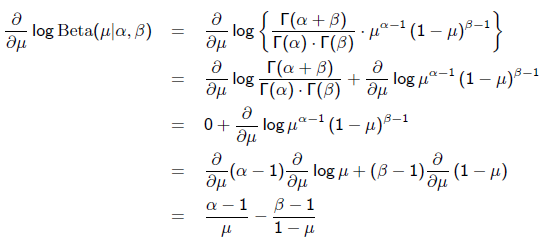
令导数为0,求解为:
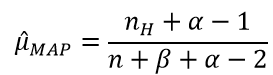
其中,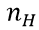 表示正面朝上的次数。这里看以看出,MLE与MAP的不同之处在于,MAP的结果多了一些先验分布的参数。
表示正面朝上的次数。这里看以看出,MLE与MAP的不同之处在于,MAP的结果多了一些先验分布的参数。
补充知识: Beta分布
Beat分布是一种常见的先验分布,它形状由两个参数控制,定义域为[0,1]
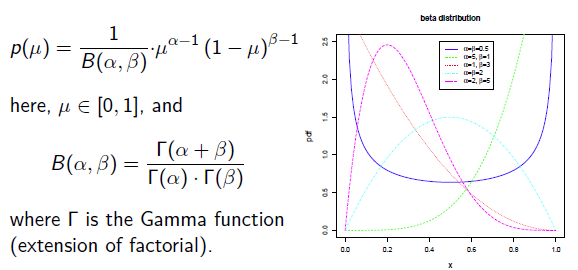
Beta分布的最大值是x等于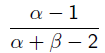 的时候:
的时候:
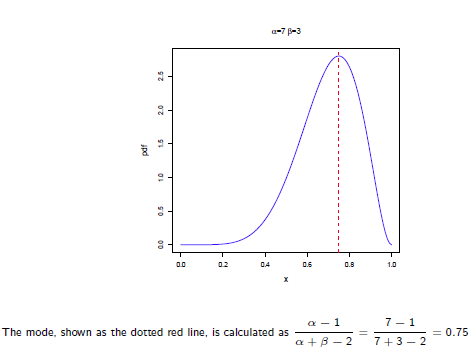
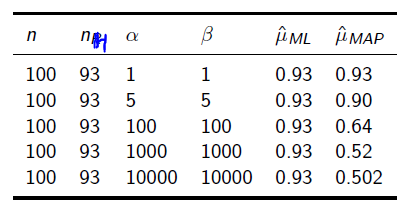
所以在抛硬币中,如果先验知识是说硬币是匀称的,那么就让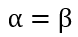 。 但是很显然即使它们相等,它两的值也对最终结果很有影响。它两的值越大,表示偏离匀称的可能性越小:
。 但是很显然即使它们相等,它两的值也对最终结果很有影响。它两的值越大,表示偏离匀称的可能性越小:
标签:
原文地址:http://blog.csdn.net/guohecang/article/details/52313046
