标签:
相关的公式
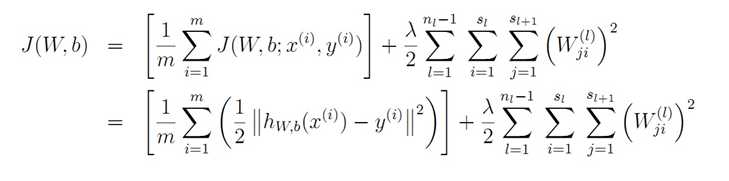
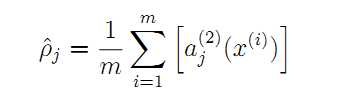
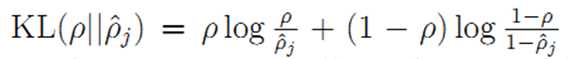
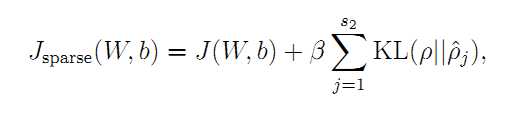
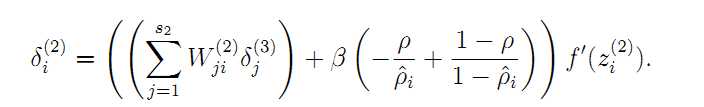
证明参考PPT: http://wenku.baidu.com/link?url=dBZZq7TYJOnIw2mwilKsJT_swT52I0OoikmvmgBaYE_NvP_KChFZ-HOURH5LMiLEuSVFcGmJ0bQfkG-ZYk-IRJf7D-w6P9PBec8EZ9IxgFS
Python实现代码参考
@author: Paul Rothnie
email : paul.rothnie@googlemail.com
https://github.com/siddharth950/Sparse-Autoencoder
1 # -*- coding: utf-8 -*- 2 # Refer to https://github.com/siddharth950/Sparse-Autoencoder 3 4 import numpy as np 5 import numpy.linalg as la 6 import scipy.io 7 import scipy.optimize 8 import matplotlib.pyplot 9 import time 10 import struct 11 import array 12 13 class sparse_autoencoder(object): #稀疏自编码类 14 def __init__(self, visible_size, hidden_size, lambda_, rho, beta): 15 self.visible_size = visible_size 16 self.hidden_size = hidden_size 17 self.lambda_ = lambda_ 18 self.rho = rho 19 self.beta = beta 20 w_max = np.sqrt(6.0 / (visible_size + hidden_size + 1.0)) 21 w_min = -w_max 22 W1 = (w_max - w_min) * np.random.random_sample(size = (hidden_size, 23 visible_size)) + w_min 24 W2 = (w_max - w_min) * np.random.random_sample(size = (visible_size, 25 hidden_size)) + w_min 26 b1 = np.zeros(hidden_size) 27 b2 = np.zeros(visible_size) 28 self.idx_0 = 0 29 self.idx_1 = hidden_size * visible_size # 64*25 30 self.idx_2 = self.idx_1 + hidden_size * visible_size # 25*64 31 self.idx_3 = self.idx_2 + hidden_size # 64 32 self.idx_4 = self.idx_3 + visible_size # 25 33 self.initial_theta = np.concatenate((W1.flatten(), W2.flatten(), 34 b1.flatten(), b2.flatten())) 35 36 def sigmoid(self, x): # sigmoid函数 37 return 1.0 / (1.0 + np.exp(-x)) 38 39 def unpack_theta(self, theta): # 获取传递给scipy.optimize.minimize的theta 40 W1 = theta[self.idx_0 : self.idx_1] 41 W1 = np.reshape(W1, (self.hidden_size, self.visible_size)) 42 W2 = theta[self.idx_1 : self.idx_2] 43 W2 = np.reshape(W2, (self.visible_size, self.hidden_size)) 44 b1 = theta[self.idx_2 : self.idx_3] 45 b1 = np.reshape(b1, (self.hidden_size, 1)) 46 b2 = theta[self.idx_3 : self.idx_4] 47 b2 = np.reshape(b2, (self.visible_size, 1)) 48 return W1, W2, b1, b2 49 50 def cost(self, theta, visible_input): # cost函数 51 W1, W2, b1, b2 = self.unpack_theta(theta) 52 # layer=f(w*l+b) 53 hidden_layer = self.sigmoid(np.dot(W1, visible_input) + b1) 54 output_layer = self.sigmoid(np.dot(W2, hidden_layer) + b2) 55 m = visible_input.shape[1] 56 error = -(visible_input - output_layer) 57 sum_sq_error = 0.5 * np.sum(error * error, axis = 0) 58 avg_sum_sq_error = np.mean(sum_sq_error) 59 reg_cost = self.lambda_ * (np.sum(W1 * W1) + np.sum(W2 * W2)) / 2.0 # L2正则化 60 rho_bar = np.mean(hidden_layer, axis=1) # 平均激活程度 61 KL_div = np.sum(self.rho * np.log(self.rho / rho_bar) + 62 (1 - self.rho) * np.log((1-self.rho) / (1- rho_bar))) # 相对熵 63 cost = avg_sum_sq_error + reg_cost + self.beta * KL_div # 损失函数 64 KL_div_grad = self.beta * (- self.rho / rho_bar + (1 - self.rho) / 65 (1 - rho_bar)) 66 del_3 = error * output_layer * (1.0 - output_layer) 67 del_2 = np.transpose(W2).dot(del_3) + KL_div_grad[:, np.newaxis] 68 69 del_2 *= hidden_layer * (1 - hidden_layer) # *=残差项 70 W1_grad = del_2.dot(visible_input.transpose()) / m # delt_w=del*(l.T) 71 W2_grad = del_3.dot(hidden_layer.transpose()) / m 72 b1_grad = del_2 # delt_b=del 73 b2_grad = del_3 74 W1_grad += self.lambda_ * W1 75 W2_grad += self.lambda_ * W2 76 b1_grad = b1_grad.mean(axis = 1) 77 b2_grad = b2_grad.mean(axis = 1) 78 theta_grad = np.concatenate((W1_grad.flatten(), W2_grad.flatten(), 79 b1_grad.flatten(), b2_grad.flatten())) 80 return [cost, theta_grad] 81 82 def train(self, data, max_iterations): # 训练令cost最小 83 opt_soln = scipy.optimize.minimize(self.cost, 84 self.initial_theta, 85 args = (data,), method = ‘L-BFGS-B‘, 86 jac = True, options = 87 {‘maxiter‘:max_iterations} ) 88 opt_theta = opt_soln.x 89 return opt_theta 90 91 92 def normalize_data(data): # 0.1<=data[i][j]<=0.9 93 data = data - np.mean(data) 94 pstd = 3 * np.std(data) 95 data = np.maximum(np.minimum(data, pstd), -pstd) / pstd 96 data = (data + 1.0) * 0.4 + 0.1 97 return data 98 99 def loadMNISTImages(file_name): # 获取mnist数据 100 image_file = open(file_name, ‘rb‘) 101 head1 = image_file.read(4) 102 head2 = image_file.read(4) 103 head3 = image_file.read(4) 104 head4 = image_file.read(4) 105 num_examples = struct.unpack(‘>I‘, head2)[0] 106 num_rows = struct.unpack(‘>I‘, head3)[0] 107 num_cols = struct.unpack(‘>I‘, head4)[0] 108 dataset = np.zeros((num_rows*num_cols, num_examples)) 109 images_raw = array.array(‘B‘, image_file.read()) 110 image_file.close() 111 for i in range(num_examples): 112 limit1 = num_rows * num_cols * i 113 limit2 = num_rows * num_cols * (i + 1) 114 dataset[:, i] = images_raw[limit1: limit2] 115 return dataset / 255 116 117 118 def load_data(num_patches, patch_side): # 随机选取num_patches个数据 119 images = scipy.io.loadmat(‘IMAGES.mat‘) # 515*512*10 120 images = images[‘IMAGES‘] 121 patches = np.zeros((patch_side * patch_side, num_patches)) 122 seed = 1234 123 rand = np.random.RandomState(seed) 124 image_index = rand.random_integers( 0, 512 - patch_side, size = 125 (num_patches, 2)) 126 image_number = rand.random_integers(0, 10 - 1, size = num_patches) 127 for i in xrange(num_patches): 128 idx_1 = image_index[i, 0] 129 idx_2 = image_index[i, 1] 130 idx_3 = image_number[i] 131 patch = images[idx_1:idx_1 + patch_side, idx_2:idx_2 + patch_side, 132 idx_3] 133 patch = patch.flatten() 134 patches[:,i] = patch 135 patches = normalize_data(patches) 136 return patches 137 138 def visualizeW1(opt_W1, vis_patch_side, hid_patch_side): # 可视化 139 figure, axes = matplotlib.pyplot.subplots(nrows = hid_patch_side, 140 ncols = hid_patch_side) 141 index = 0 142 for axis in axes.flat: 143 axis.imshow(opt_W1[index, :].reshape(vis_patch_side, 144 vis_patch_side), cmap = matplotlib.pyplot.cm.gray, 145 interpolation = ‘nearest‘) 146 axis.set_frame_on(False) 147 axis.set_axis_off() 148 index += 1 149 matplotlib.pyplot.show() 150 151 def run_sparse_ae(): # 稀疏自编码器 152 beta = 3.0 153 lamda = 0.0001 154 rho = 0.01 155 visible_side = 8 156 hidden_side = 5 157 visible_size = visible_side * visible_side 158 hidden_size = hidden_side * hidden_side 159 m = 10000 160 max_iterations = 400 161 training_data = load_data(num_patches = m, patch_side = visible_side) 162 sae = sparse_autoencoder(visible_size, hidden_size, lamda, rho, beta) 163 opt_theta = sae.train(training_data, max_iterations) 164 opt_W1 = opt_theta[0 : visible_size * hidden_size].reshape(hidden_size, 165 visible_size) 166 visualizeW1(opt_W1,visible_side, hidden_side) 167 168 def run_sparse_ae_MNIST(): # 矢量化MNIST 169 beta = 3.0 170 lamda = 3e-3 171 rho = 0.1 172 visible_side = 28 173 hidden_side = 14 174 visible_size = visible_side * visible_side 175 hidden_size = hidden_side * hidden_side 176 m = 10000 177 max_iterations = 400 178 training_data = loadMNISTImages(‘train-images.idx3-ubyte‘) 179 training_data = training_data[:, 0:m] 180 sae = sparse_autoencoder(visible_size, hidden_size, lamda, rho, beta) 181 opt_theta = sae.train(training_data, max_iterations) 182 opt_W1 = opt_theta[0 : visible_size * hidden_size].reshape(hidden_size, 183 visible_size) 184 visualizeW1(opt_W1, visible_side, hidden_side) 185 186 if __name__ == "__main__": 187 run_sparse_ae() 188 #run_sparse_ae_MNIST()


标签:
原文地址:http://www.cnblogs.com/qw12/p/5817530.html