标签:
在上一篇中我给出了整个SMR学习部分的思维导图,说的比较抽象,这一部分仍然是从整体上来学SMR部分;下面的部分都是总结的,更加精练的话,可以去看论文《叠瓦式磁记录磁盘的研究进展》,这篇论文是我们写的有关SMR磁盘的一个综述;
接下来的部分相对于论文中提到的会更加的详细,针对其中的一些部分,我会在后面更加详细的分析;
本文属于原创,转载请私信我,并指明出处!
Shingled magnetic Recording作为下一代被用于增加硬盘单位面积内的存储容量的技术,在将来的一段时间内,将会使得磁盘容量的井喷式的爆发增长。文中与传统磁盘相对比介绍SMR磁盘的组织结构和特点,得出SMR磁盘的种类。根据是否有STL层,区分为host-managed SMR磁盘和drive-managed SMR磁盘。本文中将介绍drive-managed磁盘上有关数据布局,映射方式以及碎片处理的研究方法和研究现状,同时还会介绍host-managed磁盘中band固定时的三种不同应用,分别是SMRDB,HISMRFS,以及strict append。还会介绍磁盘band不固定时的另一种应用,caveat scriptor。以上应用从不同的方面改进了SMR的不足之处,发挥了SMR磁盘的容量以及性能特点。以上整体说明了SMR现有的研究现状。
随着数据密度快速增加到超顺磁限定的极限密度[1],从制造工艺上来说,进一步的减小每比特的大小来增加单位密度的存储容量变得不可能了。此外,随着大数据时代的到来,减少单位存储容量的代价这一需求变得越来越迫切。新的存储技术,比如热辅助磁存储技术(HAMR)[2]和比特模式磁存储(BPMR)[3]正处于火热的研究之中,但是在这两种技术商业化之前还有一些工程上的重大挑战需要克服。所以这两种方法目前并不可取。
相对于其他新的存储技术,Shingled magnetic Recording (SMR)似乎是目前提高存储容量最好的办法。SMR磁盘在很多方面都能够代替传统的磁盘[4] [5] [6] [7] [8] [9],这是因为生产商的制造工艺只需要做出细小的改变就能够生产制造出来[6],与传统磁盘是相互兼容的。下面来详细介绍Shingled magnetic Recording (SMR)。
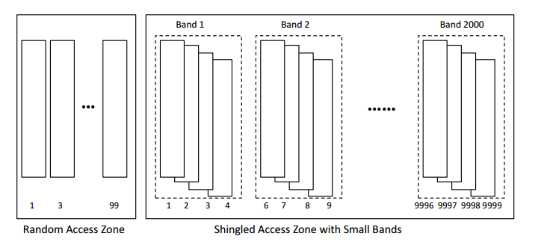
SMR磁盘是如何提供可观的更高的存储密度的呢,这是因为磁盘采用了瓦片式的结构[11],将连续的tracks部分的覆盖放置,以此来达到存放更多的数据的效果。传统磁盘和SMR磁盘的组织结构如下图所示。
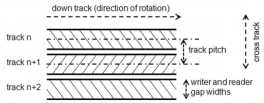
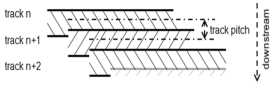
传统磁盘是一个个单独的track被小的间隔隔开来防止track之间的写影响,由于现代工业条件的限制,不可能再缩短track之间的距离来达到增加容量的目的。与此同时,研究发现在磁盘的读写中,对写磁头和读磁头长度需求是可以不一样的。写磁头的长度要大于读磁头的长度,因此Shingled magnetic Recording磁盘问世了。
Shingled magnetic Recording磁盘容量增加是以牺牲随机写操作的能力为代价的。当对上游的数据进行写操作的时候,会因为覆盖会对下游的数据进行覆盖,因此随机写操作会受到很大的影响。但是相应的,在单位面积内,可用的track更多,容量也就更大了。Shingled magnetic Recording磁盘是将一定数量的track组成固定大小的band。Band之间由gap隔开,避免写相互影响。
为了满足SMR磁盘与现有的系统相互兼容的目的,在SMR设备和host之间,提出了 Shingle Translation Layer(STL)。STL可以将随机写转换成顺序写,并且对于主机来说提供标准的接口。这使得SMR设备能够在传统的HDDs上得到应用,实现与现有的磁盘系统很好的兼容的目的。这种方式下就提出了第一种SMR结构,drive-managed SMR。其整体结构如下图所示。
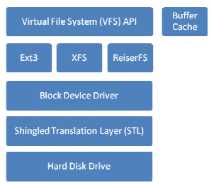
但是,随着数据量的变大,STL上的垃圾回收策略,映射方式策略使得STL变得越来越复杂,严重的影响了磁盘的整体性能。因此又提出了第二种SMR结构系统,host-managed SMR。这种方式将STL所做的工作全部都交给SMR-aware 文件系统,各种针对SMR磁盘的性能优化都放在host中实现。其整体的结构如下图所示。
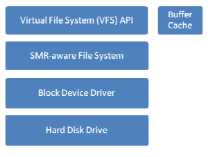
为了使得SMR磁盘能够在市场上得到广泛的应用,标准组织针对SMR提出了Zoned Block Commands (ZBC)和Zoned-device ATA Commands (ZAC)标准[13]。为区域块设备设立标准通信协议,人们提出了新的标准化方法。ZBC是为了满足SCSI设备的需求。这些标准是由T10组织设立的,而ZAC则是为了满足ATA设备的需求,由T13组织设立。
ZAC和ZBC命令标准既包含了drive-managed设备,也包含了host-managed设备。SMR设备是在最近几年最有可能代替传统的HDD市场的设备。如果没有ZAC和ZBC标准的支持,则SMR磁盘不能与传统的文件系统相互兼容。这会极大的影响SMR磁盘的应用和推广。
接下来,本文的第二部分将介绍基于host-managed SMR磁盘上固定band大小的应用。包括SMR-aware 文件系统SMRDB,HiSMRfs,以及类似于日志文件系统的strict-append文件系统。在本文的第三部分将介绍基于host-managed SMR磁盘上不固定大小的磁盘应用——caveat scriptor。而在本文的第四部分介绍和对比分析基于drive-managed SMR磁盘上的STL策略。最后总述SMR磁盘的现阶段成果和研究状态,分析SMR磁盘系统可能的研究方向。
SMR磁盘相对于传统磁盘而言,有相同的读性能。但是随机写和原地址数据更新却没有传统磁盘的性能好了。鉴于SMR磁盘在写行为上的改变,作者认为最好的利用SMR的方式并不是想传统磁盘那样去使用它,而是充分利用该磁盘顺序写的特性。因而开发了SMRDB这种key-value的数据存储方式[10]。表明SMR磁盘能够在众多应用上高效的代替传统磁盘。
SMRDB 是应用在SMR磁盘上的key-value数据库引擎。SMRDB能够对传统磁盘兼容,并且能够提供更好的性能。它设计部署在host-managed SMR磁盘上,并且并不依赖文件系统,而是直接运行在磁盘上。SMRDB消除了对block-level 驱动管理的的SMR磁盘的解决办法和新的SMR文件系统的依赖。
SMRDB被设计成数据库引擎,拥有自己的数据读取方式和存储管理。直接运行在host-managed SMR磁盘上而不需要任何的磁盘重映射方式。SMRDB可以被用作单独的数据库引擎,或者已存在的文件系统在SMR磁盘上能够使用它来存储固定大小的键值对。
2.1.1 数据的读取与管理
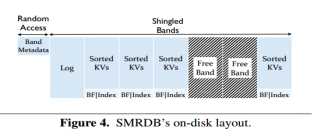
SMRDB不需要磁盘固件提供任何的数据管理,只是将磁盘band分成小的随机读取空间和固定大小的瓦band。随机读取区域被用于读取高层的瓦片band信息。而不是具体的key元数据。KV对和相关联的元数据都存储在瓦片类型的band中。
2.1.2 数据读取操作
SMRDB提供了自己的GET/PUT/DELETE/SCAN操作。Put操作是首先把数据以字典形式存放到mentable中。当数据量达到一定阈值之后,一起flush到空白的瓦片band中去。Delete操作是对于要删除的数据插入一个tombstone 词条,这样使得数据无效化,一段时间后后台执行清理操作释放空间。Get操作首先在内存里面检查关键字,如果没有再在band上查找key值。Scan操作直接查找index值,找到对应的关键字,再定位对于的值。
2.1.3 后台操作
SMRDB后台的操作主要包括以下几个方面的内容。Band的组织形式,数据的compaction方式,level0/level1层的band选择,还有冷热数据的分离方式。SMRDB的数据组织结构是两层的,每层都允许有重复的key值。第一层存放的是从内存中memtable dump下来的数据。第二层则是存放的基本有序的数据。当第一层的数据量达到一定的阈值之后,会存放到第二层,在此期间执行compaction操作。是的第二层存放的数据是基本有序且不重复。Compaction操作是将有重叠部分的band进行分解,得到多个band,再根据自己定义的顺序度量标准存放。第一层数据用于compaction操作,进行重复数据的删除,第二层数据选择的准则是尽量减少数据移动操作。最后一个冷热数据的分离,SMRDB采用延时cleaning的方法,上层保留热数据,下层保留冷数据。
HiSMRfs是在SMRfs的基础之上,为了进一步的提高SMRfs的性能而提出的一些改进的方法[12]。与SMRfs的主要区别是,HiSMRfs实现了基于内存的元数据树结构和hash表,目的是为了加速在目录上的元数据的查找。而SMRfs则是使用传统文件系统中的链式文件来存储元数据。除此之外,SMRFS需要一个临时的文件系统作为读写的缓冲区,当文件被打开,整个文件都需要背拷贝到临时文件系统,而HISMRfs则是采用文件命令队列和调度器实现的,这样能够大大的提高系统性能表现。除此之外,因为元数据比较小,而且读写比较频繁,这样HiSMRfs的针对SMRFS的设计显然会有比较好的性能优化。
HiSMRfs是一种运行在SMR磁盘上的文件系统,能够在没有重映射层的情况下管理SMR磁盘和支持随机写操作。为了达到比较好的性能,HiSMRfs分离了元数据和文件数据,并且分开管理它们。
HiSMRfs提供给应用程序标准的可移植操作系统接口。使用元数据管理模块和文件数据管理块通过设备的读写接口直接分别在磁盘的unshingled部分和shingled部分管理元数据和文件数据。并且使用File Caching and Placement 模块依据文件大小和读取频次来辨别和分离热数据和冷数据并且将数据存放在不同类型的磁盘上。使用树结构的元数据管理模块,并且使用哈希表来加快文件的查询。在文件数据管理模块中实现了四个主要的模块,分别是文件数据分配模块,垃圾回收模块,需求队列调度模块以及band layout模块。HiSMRfs中的RAID 模块则是实现在文件系统层面的,并且提供了良好的容错性能。
2.2.1 HISMRfs的组织结构
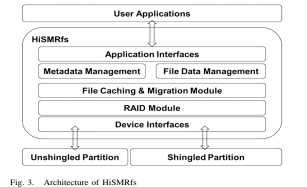
从图中容易看出HiSMRfs由6个部分组成,分别是应用接口,元数据管理模块,文件数据管理模块,文件缓存,规约模块,RAID模块以及设备接口。元数据管理模块采用树型结构,每个节点存储元数据信息,各节点之间采用父指针,孩子指针以及邻居指针相连接,最重要的是,管理模块才用了hash表的结构,加快了在文件目录中目标数据的查找速度。另外对于元数据的操作都会被时间戳记录在日志文件中,并且存储在非瓦片磁盘上。文件数据的管理模块又分成四个部分,分别是文件数据分配模块,垃圾回收模块,需求队列调度模块以及band/zone布局模块。文件数据分配模块决定数据写的位置。需求队列调度模块高效的调度文件的读写需求以获取更高的文件系统利用率和性能表现。垃圾回收模块则负责回收被释放的空间,在HiSMRfs中,提供了两种垃圾回收方式,一种是基于文件的,一种是基于band的。基于文件的是在空余的地方顺序写,而释放原文件空间。基于band的则是将有用数据重新写在新的band中,释放原来的band。
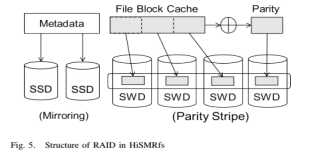
2.2.2 RAID模块。
相对于传统的RAID系统是在block层面实现的,HiSMRfs则是在文件层实现RAID的功能的。因而HISMRfs能够工作在一系列SMR存储设备上。一次同时,它还提供了很好的容错性。通过文件系统信息的反馈,HISMRfs能够进一步的在错误发生和设备出错方面有更好的性能表现。RAID整体结构如下图所示。
Strict append 是一种类似于日志文件系统的文件管理方式,其整体的结构如下图所示。
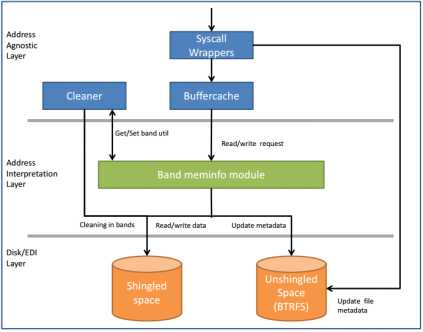
在strict append中,SMR磁盘会被分成多个band,每个band的大小都是固定的。此外,每个band都有一个写指针用于新数据的尾部添加。如果band中没有任何的有用的数据,写指针就会重置到band的开头,用于接受新的数据写入。
Strict append SMRfs是基于用户空间的文件系统,整个文件系统的工作流程如上图所示[25]。分为地址隐藏层,地址解释层以及磁盘层。在地址隐藏层包括系统调用模块,buffercache,以及cleaner这三个部分。系统调用模块接受上层用户提交的命令,对相应的做出指导,可以直接更新磁盘层的文件元数据,也可以将命令传递给buffercache。所有的读写操作的文件对象都是放在大小为2GB的buffercache中,然后再将读写命令传递给地址解释层的 band meminfo 模块。Band meminfo模块保留有磁盘的信息,它决定数据写的磁盘位置。根据数据的不同,存放到磁盘层的不同位置,unshingled的部分存放的是文件的元数据,shingled部分则是存放的是实际的文件数据 。任何一个文件会依据band id号,band内的偏移量,以及文件的block号这三个量来唯一的确定文件所处的位置。当数据量到达一定的阈值之后,则需要使用cleaning机制来对磁盘进行清理了。
当文件系统达到之前定义的容量阈值之后,会引发cleaning机制。垃圾回收线程会释放那些可能含有部分有效数据的band。Cleaning通过将需要清除的band中的有用数据移到新的band中,并且将该band的写指针重新指向band的开头部分,以此来达到清除band和释放band空间的效果。同时,垃圾回收线程还会根据新文件的地址更改inode的结构。Cleaning的效果会被很多的因素影响,不同的cleaning策略也有不同的cleaning代价。
由于SMR磁盘记录会对下游的数据产生影响,这样虽然增加了单位空间内的磁盘容量,但是也造成了随机写的不方便。Caveat scriptor则是在利用了传统磁盘地址空间上提出了几个磁盘参数[23][24],能够有效的避免上游数据的写操作对下有数据的影响,能够有效的实现SMR磁盘的随机写功能。
每一个LBA都有两个明显的参数:No overlap range 和isolation distance。No overlap range是连续的不重复写的LBA的最小距离;isolation distance是可能存在重叠的LBA中的最大距离,如下图所示
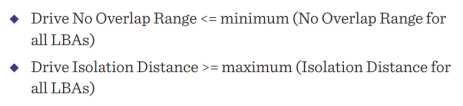
在给定的caveat scriptor模式中,所有的都有相同的DNOR和DID值,也就是caveat scriptor选择DNOR足够小,DID足够大以满足所有的磁盘。如下图所示
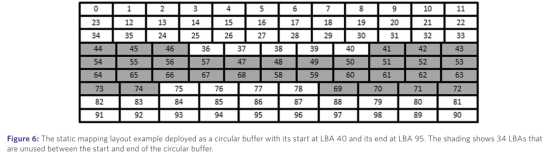
在上图中,DNOR的大小是7,DID的大小是34.我们根据上述两个参数在磁盘上可以得到磁盘的随机写区域和顺序写区域。band的大小小于DNOR能够得到一个随机的写band,因为LBA都被DID LBAs充分的隔开了,任何在随机写band上的数据不会因为其他块数据的写而对原来写入的数据产生影响。而对于顺序写区域,在磁盘上,上下游都充分的被DID隔开的band能够作为顺序写的band,在这样的band中,没有LBA 会被不同的band中的LBA重叠破坏。
参数DID和DNOR满足这样的大小关系 0<=DNOR<=DID。当从区域i到j进行写操作的时候,从max(i+1+DNOR,j+1)到(j + DID)的区域可能被损害。而实际上损害的区域依赖于块的数量,track上写的位置以及track在磁盘上的布局。那么在SMR磁盘上是怎样利用caveat-scriptor实现随机写和顺序写的呢?使用不大于DNOR的块,在这些块的上下游都使用长度为DID的块隔开,这样在长度不大于DNOR的区域内可以执行随机写而不会对下游的数据产生影响。顺序写则是对于任意大小的块,在顺序写区域的上游和下游都放置DID大小的控制块,这样就不仅可以实现顺序写,也可以不影响其他区域的随机写。
SMR磁盘的稳定随机写性能和更新在磁盘的应用上显得十分重要,为了更好地让SMR取代现存的磁盘并得到广泛应用,不得不从它们出发进行考虑和设计。
对SMR来说,在磁盘的盘片上的磁道以瓦片的排布方式被组织[14],使得它的存储密度增加,但是写磁头定位到一个磁道上比其他标准磁盘显得很大,也就是说写磁头横跨的磁道数目由标准磁盘的一个变成多个,当在一个磁道上进行写操作时,可能会影响相邻磁道上的数据。如下图

对bands进行设计,bands由在同一盘片上的连续tracks组成[15],即一个band包含几个连续的tracks。磁盘上的所有数据都存储在bands上,相邻的bands之间有k(k的大小由写磁头的宽度决定)个空tracks,作为两个bands的安全间隙。Bands的组成不采用同一柱面的tracks,是因为同一柱面的tracks之间的切换,经过盘片间的切换后,磁头还需要寻找到相应磁道,这样会增加磁盘系统的开销,使得其性能降低。
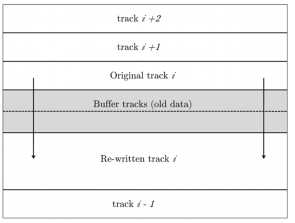
为了解决SMR随机写的问题,David Hall等人开发了一个数据处理算法[16] 即SMR短块算法(short-block SMR algorithm),该算法涉及到了两个布局:I-region和E-region;主要的存储数据安排I-region上, 在I-region中包含额外tracks,这些额外的tracks一部分用作refresh buffer,用来缓冲旧的数据;另一部分作为相邻两个I-region的guard tracks,如图2所示。 E-region用来接收从主机来的写请求操作,通过对这两个region分别进行合理的组织安排,可使得SMR能够维持稳定的随机写性能。首先将请求的写操作暂存在E-region中,给E-region一个合适的清理速率,目的是为E-region接收新的写操作提供充足的空间,使之持续稳定的接收写操作,在对E-region执行清理机制操作时,会引发后台的刷新操作,在I-region相关联的位置开始进行读操作,old data被读到I-region的buffer tracks当中;读操作完成后,把从E-region读出来的写操作写入到I-region的相应位置中,并将old data重写到原来的位置,在I-region的tracks上写的方式是顺序的,当数据更新完成后,E-region中对应的写操作将被清除。
当写块大小小于4时使用这种算法的稳定随机写性能比标准HDD好,超过了这个值性能就开始下降。
为了降低随机写造成的写操作次数,延长写块的长度,又提出了一个贪婪算发:给任意初始状态和一个逻辑track去更新k,选择一个使得写数目最小的作为终态,如果这样的终态不止一个,选择最集中的一个。一般说来,这个值接近N/2。
下图为给定的原始状态图,假定有三个状态,,tracks个数为4,写磁头的宽度为2,各个状态到达每个终态的写操作次数如图所示。状态1指向状态2,在外侧线上的1/2代表从第一个状态的第一个逻辑track到达终态2需要两次写操作,等等。
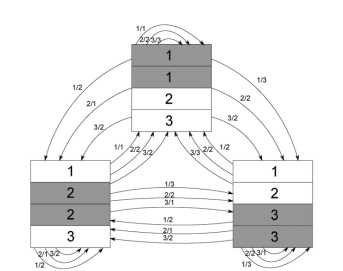
假设3个状态
使用贪婪算法,可以将上图简化成下图,以此达到减少平均写次数提高系统性能的目的。
该算法能够有效地降低随机写的平均次数。
实现数据更新的布局设计,数据更新有两种类型update out-of-place,update in-place。
在SMR中很少采用update out-of-place这种模式,update out-of-place采用了两个region(I-region和E-region),在此之前已经提到,这里不做详细说明。I-region和E-region构成了一个迂回系统[17],在执行更新操作时,将数据更新到新的地址块,原始的地址块变为无效;虽然可以避免写放大,但是E-region和I-region不得不执行垃圾收集(GC,Garbage Collection)操作来回收无效块和造成的碎片;由于将更新的数据更新到新的位置,逻辑块地址到物理块地址的映射表(LBA-to-PBA mapping table)也因此变得更加复杂。
SMR的更新采用Update in-pace这种模式[18][19],需要额外的预留空间用来缓冲数据,下图是SMR实现Update in-pace的布局图。
Physical Space Layout for In-place Update SMR
图的左侧是SMR的RAZ结构,相邻的RAZ track之间有k个空tracks(k的值由写磁头的大小决定),即把RAZ做成类似标准HDD的样式,不存在写放大问题。用于缓冲元数据。RAZ实现的两种策略分别为:①将非易失RAM(NVROM)附加到SMR作为一个专用RAZ②在SMR中,用单独的一个个bands组成专用region作为RAZ。在执行数据更新操作时,从mapping表中找到相关联的物理地址,把老数据读到缓冲区,再将老数据与新数据合并,最后在相应物理地址上写新数据,刷新老的数据。与update in-place 模式的不同之处是不需要GC(Garbage Collection)操作,mapping表相对较为简单。
通过前面的介绍,我们可知update in-place模式在提高SMR的性能方面优越于update out-of-place模式,但是update in-place实现需要预留额外的空间,因此为了达到空间与性能平衡,对mapping进行改进设计。
逻辑块地址到物理块地址的映射表(LBA-to-PBA mapping table)的改进。逻辑块地址(LBA,Logical Block Address)到物理块地址(PBA,Physical Block Address)映射的设计也是SMR的重要部分。
通过前面的介绍,我们可知update in-place模式在提高SMR的性能方面优越于update out-of-place模式,因此对mapping的改进设计也是基于update in-place模式。
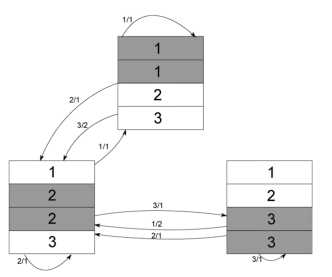
假设普通磁盘和SMRs的tracks 组织方式一样,每个band包含4个tracks,写磁头的宽度为2,band之间有一个空track作为安全隔离带,采用的映射机制依旧为传统的标准磁盘的映射机制,则有[1-100]对应第一个track,[101-200]对应第二个track, [201-300]对应第三个track等等。SMR磁盘的利用率为4/(4+1)=0.8,实际磁盘空间用SG表示,在SMR上执行一次更新可能会招致额外的读和写。如图所示(one band),更新a 会招致2次读,3次写,即写放大问题,写放大计算用WAR (Write Amplification Ratio)表示,SG和WAR的计算如下(N代表磁盘的band包含的tracks数目,W为写磁头的宽度,i的取值为0-(N-1)[20]。
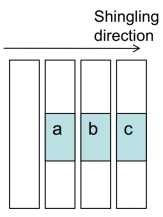
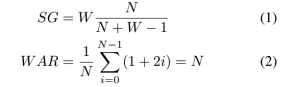
如果改变tracks的使用顺序使得减少写放大问题变得可行,于是,就可以对逻辑块地址到物理块地址的映射表(LBA-to-PBA mapping table)进行改进,来实现tracks使用顺序的改变。
于是就有3种不同的方案。
第一种方案,当SMR使用容量低于25%时,数据依次存储在磁盘的每个band的第一个或第四个track上;随着磁盘的使用容量增加,低于50%是将增加的数据依次存储在磁盘的每个band的第四个或第一个track;当磁盘使用容量增加低于75%时,增加的数据依次存储到磁盘的每个band的第二个track;随着磁盘使用容量的继续增加,增加的数据存储到第三个track。表现在映射表中为:将磁盘上每个band上的tracks进行分组(即first track,second track,third track,fourth track),首先连续映射全部的fourth track或者first track,其次连续映射first track或fourth track,接着连续映射second track,最后映射third track。该方案记作R(4123)或R(1423)
第二种方案,当SMR使用容量低于50%时,数据依次存储在磁盘的每个band的第一个和第四个track上(即存储完第一个band的第一和第四tracks,再存储第二个band的第一和第四tracks,依次类推);当磁盘使用容量增加低于75%时,增加的数据依次存储到磁盘的每个band的第二个track;随着磁盘使用容量的继续增加,增加的数据存储到第三个track。表现在映射表中为:将磁盘上每个band上的tracks进行分组(即first track and fourth track,second track,third track),首先将每个band的第一和第四track依次排列进行连续映射,其次连续映射second track,最后映射third track。该方案记作14R(23)
第三种方案,当SMR使用容量低于75%时,数据依次存储在磁盘的每个band的第一个、第二和第四个track上(即存储完第一个band的第一、第二和第四tracks,再存储第二个band的第一、第二和第四tracks,依次类推);随着磁盘使用容量的继续增加,增加的数据存储到第三个track。表现在映射表中为:将磁盘上每个band上的tracks进行分组(即first track and fourth track,second track,third track),首先将每个band的第一、第二和第四track依次排列进行连续映射,其次连续映射second track,最后映射third track。该方案记作124R(3)
这样三种mapping方案,当磁盘使用容量低于50%方案一和方案二使得磁盘性能较好,整体来看第一种方案最好。
Band的清理机制,对于bands的清理机制的基本布局有两种[18][19]。第一种布局:每个band都附有一个循环日志,通过从日志的尾部到日志的头部移动实时数据来回收自由空间;第二种布局:通过压缩一个或几个完整的bands,将数据存放到少数几个空的band,并将压缩的bands清空释放出来。

循环日志结构在band在中的组织安排如下图所示。循环日志包含日志头部和日志尾部日志头部和日志尾部之间有个安全隔离带,由k个空tracks组成(k由写磁头的宽度决定)为了防止在头部进行写操作破坏尾部数据。
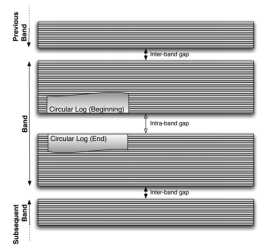
Layout in a Band with Circular Log
为了使band的清理机制的效率更高,系统开销降低,使得系统的响应能力得到提高提出了一种数据分类算法[20]。
该算法基于清理机制的第二种布局提出来的,band的清理机制会产生数据的移动,为了降低执行band清理操作导致的数据移动,主要将数据分成三类[20][21],即free blocks, cold blocks, hot blocks。这样分类的原因是:cold blocks与hot blocks相比,选择精简压缩hot blocks越少,数据移动的量越少(压缩hot blocks的意义很小,这里不考虑对hot blocks的压缩); cold blacks与 free blocks相比,cold blacks选择压缩的权重小于free blocks时进行压缩产生的数据移动量会减少。由此产生了cold-weight算法,算法推倒如下:
首先,%free + %cold + %hot = 1
当分别给hot blocks和cold blocks一个whot ,wcold则有:
%free + (wcold × %cold) + (whot × %hot)
将%hot替换掉,可以得到:
%free + (wcold × %cold) + (whot × (1 - %free - %cold))
最右面的式子展开
%free + (wcold × %cold) + whot - (whot × %free) - (whot ×%cold)
由以上分析将whot视作常量对待,忽略不计,合并相同的项。
%free × (1 - whot) + %cold× (wcold - whot)
除以(1 - whot)
%free + %cold × (wcold - whot)/(1 - whot )
将whot视作0,该公式变为:%free + %cold ×wcold
于是Cold-weight算法为当执行band compaction前,由公式计算出的每个band的值,选出所规定数目的几个值最大的bands,进行清理压缩。
假设有三个数据段,如图,每次只清理压缩一个数据段,此时free blocks和cold blocks的权重相同(cold blocks没设权重),由公式可知选择的压缩的数据段为第一个数据段,不是期望的结果
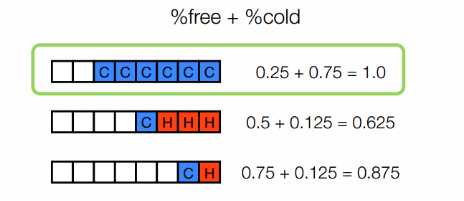
如果将cold blocks的权重设为0.5,如下图所示。有公式计算可得,选择清理压缩的数据段是第三个数据段,是期望的结果。

因此该算法可以减少数据移动,使得band压缩效率更高,同时也提高了系统的响应能力。
整个SMR磁盘的研究方向主要是集中在两个方面,一个是在实现与传统系统的兼容的情况下,如何尽可能的提高SMR磁盘随机写的性能表现。我们在文中提到的各种 STL层的策略,包括数据的组织形式,映射方法以及对数据的清理策略都是围绕这一目的来设计和实现的。当然也包括各种host-managed上的各式各样的SMR-friendly文件系统的设计和改进等,也都是为了达到在固定大小的band情况下的良好的随机写性能表现。而另一个方面则是一种比较新颖的方式,选择不固定大小的band,根据磁盘自身的布局特点,定义参数DID和DNOR来克服SMR磁盘自身会对下游数据写覆盖的缺点,实现SMR磁盘的良好的随机写性能。
现有的ZAC,ZBC已经开始定义和设计实现SMR磁盘的标准。未来可能的研究方向还是集中在具体的不同领域上使得SMR磁盘更好的满足在具体领域的使用。
标签:
原文地址:http://www.cnblogs.com/tao-alex/p/5818477.html