标签:
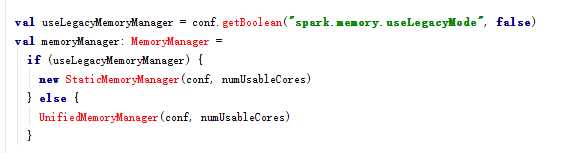
Spark 作为一个以擅长内存计算为优势的计算引擎,内存管理方案是其非常重要的模块; Spark的内存可以大体归为两类:execution和storage,前者包括shuffles、joins、sorts和aggregations所需内存,后者包括cache和节点间数据传输所需内存;在Spark 1.5和之前版本里,两者是静态配置的,不支持借用,spark1.6 对内存管理模块进行了优化,通过内存空间的融合,消除以上限制,提供更好的性能。官方网站只是要求内存在8GB之上即可(Impala推荐要求机器配置在128GB), 但spark job运行效率主要取决于:数据量大小,内存消耗,内核数(确定并发运行的task数量)
目录:
基本知识:
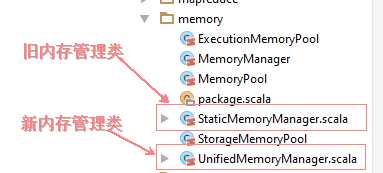
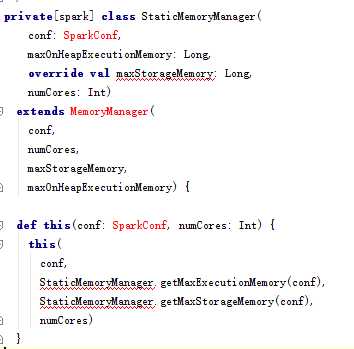
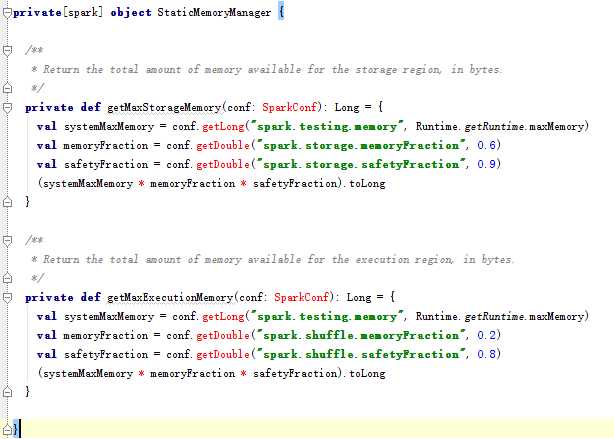
Spark1.5- 内存管理:
小结:
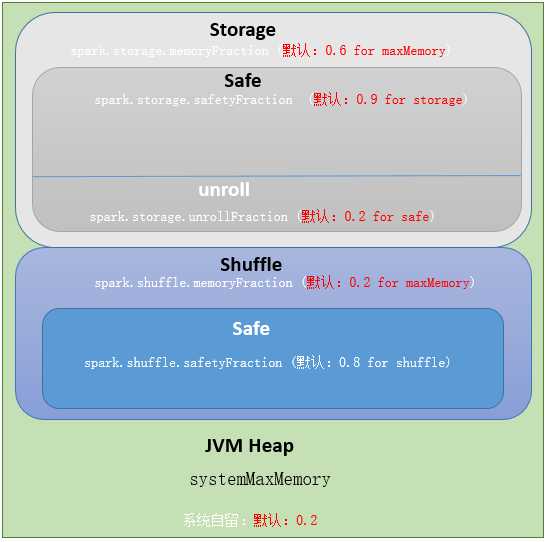
Spark1.6 内存管理:
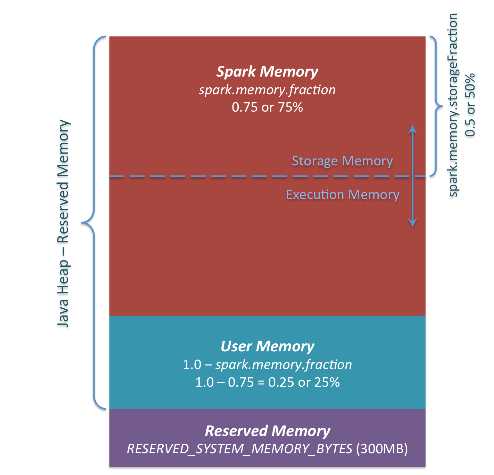
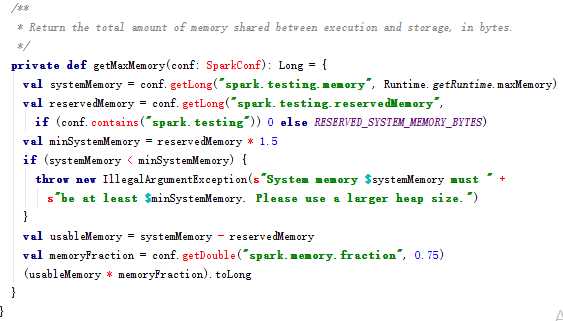
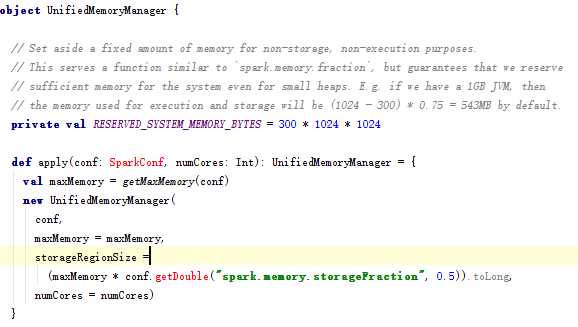
从spark1.6开始,引入了新的内存管理方式-----统一内存管理(UnifiedMemoryManager),在统一内存管理下,spark一个executor中的jvm heap内存被划分成如下图:
标签:
原文地址:http://www.cnblogs.com/tgzhu/p/5822370.html