标签:
深度学习有不少的trick,而且这些trick有时还挺管用的,所以,了解一些trick还是必要的。上篇说的normalization、initialization就是trick的一种,下面再总结一下自己看Deep Learning Summer School, Montreal 2016 总结的一些trick。请路过大牛指正~~~
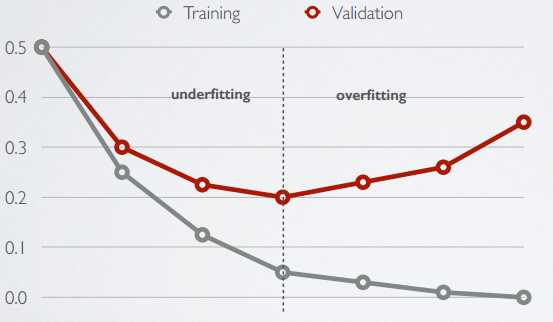
early stop
“早停止”很好理解,就是在validation的error开始上升之前,就把网络的训练停止了。说到这里,把数据集分成train、validation和test也算是一种trick吧。看一张图就明白了:
L1、L2 regularization
第一次接触正则化是在学习PRML的回归模型,那时还不太明白,现在可以详细讲讲其中的原理了。额~~~~(I will write the surplus of this article in English)
At the very outset, we take a insight on L1, L2 regularization. Assume the loss function of a linear regression model as 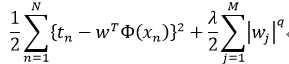 . In fact, L1, L2 regularization can be seen as introducing prior distribution for the parameters. Here, L1 regularization can be interpreted as Laplace prior, and Guass prior for L2 regularization.Such tricks are used to reduce the complexity of a model.
. In fact, L1, L2 regularization can be seen as introducing prior distribution for the parameters. Here, L1 regularization can be interpreted as Laplace prior, and Guass prior for L2 regularization.Such tricks are used to reduce the complexity of a model.
L2 regularization
As before, we make a hypothesis that the target variable 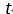 is determined by the function
is determined by the function  with an additive guass noise
with an additive guass noise 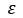 , resulting in
, resulting in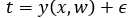 , where is a zero mean Guassian random variable with precision
, where is a zero mean Guassian random variable with precision 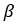 . Thus we know
. Thus we know 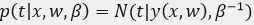 and its loglikelihood function form can be wrote as
and its loglikelihood function form can be wrote as

Finding the optimal solution for this problem is equal to minimize the least squre function ![]() . If a zero mean
. If a zero mean ![]() variance Guass prior is introduced for
variance Guass prior is introduced for 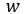 , we get the posterior distribution for from the function (need to know prior + likelihood = posterior)
, we get the posterior distribution for from the function (need to know prior + likelihood = posterior)

rewrite the equaltion in loglikelihood form, we will get

at the present, you see ![]() . This derivation process accounts for why L2 regularization could be interpreted as Guass Prior.
. This derivation process accounts for why L2 regularization could be interpreted as Guass Prior.
L1 regularization
Generally, solving the the L1 regularization is called LASSO problem, which will force some coefficients to zero thus create a sparse model. You can get reference from here.


From the above images(two-dimensionality), something can be discovered that for the L1 regularization, the interaction points always locate on the axis, and this will forces some of the variables to be zero. Addtionally, we can learn that L2 regularization doesn‘t produce a sparse model(the right side image).
Fine tuning
It‘s easy to understand fine tuning, which could be interpreted as a way to initailizes the weight parameters then proceed a supervised learning. Parameters value can be migrated from a well-trained network, such as ImageNet. However, sometimes you may need an autoencoder, which is an unsupervised learning method and seems not very popular now. An autoencoder will learn the latent structure of the data in hidden layers, whose input and output should be same.
In fact, supervised learning of fine tune just performs regular feed forward process as in a feed-forwad network.
Then, I want to show you an image about autoencoder, also you can get more information in detail through this website.
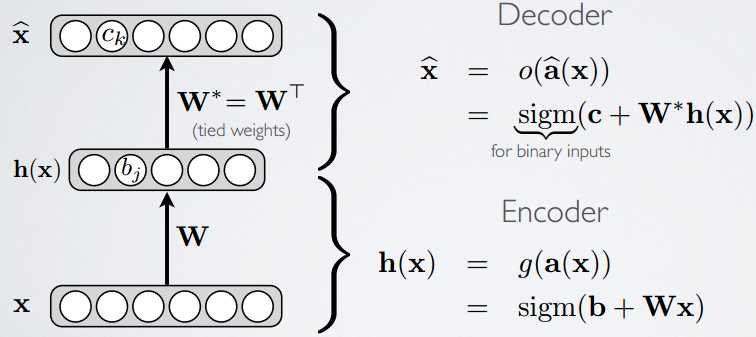
Data argumentation
If training data is not large enough, it‘s a neccessary to expand the data by fliping, transferring or rotating to avoid overfit. However, according to the paper "Visualizing and Understanding Convolutional Networks", CNN may not be as stable when fliping for image as transferring and rotating, except a symmetrical image.
Pooling
I have introduced why pooling works well in the ealier article in this blog, if interested, you may need patience to look through the catalogue. In the paper "Visualizing and Understanding Convolutional Networks", you will see pooling sometimes a good way to control the invariance, I want to write down my notes about this classical paper in next article.
Dropout and Drop layer
Dropout now has become a prevalent technique to prevent overfitting, proposed by Hinton, etc. The dropout program will inactivate some nodes according to a probability p, which has been fixed before training. It makes the network more thinner. But why does it works ? There may exist two main reasons, (1) for a batch of input data, nodes can be trained better in a thinner network, for they trained with more data in average. (2) dropout inject noise into network which will do help.
Inspired by dropout and ResNet, Huang, etc propose drop layer, which make use of the shortcut connection in ResNet. It will enforce the information flow through the shortcut connection directly and obstruct the normal way according to a probability p just like what dropout does. This technique makes the network shorter in training, and can be used to trained a deeper network even more than 1000 layers.
Depth is important
The chart below interprets the reason why depth is important,
as the number of layer increasing, the classification accuracy arises. While visualizing the feature extracted from layers using decovnet("Visualizing and Understanding Convolutional Networks"), the deeper layer the more abstract feature extracted. And abstract feature will strengthen the robustness, i.e. the invariance to transformation.
【CV知识学习】early stop、regularation、fine-tuning and some other trick to be known
标签:
原文地址:http://www.cnblogs.com/jie-dcai/p/5822333.html