标签:des style blog http color 使用 os io
2014-08-10
首先要注意的是cublas使用的是以列为主的存储方式,和c/c++中的以行为主的方式是不一样的。处理方法可参考下面的注释代码
// SOME PRECAUTIONS: // IF WE WANT TO CALCULATE ROW-MAJOR MATRIX MULTIPLY C = A * B, // WE JUST NEED CALL CUBLAS API IN A REVERSE ORDER: cublasSegemm(B, A)! // The reason is explained as follows: // CUBLAS library uses column-major storage, but C/C++ use row-major storage. // When passing the matrix pointer to CUBLAS, the memory layout alters from // row-major to column-major, which is equivalent to an implict transpose. // In the case of row-major C/C++ matrix A, B, and a simple matrix multiplication // C = A * B, we can‘t use the input order like cublasSgemm(A, B) because of // implict transpose. The actual result of cublasSegemm(A, B) is A(T) * B(T). // If col(A(T)) != row(B(T)), equal to row(A) != col(B), A(T) and B(T) are not // multipliable. Moreover, even if A(T) and B(T) are multipliable, the result C // is a column-based cublas matrix, which means C(T) in C/C++, we need extra // transpose code to convert it to a row-based C/C++ matrix. // To solve the problem, let‘s consider our desired result C, a row-major matrix. // In cublas format, it is C(T) actually (becuase of the implict transpose). // C = A * B, so C(T) = (A * B) (T) = B(T) * A(T). Cublas matrice B(T) and A(T) // happen to be C/C++ matrice B and A (still becuase of the implict transpose)! // We don‘t need extra transpose code, we only need alter the input order! // // CUBLAS provides high-performance matrix multiplication. // See also: // V. Volkov and J. Demmel, "Benchmarking GPUs to tune dense linear algebra," // in Proc. 2008 ACM/IEEE Conf. on Superconducting (SC ‘08), // Piscataway, NJ: IEEE Press, 2008, pp. Art. 31:1-11. //
小例子C++中:
A矩阵:0 3 5 B矩阵:1 1 1
0 0 4 1 1 1
1 0 0 1 1 1
现在要求C = A*B
C++中的结果
C矩阵:8 8 8
4 4 4
1 1 1
在cublas中:变成以行为主
A矩阵:0 0 1 B矩阵:1 1 1
3 0 0 1 1 1
5 4 0 1 1 1
在cublas中求C2=B*A
结果如下:C2在cublas中以列为主
惯性思维,先把结果用行为主存储好理解:
C2矩阵:8 4 1
8 4 1
8 4 1
在cublas实际是一列存储的,结果如下:
C2矩阵:8 8 8
4 4 4
1 1 1
此时在cublas中B*A的结果与C++中A*B结果一样,使用cublas时只需改变下参数的位置即可得到想要的结果。
cublas<t>gemm()
cublasStatus_t cublasSgemm(cublasHandle_t handle, cublasOperation_t transa, cublasOperation_t transb, intm, intn, intk, const float*alpha, const float*A, intlda, const float*B, intldb, const float*beta, float*C, intldc); cublasStatus_t cublasDgemm(cublasHandle_t handle, cublasOperation_t transa, cublasOperation_t transb, intm, intn, intk, const double*alpha, const double*A, intlda, const double*B, intldb, const double*beta, double*C, intldc); cublasStatus_t cublasCgemm(cublasHandle_t handle, cublasOperation_t transa, cublasOperation_t transb, intm, intn, intk, constcuComplex *alpha, constcuComplex *A, intlda, constcuComplex *B, intldb, constcuComplex *beta, cuComplex *C, intldc); cublasStatus_t cublasZgemm(cublasHandle_t handle, cublasOperation_t transa, cublasOperation_t transb, intm, intn, intk, constcuDoubleComplex *alpha, constcuDoubleComplex *A, intlda, constcuDoubleComplex *B, intldb, constcuDoubleComplex *beta, cuDoubleComplex *C, intldc);
参数含义可参考下面的信息:
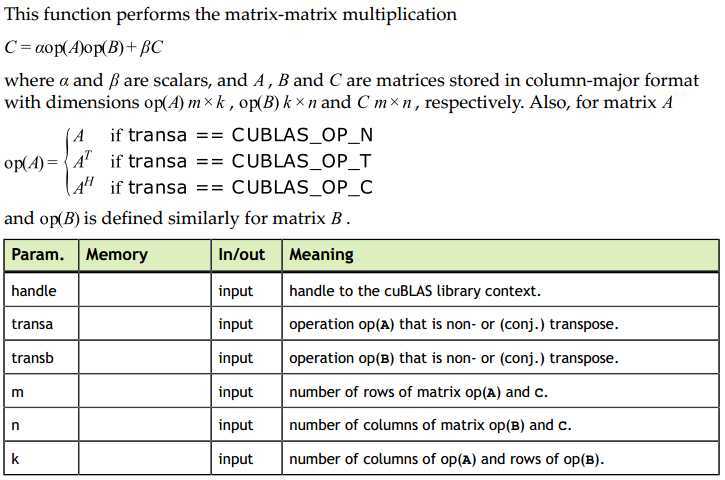
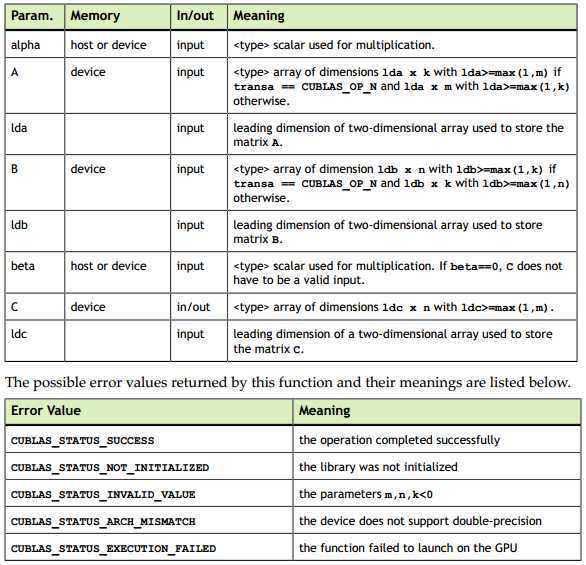
使用cublas中cublasSgemm实现简单的矩阵相乘代码如下:
头文件:matrix.h
1 // SOME PRECAUTIONS: 2 // IF WE WANT TO CALCULATE ROW-MAJOR MATRIX MULTIPLY C = A * B, 3 // WE JUST NEED CALL CUBLAS API IN A REVERSE ORDER: cublasSegemm(B, A)! 4 // The reason is explained as follows: 5 6 // CUBLAS library uses column-major storage, but C/C++ use row-major storage. 7 // When passing the matrix pointer to CUBLAS, the memory layout alters from 8 // row-major to column-major, which is equivalent to an implict transpose. 9 10 // In the case of row-major C/C++ matrix A, B, and a simple matrix multiplication 11 // C = A * B, we can‘t use the input order like cublasSgemm(A, B) because of 12 // implict transpose. The actual result of cublasSegemm(A, B) is A(T) * B(T). 13 // If col(A(T)) != row(B(T)), equal to row(A) != col(B), A(T) and B(T) are not 14 // multipliable. Moreover, even if A(T) and B(T) are multipliable, the result C 15 // is a column-based cublas matrix, which means C(T) in C/C++, we need extra 16 // transpose code to convert it to a row-based C/C++ matrix. 17 18 // To solve the problem, let‘s consider our desired result C, a row-major matrix. 19 // In cublas format, it is C(T) actually (becuase of the implict transpose). 20 // C = A * B, so C(T) = (A * B) (T) = B(T) * A(T). Cublas matrice B(T) and A(T) 21 // happen to be C/C++ matrice B and A (still becuase of the implict transpose)! 22 // We don‘t need extra transpose code, we only need alter the input order! 23 // 24 // CUBLAS provides high-performance matrix multiplication. 25 // See also: 26 // V. Volkov and J. Demmel, "Benchmarking GPUs to tune dense linear algebra," 27 // in Proc. 2008 ACM/IEEE Conf. on Superconducting (SC ‘08), 28 // Piscataway, NJ: IEEE Press, 2008, pp. Art. 31:1-11. 29 // 30 31 #include <stdio.h> 32 #include <stdlib.h> 33 34 //cuda runtime 35 #include <cuda_runtime.h> 36 #include <cublas_v2.h> 37 38 39 //包含的库 40 #pragma comment (lib,"cudart") 41 #pragma comment (lib,"cublas") 42 43 //使用这个宏就可以很方便的将我们习惯的行为主的数据转化为列为主的数据 44 //#define IDX2C(i,j,leading) (((j)*(leading))+(i)) 45 46 typedef struct _matrixSize // Optional Command-line multiplier for matrix sizes 47 { 48 unsigned int uiWA, uiHA, uiWB, uiHB, uiWC, uiHC; 49 } sMatrixSize; 50 51 cudaError_t matrixMultiply(float *h_C, const float *h_A, const float *h_B,int devID, sMatrixSize &matrix_size);
CPP文件:matrix.cpp
1 #include "matrix.h" 2 3 cudaError_t matrixMultiply(float *h_C, const float *h_A, const float *h_B,int devID, sMatrixSize &matrix_size){ 4 float *dev_A = NULL; 5 float *dev_B = NULL; 6 float *dev_C = NULL; 7 float *h_CUBLAS = NULL; 8 9 cudaDeviceProp devicePro; 10 cudaError_t cudaStatus; 11 12 cudaStatus = cudaGetDeviceProperties(&devicePro, devID); 13 14 if(cudaStatus != cudaSuccess){ 15 fprintf(stderr,"cudaGetDeviceProperties returned error code %d, line(%d)\n", cudaStatus, __LINE__); 16 goto Error; 17 } 18 19 // allocate device memory for matrices dev_A 、 dev_B and dev_C 20 unsigned int size_A = matrix_size.uiWA * matrix_size.uiHA; 21 unsigned int mem_size_A = sizeof(float) * size_A; 22 23 unsigned int size_B = matrix_size.uiWB * matrix_size.uiHB; 24 unsigned int mem_size_B = sizeof(float) * size_B; 25 26 unsigned int size_C = matrix_size.uiWC * matrix_size.uiHC; 27 unsigned int mem_size_C = sizeof(float) * size_C; 28 29 //cudaMalloc dev_A 30 cudaStatus = cudaMalloc( (void**)&dev_A, mem_size_A); 31 if(cudaStatus != cudaSuccess){ 32 fprintf(stderr, "cudaMalloc dev_A return error code %d, line(%d)\n", cudaStatus, __LINE__); 33 goto Error; 34 } 35 36 //cudaMalloc dev_B 37 cudaStatus = cudaMalloc( (void**)&dev_B, mem_size_B); 38 if(cudaStatus != cudaSuccess){ 39 fprintf(stderr, "cudaMalloc dev_B return error code %d, line(%d)\n", cudaStatus, __LINE__); 40 goto Error; 41 } 42 43 //cudaMalloc dev_C 44 cudaStatus = cudaMalloc( (void**)&dev_C, mem_size_C); 45 if(cudaStatus != cudaSuccess){ 46 fprintf(stderr, "cudaMalloc dev_C return error code %d, line(%d)\n", cudaStatus, __LINE__); 47 goto Error; 48 } 49 50 // allocate host memory for result matrices h_CUBLAS 51 h_CUBLAS = (float*)malloc(mem_size_C); 52 if( h_CUBLAS == NULL && size_C > 0){ 53 fprintf(stderr, "malloc h_CUBLAS error, line(%d)\n",__LINE__); 54 goto Error; 55 } 56 57 58 /* 59 copy the host input vector h_A, h_B in host memory 60 to the device input vector dev_A, dev_B in device memory 61 */ 62 63 //cudaMemcpy h_A to dev_A 64 cudaStatus = cudaMemcpy(dev_A, h_A, mem_size_A, cudaMemcpyHostToDevice); 65 if( cudaStatus != cudaSuccess){ 66 fprintf(stderr,"cudaMemcpy h_A to dev_A return error code %d, line(%d)", cudaStatus, __LINE__); 67 goto Error; 68 } 69 70 71 //cudaMemcpy h_B to dev_B 72 cudaStatus = cudaMemcpy(dev_B, h_B, mem_size_B, cudaMemcpyHostToDevice); 73 if( cudaStatus != cudaSuccess){ 74 fprintf(stderr,"cudaMemcpy h_B to dev_B returned error code %d, line(%d)", cudaStatus, __LINE__); 75 goto Error; 76 } 77 78 //CUBLAS version 2.0 79 { 80 cublasHandle_t handle; 81 cublasStatus_t ret; 82 83 ret = cublasCreate(&handle); 84 if(ret != CUBLAS_STATUS_SUCCESS){ 85 fprintf(stderr, "cublasSgemm returned error code %d, line(%d)", ret, __LINE__); 86 goto Error; 87 } 88 89 cudaEvent_t start; 90 cudaEvent_t stop; 91 92 cudaStatus = cudaEventCreate(&start); 93 if(cudaStatus != cudaSuccess){ 94 fprintf(stderr,"Falied to create start Event (error code %s)!\n",cudaGetErrorString( cudaStatus ) ); 95 goto Error; 96 } 97 98 cudaStatus = cudaEventCreate(&stop); 99 if(cudaStatus != cudaSuccess){ 100 fprintf(stderr,"Falied to create stop Event (error code %s)!\n",cudaGetErrorString( cudaStatus ) ); 101 goto Error; 102 } 103 104 //recode start event 105 cudaStatus = cudaEventRecord(start,NULL); 106 if(cudaStatus != cudaSuccess){ 107 fprintf(stderr,"Failed to record start event (error code %s)!\n",cudaGetErrorString( cudaStatus ) ); 108 goto Error; 109 } 110 111 //matrix multiple A*B, beceause matrix is column primary in cublas, so we can change the input 112 //order to B*A.the reason you can see the file matrix.h 113 114 float alpha = 1.0f; 115 float beta = 0.0f; 116 //ret = cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, matrix_size.uiHB, matrix_size.uiHA, matrix_size.uiWA, 117 //&alpha, dev_B, matrix_size.uiWB, dev_A, matrix_size.uiWA, &beta, dev_C, matrix_size.uiWA); 118 119 ret = cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, matrix_size.uiHA, matrix_size.uiHB, matrix_size.uiWB, 120 &alpha, dev_A, matrix_size.uiWA, dev_B, matrix_size.uiWB, &beta, dev_C, matrix_size.uiWB); 121 122 123 if(ret != CUBLAS_STATUS_SUCCESS){ 124 fprintf(stderr,"cublasSgemm returned error code %d, line(%d)\n", ret, __LINE__); 125 } 126 127 printf("cublasSgemm done.\n"); 128 129 //recode stop event 130 cudaStatus = cudaEventRecord(stop,NULL); 131 if(cudaStatus != cudaSuccess){ 132 fprintf(stderr,"Failed to record stop event (error code %s)!\n",cudaGetErrorString( cudaStatus ) ); 133 goto Error; 134 } 135 136 //wait for the stop event to complete 137 cudaStatus = cudaEventSynchronize(stop); 138 if(cudaStatus != cudaSuccess){ 139 fprintf(stderr,"Failed to synchronize on the stop event (error code %s)!\n", cudaGetErrorString( cudaStatus ) ); 140 goto Error; 141 } 142 143 float secTotal = 0.0f; 144 cudaStatus = cudaEventElapsedTime(&secTotal ,start, stop); 145 if(cudaStatus != cudaSuccess){ 146 fprintf(stderr,"Failed to get time elapsed between event (error code %s)!\n", cudaGetErrorString( cudaStatus ) ); 147 goto Error; 148 } 149 150 //copy result from device to host 151 cudaStatus = cudaMemcpy(h_CUBLAS, dev_C, mem_size_C, cudaMemcpyDeviceToHost); 152 if(cudaStatus != cudaSuccess){ 153 fprintf(stderr,"cudaMemcpy dev_C to h_CUBLAS error code %d, line(%d)!\n", cudaStatus, __LINE__); 154 goto Error; 155 } 156 157 } 158 159 160 for(int i = 0; i < matrix_size.uiWC; i++){ 161 for(int j = 0; j < matrix_size.uiHC; j++){ 162 printf("%f ", h_CUBLAS[ i*matrix_size.uiWC + j]); 163 } 164 printf("\n"); 165 } 166 167 /* 168 //change the matrix from column primary to rows column primary 169 for(int i = 0; i<matrix_size.uiWC; i++){ 170 for(int j = 0; j<matrix_size.uiHC; j++){ 171 int at1 = IDX2C(i,j,matrix_size.uiWC); //element location in rows primary 172 int at2 = i*matrix_size.uiWC +j; //element location in column primary 173 if(at1 >= matrix_size.uiWC*matrix_size.uiHC || at2 >= matrix_size.uiWC*matrix_size.uiHC) 174 printf("transc error \n"); 175 h_C[ at1 ] = h_CUBLAS[ at2 ]; 176 } 177 } 178 */ 179 /* 180 for(int i = 0; i<matrix_size.uiWC; i++){ 181 for(int j = 0; j<matrix_size.uiHC; j++){ 182 //int at1 = IDX2C(i,j,matrix_size.uiWC); //element location in rows primary 183 int at2 = i*matrix_size.uiWC +j; //element location in column primary 184 //if(at1 >= matrix_size.uiWC*matrix_size.uiHC || at2 >= matrix_size.uiWC*matrix_size.uiHC) 185 //printf("transc error \n"); 186 h_C[ at2 ] = h_CUBLAS[ at2 ]; 187 } 188 } 189 */ 190 191 Error: 192 cudaFree(dev_A); 193 cudaFree(dev_B); 194 cudaFree(dev_C); 195 free(h_CUBLAS); 196 dev_A = NULL; 197 dev_B = NULL; 198 dev_C = NULL; 199 h_CUBLAS = NULL; 200 return cudaStatus; 201 } 202 203 204 205 206 cudaError_t reduceEdge(){ 207 cudaError_t cudaStatus = cudaSuccess; 208 Error: 209 return cudaStatus; 210 }
使用cublas 矩阵库函数实现矩阵相乘,布布扣,bubuko.com
标签:des style blog http color 使用 os io
原文地址:http://www.cnblogs.com/243864952blogs/p/3903247.html