标签:style blog http 使用 os io strong 数据
——谨将此文献给阿瑞(@Nyanko君一生懸命)和湛卢。阿瑞在MapReduce等方面提供的技术支持,使我们成为最早充分利用ODPS的团队之一;湛卢提出很多分析问题的新思路,让我们在走投无路的时候屡次重拾希望。
这个系列的几篇文章,记录我们队对于问题的整个处理过程。分成两个部分:首先的这一篇,记录我们分析问题的思路,以及由此建立的特征体系,模型的选择和融合;下一篇(也许会有),总结一下top10团队的做法(这个必须要等到8月20日他们答辩以后了)。
这个系列的文章重点围绕电商数据分析。尽管阿里放出的数据字段不多,有人谓之“小气”(你如何看待今年的阿里巴巴大数据竞赛?),仍然可以从中挖掘出业务信息和行为模式,给有志于网站分析,尤其是电商网站分析的同学提供一些思路。
此外,由于我的水平有限,无法面面俱到,有两个方面不做介绍:一是ODPS平台的具体使用(MR、XLab),二是某种算法的具体实现及详细原理(所以基本不会有数学公式:-D)。不涉及平台的使用,是为了没参赛的同学也能看得下去;不讲算法的详细原理,但会用一些直观的形式说一下自己的理解。
最后,本文来自南京大学“非基向量”团队的工作,由@且行且析YX执笔,转载请注明出处:http://www.cnblogs.com/qxqx/p/3903222.html。
开放数据:天猫用户在4月-8月的品牌行为数据,对品牌的点击、购买、收藏、加入购物车等。(一共5个月的数据)
预测数据:同样这些用户在9月购买的品牌。
提供的数据形式如下:
具体内容,请戳比赛介绍。
在阿里内部,天猫算法团队将品牌推荐转化为一个点击率预估问题。(注意:这里讨论推荐的目标是为用户展示之后用户会去点击,但是比赛要求的是预测用户是否去购买)
选取(USERi, BRANDj),即用户-品牌组合作为样本,对每个样本建立若干个特征f1/f2/f3…,是否点击作为因变量y(点击标记为1,未点击标记为0),最终对y进行预测得到点击的概率:
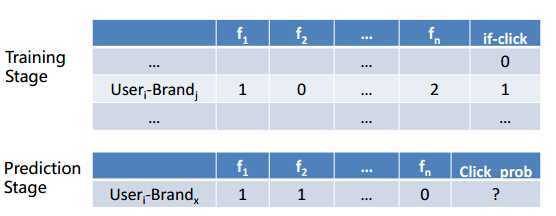
具体到点击率预估的模型上,使用Learning to Rank的算法,例如LR、Random Forest、GBDT。
上面的做法对于产生过交互的用户-品牌组合,无论是样本选取,还是特征抽取都比较容易,但是还要考虑挖掘从未发生交互的用户-品牌组合进行推荐。这部分“未知”的品牌推荐依靠基于Item的协同过滤:
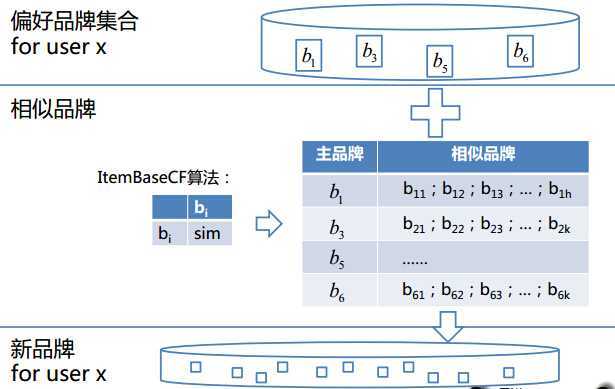
但凡学校里上过机器学习相关课程的同学,听到推荐系统之后,第一反应可能就是协同过滤。可是这里用协同过滤做的效果并不好,内部赛的冠军算者(@算者-闫新发)在论坛上提到了两点(夺冠感言:走进业务,提升对世界的认知能力),结合算者的观点和我的想法,可能的理由如下:
为什么天猫就可以利用协同过滤探索到未知的组合呢?其实上面提到的是点击率的预测,而点击和购买不同,无需考虑代价和需求问题。况且天猫内部必然掌握着更多的数据,多到足以让CF发挥作用。
此路不通,我们自然地想到要在有过交互的组合上做购买率预估。
训练集/预测集划分
训练集和预测集的划分如下:
|
|
X(特征提取) |
Y(label/prediction) |
|
训练集 |
1-92 |
93-123 |
|
预测集 |
1-123 |
?(下个月) |
即第1-92天的数据作为训练样本,并用来提取特征(X),93-123天的购买情况对前面的样本进行标记(购买的记1,未购买的记为0),在(X,Y)上预测得到购买率预测模型。然后用1-123天的数据作为预测样本,并用来提取特征,应用刚才得到的购买率预测模型,得到下个月的购买率。
这里其实存在一个问题,训练的模型是用前三个月预测第四个月,预测却是在前四个月的样本上预测第五个月的购买,这里的不一致性该如何解决?我们将在后面讨论这个问题。
每天只能提交一次,需要建立相应的线下测试框架:
|
|
X(特征提取) |
Y(label/prediction) |
|
训练集 |
1-61 |
62-92 |
|
预测集 |
1-92 |
?(93-123) |
即根据前三个月预测第四个月的效果,估计前四个月预测第五个月的效果。
按转化行为的样本划分
考虑购买和收藏行为的特殊性,再对数据所以下的划分,比较各自转化为下个月购买的效果:
|
数据划分 |
P |
R |
F1 |
|
最近三个月购买过的组合 |
1.86% |
5.58% |
2.79% |
|
最近三个月收藏(或购物车)且从没有购买过的组合 |
0.61%
|
0.97%
|
0.76%
|
|
最近三个月点击且从没有收藏(或购物车)或者购买过的组合 |
0.22%
|
12.88%
|
0.44%
|
购买的转化率是最高的,别忘记这是品牌推荐,在现有品牌能满足需求的前提下,用户不会太愿意承担购买新品牌的风险。而收藏的操作成本比点击要高,故用户对于这种品牌的喜好程度更高。至于纯粹的点击行为,则是最难准确预测的部分。
接下来将把全部的样本按照上面分成三类。这样划分的最早我们的准确率总是上不去,原因就是纯粹点击转化做的太差了,于是索性先把购买抽出来做好,后来每种转化途径的准确率都上去了,但是却沿袭了之前的这种样本划分。简单说,就是“历史遗留问题”。后来也没有比较过是不是所有样本放在一起,使用大量稀疏特征会更好(囧)。不过为了下面说明方便,请暂时接受这种划分的设定。
特征提取前的预处理:
特征工程重在做细、做实,因此如果在特征提取前不做预处理,个人实在无法接受。譬如考虑购买,很显然在最后一次购买后若干天之后又产生了点击,这里的点击和别的点击次数是不同的,它很有可能预示着一次新的购物行为的开始。因此这样的点击行为应该抽出来单独做成一个特征。而这种序列的提取,用MapReduce最容易实现。
我们组的特征数一直上不去,最终锁定在25-30,曾经接受@give学姐的建议,尝试将特征扩大到200维,可是效果也一直不好。特征提取是个考验细节工作的活,估计某个关键细节没做好。
所有的特征可以分成四大类,下面介绍每类特征的设计思路。
流量特征
流量,就是点击或购买等行为的次数。这也是唯一建立在用户-品牌组合上的特征(其他的特征都只是在用户或品牌的某一个维度上展开)。流量有两个特性,一是不同行为的重要性更不相同,二是按照时间衰减,短期的操作行为和购买的相关性最强。
有两种构造流量特征的方法可以让模型自动学习到时间权重,一种如下图所示:
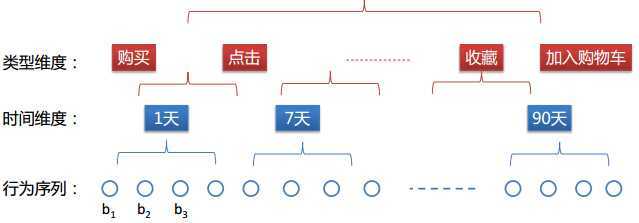
即最近一周点击次数、上周点击次数、上上周点击次数……
另一种描述方法是按照用户对品牌操作的行为序列进行描述,如最近一次点击次数、最近一次点击时间、最近倒数第二次点击次数、最近倒数第二次点击时间……
用户购买力/品牌销售量
反映用户的购买能力和某个品牌的销售情况。只取相关性最强的最后一个月数据。
时间间隔类特征
一种是转化间隔:某种行为经过多长时间可以转化为购买,例如用户将一个品牌加入收藏之后,倾向于过多长时间来购买这个品牌。反过来也可以在品牌维度上定义转化间隔类的特征。
另一类是反应用户在网站上的活跃度。例如用户回访天猫的平均时间间隔。
可以考虑的汇总指标有平均数和中位数,平均数的效果明显好于中位数。
转化率类特征
反映用户和品牌的某种操作转化为购买的比率。具体的算法可以分为按照次数和按照种类数计算的转化率。
如果只考虑用户单次购买行为的成功率,还可以定义跳出率特征(Bounce Rate)。由于缺少进一步的信息,取用户有操作的每天作为统计上线次数的单位,由此定义
跳出率=用户发生购买行为的天数/用户上线的总天数
Tree-based Models
阿里的算法工程师曾经做过一个分享《海量数据下的非线性模型探索》,提到在淘宝曾经有一个预测下一天ad的ctr的规则:

这个规则很简单,但是在很长时间里打败了各式各样的线性模型。
此外,在淘汰赛的小数据集上,很多同学都抱怨为什么自己研究了大半天的算法,反而比不上自己拍脑袋想出来的几条规则?
其实这都反映出来,线性模型无法很好地拟合数据。
相对的,基于决策树的算法Random Forest和GBDT在拟合效果上明显好于线性模型,同时两种方法通过集成学习的方式各自避免了过拟合,在数据集跑出了较高的成绩。
决策树的另一个优点是大多数特征不需要太多的后处理,特征选择的工作稍微做的马虎一点效果影响也不大。(我是说相对而言,如果想取得特别好的名次需要好好做特征选择)
Logistic Regression
LR则对特征的要求要“娇惯”得多,首先必须是线性相关的特征。但是有些特征就不是线性相关的,但是又的确对转化率会有影响,这时就需要做预处理了。我们用的处理方法是排序并分箱,从而得到一个偏线性的离散化的特征。
LR的另一个问题是它无法学到特征组合的知识,而有些信息只有通过特征间的组合才能表达出来。例如,比起用用户的购买力作为特征,考虑用户的购买力与这个品牌是否match要更加靠谱,对应的需要将特征进行组合,例如相乘或者相除。
最近在微博上看到很多人在讨论特征离散化的问题,据说,“在工业界,很少直接将连续值作为特征喂给逻辑回归模型,而是将连续特征离散化成一系列0、1特征,交给逻辑回归模型”,还有人特地将讨论的内容整理了一下,感兴趣的同学可以参考:特征离散化、特征组合以及线性模型的非线性基扩展。
训练中的抽样
这是一个不均衡的预测问题,如果我们把所有的负样本都交给算法,可能模型不管预测什么都是一个negative的结果,大大降低预测的准确度。因此,需要对负样本进行抽样。对于不同的数据划分,我们分别选择1:2、1:5、1:20,此时得到的结果比较均衡。
从数据出发
前面提到,在训练之前,负样本进行过抽样,因此得到的模型必然会偏向抽样出的数据。这种随机误差是由于统计抽样造成的,解决这个问题简单而有效的方法就是“多次测量取平均值”,即多次(一般4-5次即可)抽样,最后取多个模型预测的平均值。
这种融合方法可以使F1得分上升0.04%左右。
从模型出发
融合多个不同的模型,那么各个模型间的差异要尽可能大,因此这里以线性的LR和非线性的Random Forest来讲一下我们的融合方法。
在融合前期不妨用简答的加权求和看一下效果:
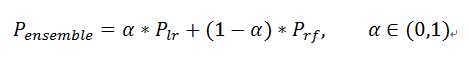
理想情况下,Random Forest可以较好地拟合数据,而LR则可以获得(线性)一致的结果,削弱某些离群点的表现,如下图所示(图片来自More Is Always Better: The Power Of Simple Ensembles):
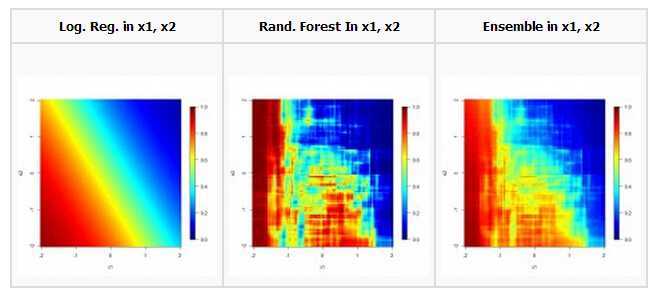
但是上面的两个分类器在使用之前还满足融合的另一个前提,那就是两种方法的效果不能相差太大。这个比赛中,LR的拟合效果完全比不上随机森林,但是随机森林,或者说决策树本身有一个缺点,即只是对历史行为的记忆,缺少推广性。
举例来说,我们的流量特征使用序列的表示方法,考虑特征last_click_date,即用户最后一次点击时间。使用Random Forest,模型实际在训练集上只学到这个特征为1-92时对应的知识,而在预测集上,最后一次点击时间很可能是100甚至更大(前面提到训练集划分产生的问题)。这个时候,随机森林只能把它当做92(训练集上这个特征最大的可能取值)来处理,从而当last_click_date取100和120的预测值是一样的,而事实上二者应该存在区别(尽管这个区别可能很小)。想一下LR的预测过程,你会发现LR就可以较好地处理外推问题。
总之,既然不能在全局上进行融合,就要在局部数据上进行融合。上面提到的此类样本在提交的结果集中约有5万条,在其上进行Random Forest和LR的融合之后,多命中了大约200条(泪,F1只提高了约0.01%)。
继续挣扎的Item-Based CF
起初基于Item的协同过滤是从“买了又买”(条件概率)入手,后来在这个基础上我们有考虑“买了不买”的行为。如果“买了又买”对应市场上的互补性商品,则“买了不买”则对应市场上的可替代品牌。例如用户在购买品牌A的那一天的只是点击了品牌B,那么A和B可能就是这种关系。
但是做出来的效果差得很远,如果有精确到秒的数据或许会好一些。
专攻辅助的Item-Based CF
按照协同过滤计算条件概率的公式,将这个预测评分也作为一个特征放入到购买率预测模型中,为有交互的组合提供辅助。结果看来,这种特征基本无效。
环比特征
主要从品牌入手,很多品牌可能具有季节性的销售特征。自然考虑到品牌销量的环比变化,结果发现相关性非常之低而且不稳定。或许是因为,时间序列分析无论哪种方法都只能做极短期的预测,一个月实在太长了。
动力学特征
简单说,就是用户从随便点点到确定购买之前,点击的频率(按天为单位)是一个匀加速,甚至加速度匀速增加的匀加速过程。做了一阶差分之后,发现这种行为特征不明显。其实,用户在购买前的各种不同日期点击品牌的行为本来就很少见,抽样上不去,规律自然不明显。
购物冲动在一周内的变化
以一周为周期,购物冲动在周三周四附近最强烈。这个结论未经验证,实际来自于比赛初期大家猜这是哪年数据来着。有人指出购物量较少的两天其实是周六、周日,由此反向推出某一天是周几,进一步推出这是哪一年。
我们组一番扯淡之后觉得,周一周二大家都比较忙,周末则活动太丰富(出去玩之类的),反而没时间精力网购,周三可能是一周最迷茫的时候(我实习的时候就有这种感觉),而且这个时候下单,刚好周末的时候能收到快递……你们信或者不信,反正我信了。
每日购买品牌和点击品牌之间的关系
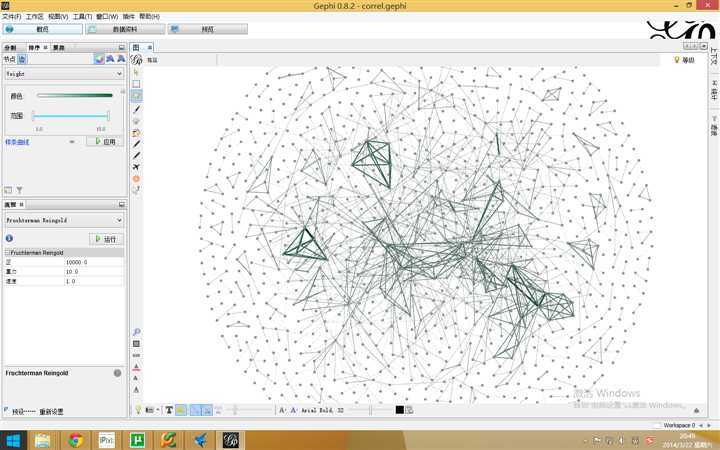
俗话说“货比三家不吃亏”,决定买一个品牌之前多比较一下总归是不错的,这也反映在多数人的购物行为上。下图中的各个顶点为品牌,边表示在购买其中一种品牌的当日也点击了另外一种品牌,边的权重为这种模式出现的次数。可以看到买到好的品牌都聚在图的中心一块,或者说用户会在畅销品牌之间纠结更多时间:
总的来说,整个比赛的工作量应该是80%的数据分析和特征工程,再加上20%的算法选择和融合。整篇总结也在前面着墨较多,希望可以为有志往数据分析方向发展的同学提供一些思路。但也只是一些思路,结论切勿盲目套用,具体问题仍应具体分析。
标签:style blog http 使用 os io strong 数据
原文地址:http://www.cnblogs.com/qxqx/p/3903222.html