标签:
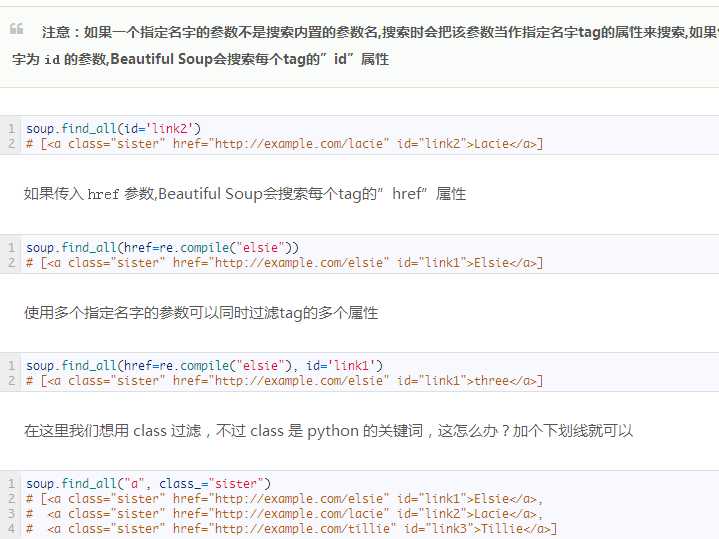
3.采用beatifulsoup与re正则表达式一起使,提取html中的一些href的链接
http://cuiqingcai.com/1319.html
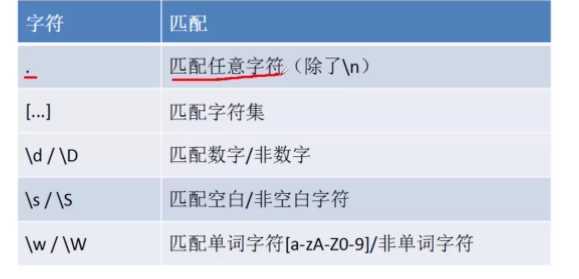
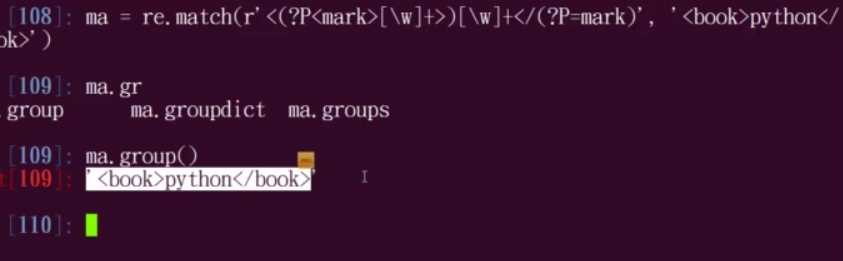
4.如何利用正则表达式边界匹配
爬虫(四):正则表达式(提取str中网址)
原文地址:http://www.cnblogs.com/woainifanfan/p/5775842.html