标签:
原文:http://caffe.berkeleyvision.org/tutorial/layers.html
参考:http://blog.csdn.net/u011762313/article/details/47361571#vision-layers
记:总感觉对于caffe是一知半解,要深入深度学习,以及更好的去工程和实验,详细学习caffe是必须的。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Vision layers 通常以图片images作为输入,运算后产生输出的也是图片images。对于图片而言,可能是单通道的(c=1),例如灰度图,或者三通道的 (c=3),例如RGB图。但是,对于Vision layers而言,最重要的特性是输入的spatial structure(空间结构)。2D的几何形状有助于输入处理,大部分的Vision layers工作是对于输入图片中的某一个区域做一个特定的处理,产生一个相应的输出。与此相反,其他大部分的layers会忽略输入的空间结构,而只是 将输入视为一个很大的向量,维度为: c*h*w。
可选:
输入(Input)
n * c_o * h_o * w_o,其中h_o = (h_i + 2 * pad_h - kernel_h) / stride_h + 1;w_o类似
例子(详见 ./examples/imagenet/imagenet_train_val.prototxt)
layer { name: "conv1" # 名称:conv1 type: "Convolution" # 类型:卷积层 bottom: "data" # 输入层:数据层 top: "conv1" # 输出层:卷积层1 # 滤波器(filters)的学习速率因子和衰减因子 param { lr_mult: 1 decay_mult: 1 } # 偏置项(biases)的学习速率因子和衰减因子 param { lr_mult: 2 decay_mult: 0 } convolution_param { num_output: 96 # 96个滤波器(filters) kernel_size: 11 # 每个滤波器(filters)大小为11*11 stride: 4 # 每次滤波间隔为4个像素 weight_filler { type: "gaussian" # 初始化高斯滤波器(Gaussian) std: 0.01 # 标准差为0.01, 均值默认为0 } bias_filler { type: "constant" # 初始化偏置项(bias)为零 value: 0 } } }
卷积层(The Convolution layer)利用一系列具有学习功能的滤波器(learnable filters)对输入的图像进行卷积操作,每一个滤波器(filter)对于一个特征(feature )会产生一个输出图像(output image)。
参数 (pooling_param):
输入(Input)
输出(Output)
例子(详见 ./examples/imagenet/imagenet_train_val.prototxt)
layer { name: "pool1" # 名称:pool1 type: "Pooling" # 类型:池化层 bottom: "conv1" # 输入层:卷积层conv1 top: "pool1" # 输出层:池化层pool1 pooling_param { pool: MAX # pool方法:MAX kernel_size: 3 # 每次pool区域为3*3像素大小 stride: 2 # pool步进为2 } }
LRN Layer对一个局部的输入区域进行归一化,有两种模式。ACROSS_CHANNELS模式,局部区域在相邻的channels之间拓展,不进行空间拓展,所以维度是local_size x 1 x 1。WITHIN_CHANNEL模式,局部区域进行空间拓展,但是是在不同的channels中,所以维度是1 x local_size x local_size。对于每一个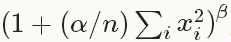 ,其中n是局部区域的大小,求和部分是对该输入值为中心的区域进行求和(必要时候可以补零)。
,其中n是局部区域的大小,求和部分是对该输入值为中心的区域进行求和(必要时候可以补零)。
Im2col 是一个helper方法,用于将图片文件image转化为列矩阵,详细的细节不需要过多的了解。在Caffe中进行卷积操作,做矩阵乘法时,会用到Im2col方法。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Caffe是通过最小化输出output与目标target之间的cost(loss)来驱动学习的。loss是由forward pass计算得出的,loss的gradient 是由backward pass计算得出的。
Softmax Loss Layer计算的是输入的多项式回归损失(multinomial logistic loss of the softmax of its inputs)。可以当作是将一个softmax layer和一个multinomial logistic loss layer连接起来,但是计算出的gradient更可靠。
Euclidean loss layer计算两个不同输入之间的平方差之和,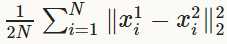
参数 (hinge_loss_param):
输入(Input)
输出(Output)
例子
# 使用L1范数 layer { name: "loss" # 名称:loss type: "HingeLoss" # 类型:HingeLoss bottom: "pred" # 输入:预测值 bottom: "label" # 输入:标签值 } # 使用L2范数 layer { name: "loss" # 名称:loss type: "HingeLoss" # 类型:HingeLoss bottom: "pred" # 输入:预测值 bottom: "label" # 输入:标签值 top: "loss" # 输出:loss值 hinge_loss_param { norm: L2 # 使用L2范数 } }
关于范数:

------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
激励层的操作都是element-wise的操作(针对每一个输入blob产生一个相同大小的输出):
参数 (relu_param):
例子(详见 ./examples/imagenet/imagenet_train_val.prototxt)
layer { name: "relu1" type: "ReLU" bottom: "conv1" top: "conv1" }
给定一个输入值x,ReLU layer的输出为:x > 0 ? x : negative_slope * x,如未给定参数negative_slope 的值,则为标准ReLU方法:max(x, 0)。ReLU layer支持in-place计算,输出会覆盖输入,以节省内存空间。
CUDA、GPU实现: ./src/caffe/layers/sigmoid_layer.cu
例子(详见 ./examples/mnist/mnist_autoencoder.prototxt)
layer { name: "encode1neuron" bottom: "encode1" top: "encode1neuron" type: "Sigmoid" }
对于每一个输入值x,Sigmoid layer的输出为sigmoid(x)。
标签:
原文地址:http://www.cnblogs.com/Allen-rg/p/5843078.html