标签:
1、XML是可扩展标记语言。是由W3C指定并维护的,目前最新的版本是1.0
2、XML作用:
2.1传输数据,它是一种通用的数据交换格式
2.2配置文件。
1、XML的声明
1.1语法:<?xml version="1.0" encoding="UTF-8"?>
保存在磁盘上的文件编码要与声明的编码一致。
encoding属性的默认 编码是:UTF-8
1.2XML的声明必须出现在XML文档的第一行
2、XML的注释
2.1语法:<!--这是注释-->
2.2注释不能出现在声明之前
3、CDATA区
CDATA是Character Data的缩写
把标签当做普通文本内容;
示例:
<![CDATA[
<itcast>www.itcast.cn</itcast>
]]>
4、特殊字符
& &
< <(less than)
> >(great than)
" "
‘ &'
5、引入css样式的命令
<?xml-stylesheeet type="text/css" href="type.css" ?>
·对中文命名的标签不起作用。
1、常用约束:DTD(Document Type Definition)文档类型定义
Schema
2、格式良好的XML:遵循XML语法的文档
有效的XML:遵守约束的文档。
有效的XML文档一定是格式良好的,但格式良好的不一定是有效的
3、单独的DTD文档在保存时要以【UTF-8编码】进行保存
4、编写DTD
4.1在XML文档中直接编写:
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE 书架 [
<!ELEMENT 书架 (书+)>
<!ELEMENT 书 (书名,作者,售价)>
<!ELEMENT 书名 (#PCDATA)>
<!ELEMENT 作者 (#PCDATA)>
<!ELEMENT 售价 (#PCDATA)>
]>
<书架/>
4.2引入外部DTD
4.2.1:当引用的DTD文档在本地时,采用如下方式:
<!DOCTYPE 根元素 SYSTEM “DTD文档路径”>
4.2.2:当引用的DTD文档在公共网络上时,采用如下方式:
<!DOCTYPE 根元素 PUBLIC “DTD名称” “DTD文档的URL”>
5、定义元素:
语法:<!ELEMENT 元素名称 使用规则>
使用规则:
(#PCDATA):表示标签主体内容为普通字符串
EMPTY:表示标签没有主体内容
ANY:主体为任意内容
(子元素):标签中的子元素
用逗号分开:按顺序出现
用“|”:选择其中一个
出现次数:
如果元素后面没有+*?:表示必须且只能出现一次
+:表示至少出现一次,一次或多次
*:表示可有可无,零次、一次或多次
?:表示可以有也可以无,有的话只能有一次。零次或一次
6、定义元素的属性
语法:<!ATTLIST 元素名称
属性名称1 属性值类型 设置说明
属性名称2 属性值类型 设置说明
....
>
属性值类型:
CDATA:普通文本数据
A|B|C "A":表示枚举值,只能从A、B、C中取其中一个,A为默认值
ID:表示取值不能重复
设置说明:
#REQUIRED:表示该属性必须出现
#IMPLIED:表示该属性可有可无
#FIXED:表示属性的取值为一个固定值。语法:#FIXED "固定值"
直接值:表示属性的取值为该默认值
Dom树图解:
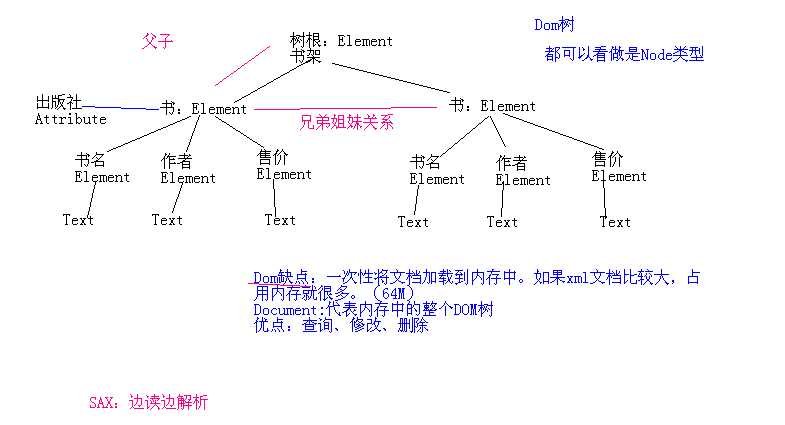
操作代码如下:
Xml文档:
<?xml version="1.0" encoding="UTF-8" standalone="no"?><书架> <书 出版社="清华"> <书名>Java就业培训教程</书名> <作者>张孝祥</作者> <售价>50.00元</售价> </书> <书> <书名>JavaScript网</书名> <作者>张孝祥</作者> <售价>28.00元</售价> </书> </书架>
XML的增删改查
public static void main(String[] args) throws Exception, SAXException, IOException { //1、得到解析器的对象 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = dbf.newDocumentBuilder(); //2、得到XML文档的document对象 Document doc = db.parse("src/book.xml"); // test01(doc); // test02(doc);//Document是Node的子类 // test03(doc); // test04(doc); // test05(doc); // test06(doc); // test07(doc); test08(doc); } // 1、查找某一个节点的内容:第2本书的售价 private static void test01(Document doc){ //NodeList是一个接口类,而不是普通的集合 NodeList nList = doc.getElementsByTagName_r("售价"); //Node亦是如此,是一个类 Node node = nList.item(1); System.out.println(node.getTextContent()); } // 2、遍历所有元素节点 : 递归 private static void test02(Node node){ //1、判断是否是元素节点 if (node.getNodeType() == Node.ELEMENT_NODE) { System.out.println(node.getNodeName()); } //2、判断是否有孩子节点 ,循环遍历 NodeList children = node.getChildNodes(); for (int i = 0; i < children.getLength(); i++) { Node child =children.item(i); test02(child);//递归遍历 } } // 3、修改某个元素节点的主体内容 // 修改第一本书的售价:39.00--->50.00 private static void test03(Document doc) throws Exception{ //1、获取到这个节点 NodeList nList = doc.getElementsByTagName_r("售价"); //2、修改内容:修改了内存中的数据 nList.item(0).setTextContent("50.00元"); //3.更新XML文档到硬盘上 TransformerFactory tf = TransformerFactory.newInstance(); Transformer ts = tf.newTransformer(); ts.transform(new DOMSource(doc), new StreamResult("src/book.xml")); } // 4.向指定元素节点中增加子元素节点 // 第二本书中,增加出版时间 <出版时间> 2013-1-1</出版时间> private static void test04(Document doc) throws Exception{ //1、找到第二本书的元素节点 Node node = doc.getElementsByTagName_r("书").item(1); //2、创建新节点 Element newElement = doc.createElement_x_x_x_x("出版时间"); newElement.setTextContent("2013-1-1"); //3、建立与元素节点的关系 node.a(newElement); //4、更新 硬盘上的XML文档 TransformerFactory tf = TransformerFactory.newInstance(); Transformer ts = tf.newTransformer(); ts.transform(new DOMSource(doc), new StreamResult("src/book.xml")); } // 5.向指定元素节点上,增加同级元素节点 // 在第一本书的<售价>前面,增加一个新节点 <出版社>清华出版社</出版社> private static void test05(Document doc) throws Exception{ //1.找到第一本书的售价 Node node = doc.getElementsByTagName_r("售价").item(0); //2.创建一个新节点 Element newElement = doc.createElement_x_x_x_x("出版社"); newElement.setTextContent("清华出版社"); //3.由父节点执行插入操作 node.getParentNode().insertBefore(newElement, node); //4.更新XML文档 TransformerFactory tf = TransformerFactory.newInstance(); Transformer ts = tf.newTransformer(); ts.transform(new DOMSource(doc), new StreamResult("src/book.xml")); } // 6.删除某个节点 // 删除第一本书的售价 private static void test06(Document doc) throws Exception{ //1.找到第一本书的售价 Node node = doc.getElementsByTagName_r("售价").item(0); //2.由父节点执行删除操作 node.getParentNode().removeChild(node); //4.更新XML文档 TransformerFactory tf = TransformerFactory.newInstance(); Transformer ts = tf.newTransformer(); ts.transform(new DOMSource(doc), new StreamResult("src/book.xml")); } // 7.获取属性的值 // 获取第一本书的属性值:出版社 private static void test07(Document doc){ //1、找到这个元素节点 Node node = doc.getElementsByTagName_r("书").item(0); //2、判断是否是元素节点 if (node.getNodeType() == Node.ELEMENT_NODE) { Element e = (Element) node; String values = e.getAttribute("出版社"); System.out.println(values); } } // 8、增加某个元素节点的属性 // 增加第二本书的属性:出版社:北大青鸟 private static void test08(Document doc) throws Exception{ //1、找到第二本书 Node node = doc.getElementsByTagName_r("书").item(1); //2、新建一个属性 if (node.getNodeType() == Node.ELEMENT_NODE) { Element e = (Element)node; e.setAttribute("出版社", "北大青鸟"); } //4.更新XML文档 TransformerFactory tf = TransformerFactory.newInstance(); Transformer ts = tf.newTransformer(); ts.transform(new DOMSource(doc), new StreamResult("src/book.xml")); }
标签:
原文地址:http://www.cnblogs.com/lixuwu/p/5847665.html