标签:
HBase自带的很多工具可用于管理、分析、修复和调试,这些工具一部分的入口是hbase shell 客户端,另一部分是在hbase的Jar包中。
目录:
hbck:
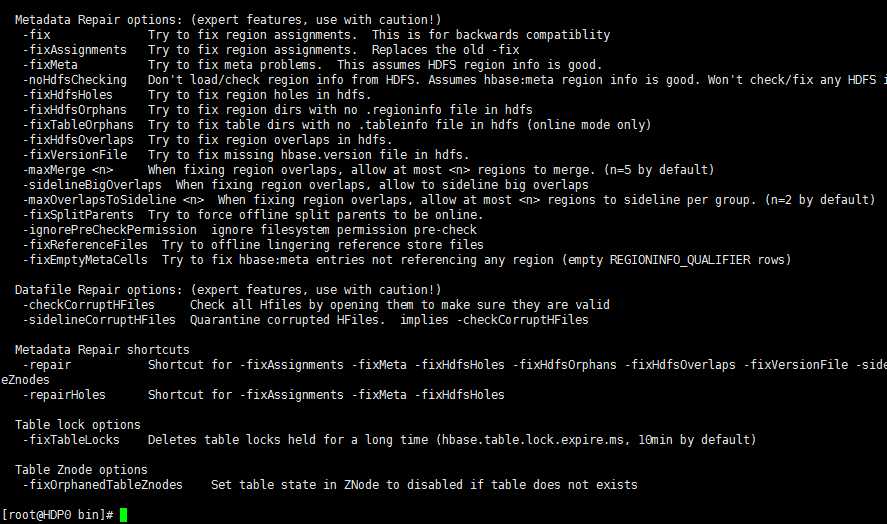

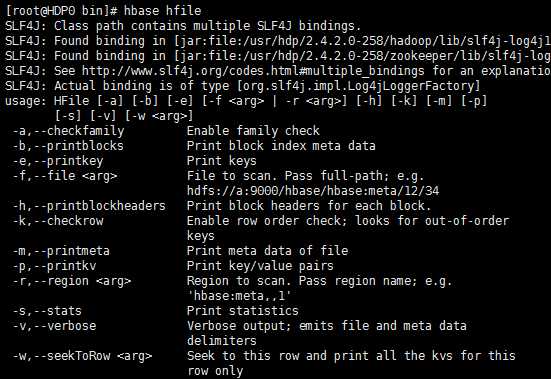
hfile:
数据备份与恢复:
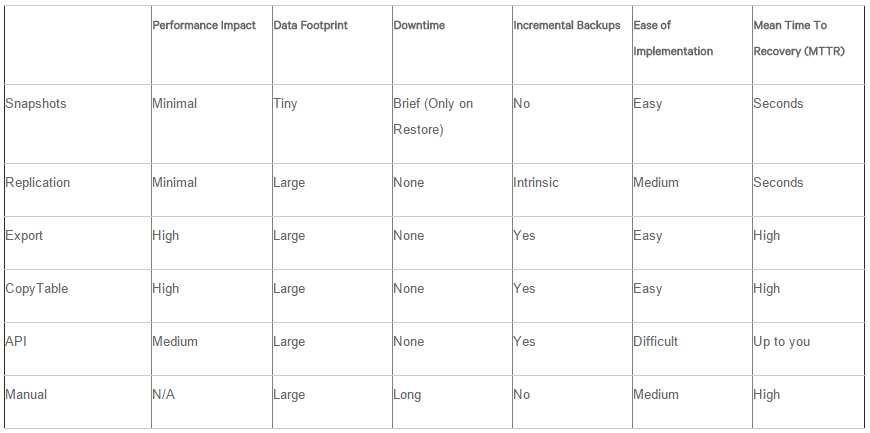
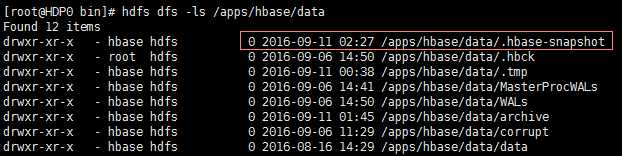
snapshots:
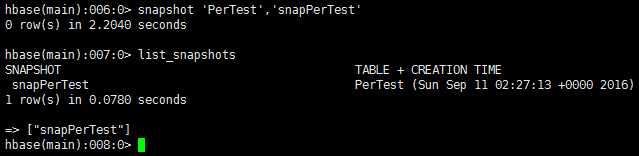
disable ‘PerTest‘
restore_snapshot ‘snapPerTest‘
enable ‘PerTest‘
命令:clone_snapshot ‘snapPerTest‘,‘PerTest1‘ 根据快速clone新表(注:clone出来的新表不带数据副本),如下图:
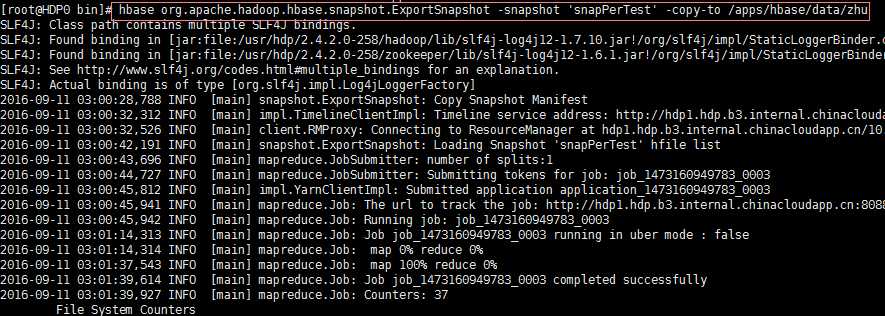
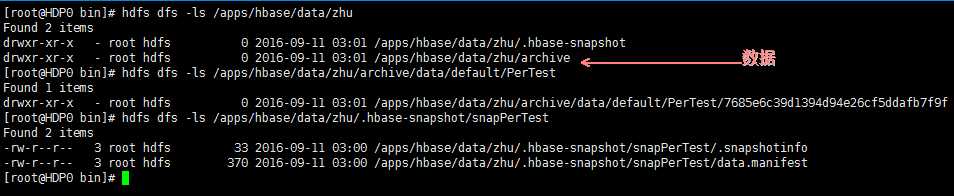
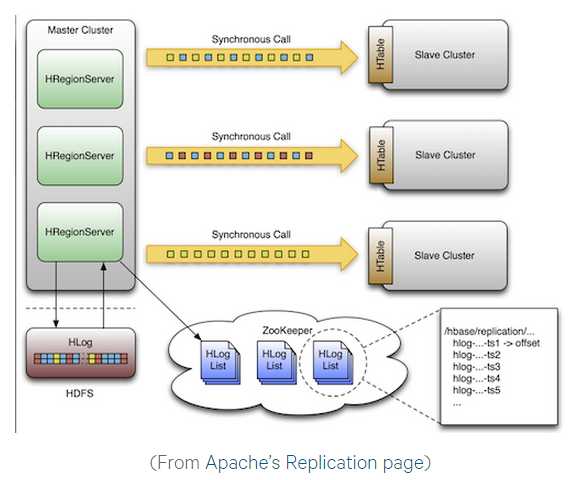
Replication:
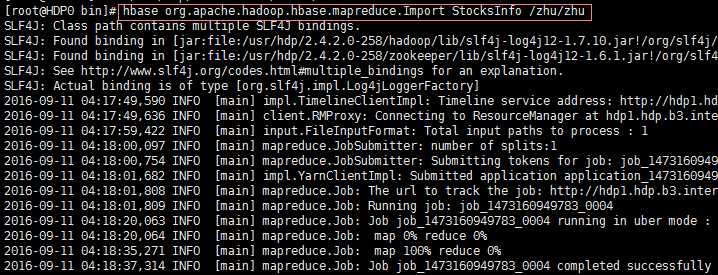
Export:




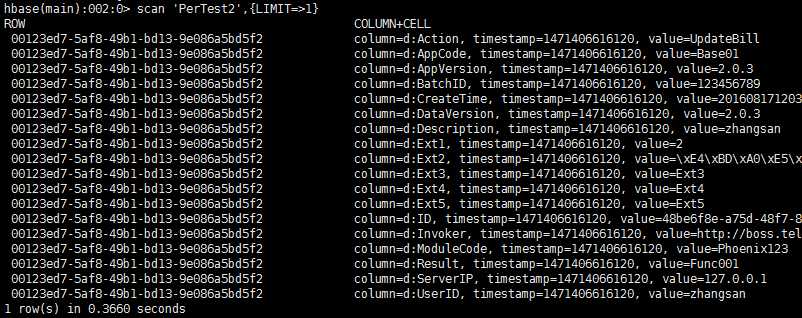
copyTable:
Offline backup of HDFS data:
标签:
原文地址:http://www.cnblogs.com/tgzhu/p/5836231.html