标签:
solr
在一些大型门户网站、电子商务网站等都需要站内搜索功能,使用传统的数据库查询方式实现搜索无法满足一些高级的搜索需求,比如:搜索速度要快、搜索结果按相关度排序、搜索内容格式不固定等,这里就需要使用全文检索技术实现搜索功能。
单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。
通过第三方搜索引擎提供的接口实现站内搜索,这样和第三方引擎系统依赖紧密,不方便扩展,不建议采用。
基于Solr实现站内搜索扩展性较好并且可以减少程序员的工作量,因为Solr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
solr是基于lucene开发企业级搜索服务器,实际上就是封装了lucene。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果
Solr类似webservice,调用接口,实现增加,修改,删除,查询索引库。
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
Solr类似webservice,提供接口,调用接口,发送一些特点语句,实现增加,删除,修改,查询。
从Solr官方网站(http://lucene.apache.org/solr/ )下载Solr4.10.3,根据Solr的运行环境,Linux下需要下载lucene-4.10.3.tgz,windows下需要下载lucene-4.10.3.zip。
Solr使用指南可参考:https://wiki.apache.org/solr/FrontPage。
下载solr-4.10.3.zip并解压,解压后目录为:
bin:solr的运行脚本
contrib:Solr的一些扩展包,包括分词器,聚类,语言识别,数据导入处理,非结构化内容分
析等.
dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。我们之
前使用的solr.war实际上就是这个文件夹下的solr-4.40.war
docs:solr的API文档
example:solr工程的例子目录:
l example/solr:
该目录是一个包含了默认配置信息的Solr的Core目录。
l example/multicore:
该目录包含了在Solr的multicore中设置的多个Core目录。
l example/webapps:
该目录中包括一个solr.war,该war可作为solr的运行实例工程。
l licenses:solr相关的一些许可信息
Jetty服务器是web容器,类似tomcat。
启动solr内置jetty服务器流程:
1、 启动运行example/start.jar
a) 直接在cmd命令行运行命令
b) 使用bat批处理文件运行jar包
2、 加载example/lib下面的jetty服务器
3、 Jetty服务器加载example/webaaps/solr.war项目
4、 加载索引库仓库:example/solr
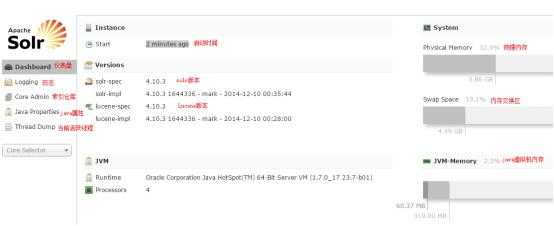
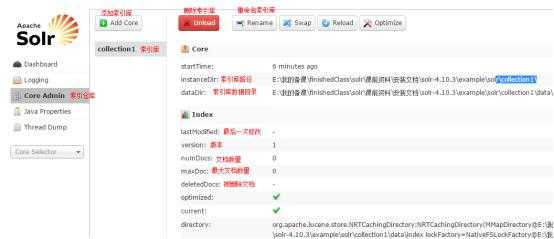
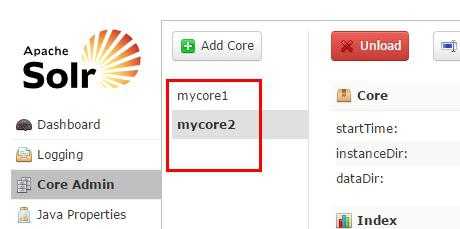
一个core admin(索引仓库)有多个索引库collection1,collection2…..
添加第一个索引库:
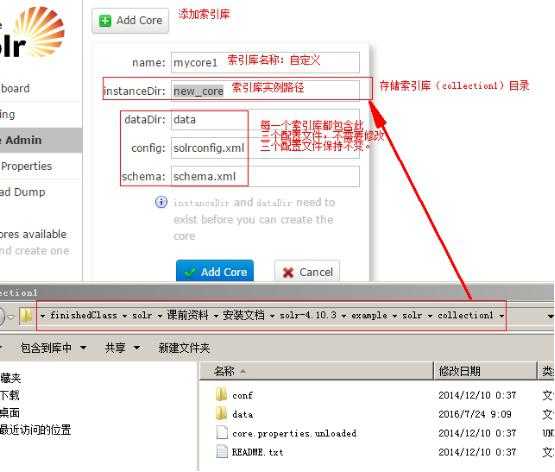
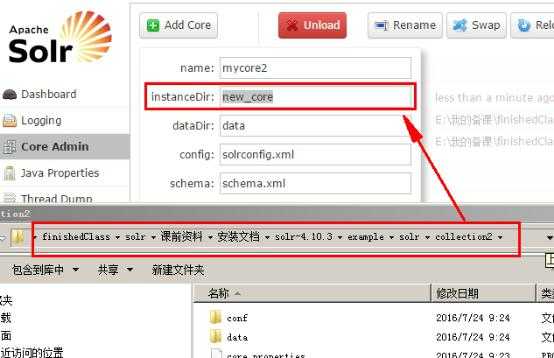
导入外部数据。导入mysql数据库商品数据。
索引库配置文件拷贝,加载索引库配置文件。
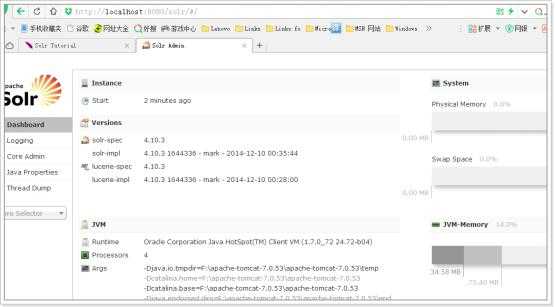
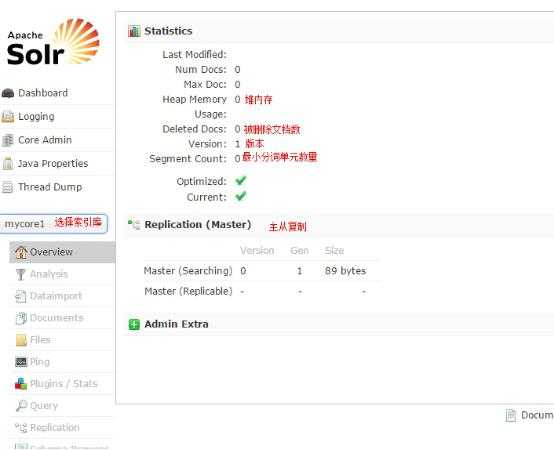
仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息。
Solr运行日志信息
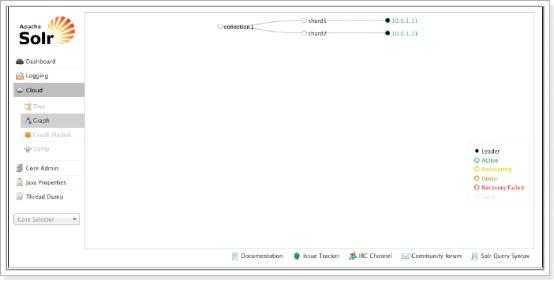
Cloud即SolrCloud,即Solr云(集群),当使用Solr Cloud模式运行时会显示此菜单,如下图是Solr Cloud的管理界面:
Solr Core的管理界面。Solr Core 是Solr的一个独立运行实例单位,它可以对外提供索引和搜索服务,一个Solr工程可以运行多个SolrCore(Solr实例),一个Core对应一个索引目录。
Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。
显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。
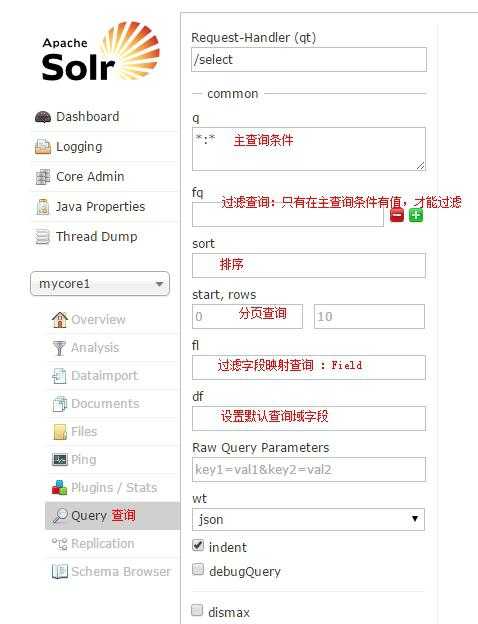
选择一个SolrCore进行详细操作,如下:

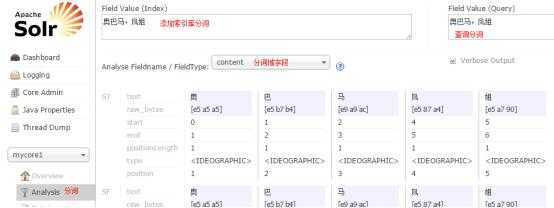
通过此界面可以测试索引分析器和搜索分析器的执行情况。
可以定义数据导入处理器,从关系数据库将数据导入 到Solr索引库中。
Document(重点)
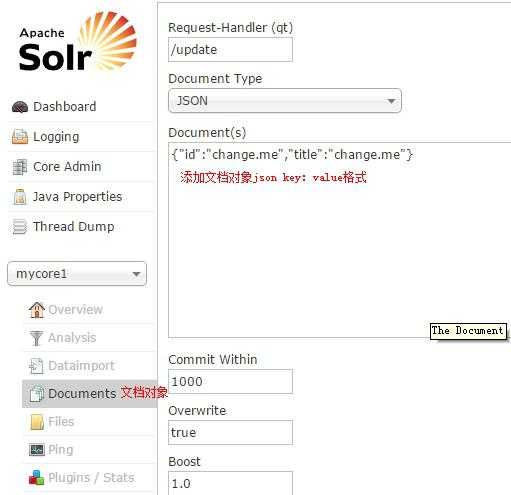
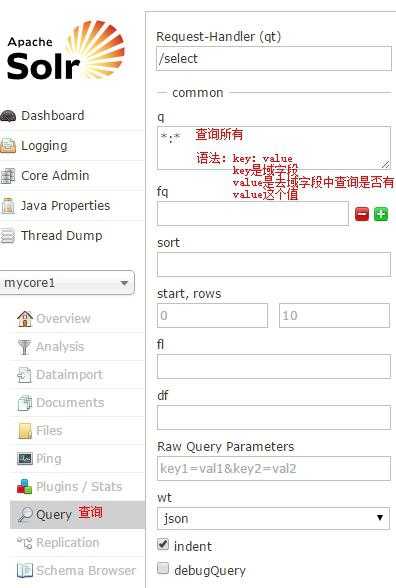
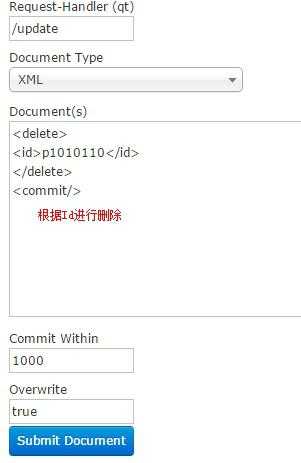
通过此菜单可以创建索引、更新索引、删除索引等操作,界面如下:
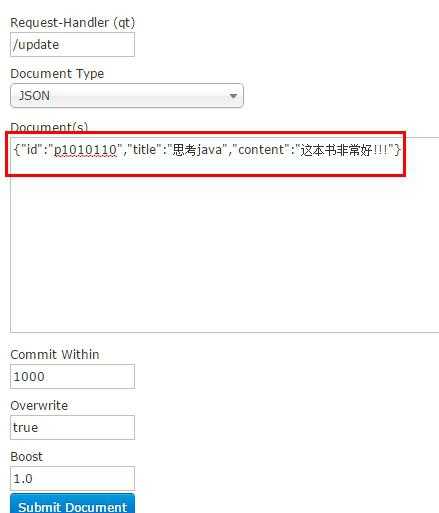
/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
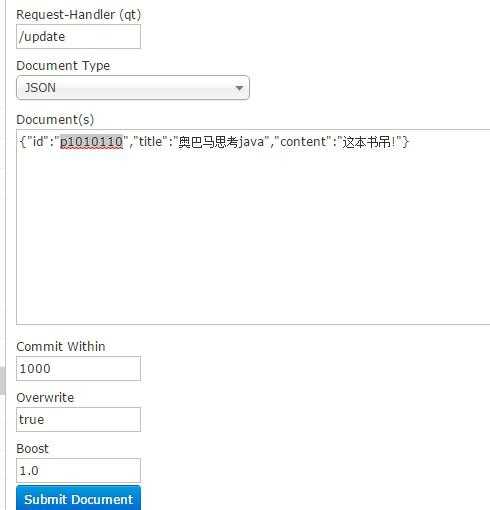
如果Id存在,修改
如果Id不存在,添加。
Solr 支持系统属性替换,允许启动JVM在任一Solr的配置文件指定字符串替换。
语法: ${property[:default value]}
替换是有效的在任何元素或属性的文本。
这里是允许运行时决定数据目录的一个例子:
<dataDir>${solr.data.dir:./solr/data}</dataDir> 使用示例应用程序中
solr可以以这种方式启动:
java -Dsolr.data.dir=/data/dir -jar start.jar 如果没有指定
solr启动时读取 conf/solrcore.properties文件
#solrcore.properties data.dir=/data/solrindex
解析:运行时替换目录意思
注意:在solrConfig配置文件里面使用${},这是solr语法格式。
简单解释一下:
Solr.就代表solrcore索引库目录:collection1这一层目录。
顾名思义:solr.data.dir表示的意思就是collection1下面的data目录。
这是solr的一种约定,不必深究,知道solr.就是我们的索引库目录就ok。
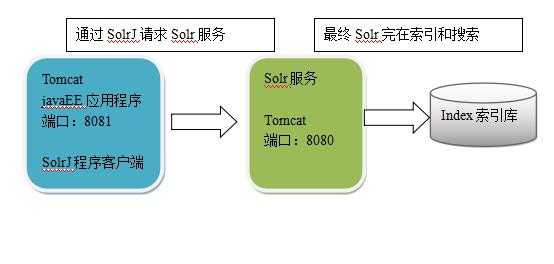
solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常在嵌入在业务系统中,通过SolrJ的API接口操作Solr服务
标签:
原文地址:http://www.cnblogs.com/fengru/p/5861958.html