标签:
在 HBase(六): HBase体系结构剖析(上) 介绍过,Hbase创建表时,只需指定表名和至少一个列族,基于HBase表结构的设计优化主要是基于列族级别的属性配置,如下图:

目录:
BLOOMFILTER:
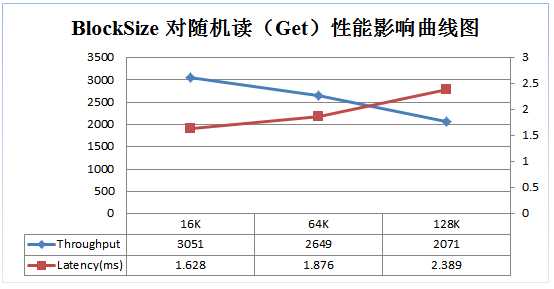
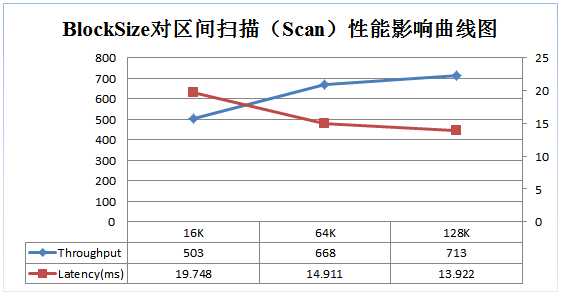
BLOCKSIZE:
[root@HDP0 bin]# hbase hfile -m -f /apps/hbase/data/data/default/PerTest/7685e6c39d1394d94e26cf5ddafb7f9f/d/3ef195ca65044eca93cfa147414b56c2
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/hdp/2.4.2.0-258/hadoop/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hdp/2.4.2.0-258/zookeeper/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2016-09-11 12:54:40,514 INFO [main] hfile.CacheConfig: CacheConfig:disabled
Block index size as per heapsize: 6520
reader=/apps/hbase/data/data/default/PerTest/7685e6c39d1394d94e26cf5ddafb7f9f/d/3ef195ca65044eca93cfa147414b56c2,
compression=none,
cacheConf=CacheConfig:disabled,
firstKey=00123ed7-5af8-49b1-bd13-9e086a5bd5f2/d:Action/1471406616120/Put,
lastKey=fffbc8f7-55f2-4c49-804f-444f6ccbc903/d:UserID/1471406614464/Put,
avgKeyLen=55,
avgValueLen=10,
entries=54180,
length=4070738
从上面输出的信息可以看出,该HFile的平均键值对规模为55B + 10B = 65B,相对较小,在这种情况下可以适当将块大小调小(例如8KB或16KB)。这样可以使得一个block内不会有太多kv,kv太多会增大块内寻址的延迟时间,因为HBase在读数据时,一个block内部的查找是顺序查找
IN_MEMORY:
hbase(main):002:0> create ‘Test‘,{NAME=>‘d‘,IN_MEMORY=>‘true‘} 0 row(s) in 4.4970 seconds => Hbase::Table - Test
hbase(main):003:0> describe ‘Test‘ Table Test is ENABLED Test COLUMN FAMILIES DESCRIPTION {NAME => ‘d‘, BLOOMFILTER => ‘ROW‘, VERSIONS => ‘1‘, IN_MEMORY => ‘true‘, KEEP_DELETED_CELLS => ‘FALSE‘, DATA_BLOCK_ENCODING => ‘NONE‘, TTL => ‘FOREVER‘, COMPRESSION => ‘NONE‘, MIN_VERSIONS => ‘0‘, BLOCKCACHE => ‘true‘, BLOCKSIZE => ‘65536‘, REPLICATION_SCOPE => ‘0‘} 1 row(s) in 0.2530 seconds hbase(main):004:0> create ‘Test1‘,‘d‘ 0 row(s) in 2.2400 seconds => Hbase::Table - Test1 hbase(main):005:0> disable ‘Test1‘ 0 row(s) in 2.2730 seconds hbase(main):006:0> alter ‘Test1‘,{NAME=>‘d‘,IN_MEMORY=>‘true‘} Updating all regions with the new schema... 1/1 regions updated. Done. 0 row(s) in 2.4610 seconds hbase(main):007:0> enable ‘Test1‘ 0 row(s) in 1.3370 seconds hbase(main):008:0> describe ‘Test1‘ Table Test1 is ENABLED Test1 COLUMN FAMILIES DESCRIPTION {NAME => ‘d‘, BLOOMFILTER => ‘ROW‘, VERSIONS => ‘1‘, IN_MEMORY => ‘true‘, KEEP_DELETED_CELLS => ‘FALSE‘, DATA_BLOCK_ENCODING => ‘NONE‘, TTL => ‘FOREVER‘, COMPRESSION => ‘NONE‘, MIN_VERSIONS => ‘0‘, BLOCKCACHE => ‘true‘, BLOCKSIZE => ‘65536‘, REPLICATION_SCOPE => ‘0‘} 1 row(s) in 0.0330 seconds hbase(main):009:0>
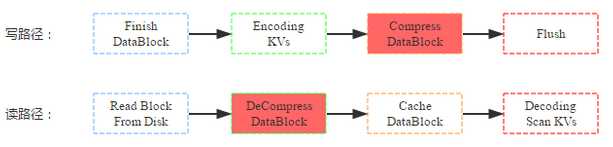
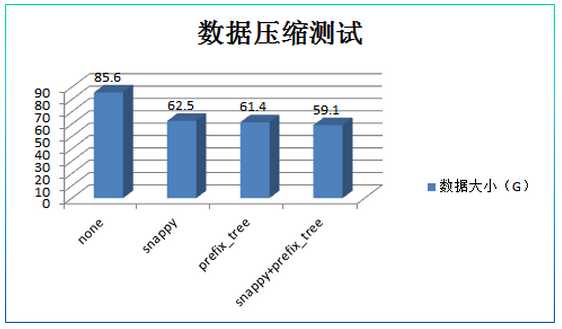
COMPRESSION/ENCODING:

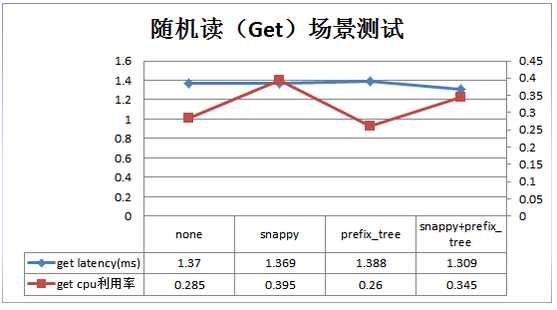
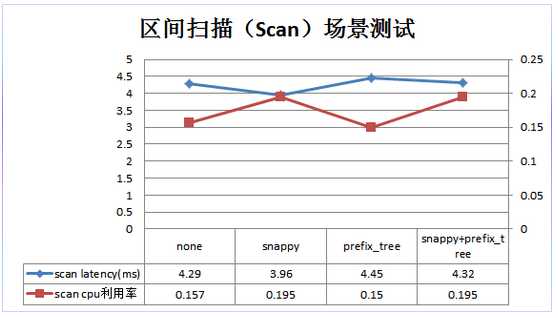
VERSIONS:
TTL:
标签:
原文地址:http://www.cnblogs.com/tgzhu/p/5862299.html