标签:
Chars74K数据集是一个经典的字符识别数据集,主要包括了英文字符与坎那达语(Kannada)字符。数据集一共有74K幅图像,所以叫Chars74K。
英文数据集依据图像采集方式分为三个类别:
1. 自然环境下采集的字符图像数据集;
2. 手写字符图像数据集;
3. 计算机不同字体合成的字符图像数据集。
这里只介绍英文手写字符数据集。该数据集包含了52个字符类别(A-Z,a-z)和10个数字类别(0-9)一共62个类别,3410副图像,由55个志愿者手写完成。
该数据集在EnglishHnd.tgz这个文件中(English Hand writing),图像主要在Img这个文件夹下,按照Samples001-Samples062的命名方式存储在62个子文件夹下,每个子文件夹有55张图像,都为PNG格式,分辨率为1200*900,三通道RGB图像。
一些图像如图所示:


数据集作者提供了matlab的读入方式,在Lists.tgz文件里的English/Hnd文件夹下有个lists_var_size.MAT文件来进行数据读入,但该文件只是建立了一个结构体(struct),提供了相关信息,图像的实际数据还是要自己写代码读入。
该结构体载入进来后如下:
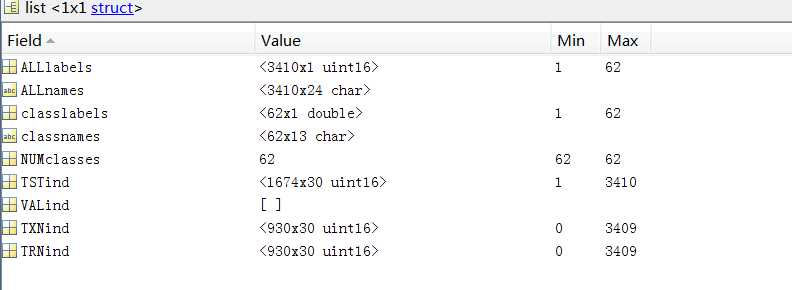
数据集作者已经将训练数据与测试数据分成了30个不同的子集,就是以上的TRNind和TSTind,这里面存储的是图像的索引(Index),但这里要注意的是有些训练数据子集不是930个,后面有些数据是0。
以下的matlab代码在作者提供的mat文件基础上,将一个子集的训练数据、测试数据以及标签(实际分类)等信息读入,图像数据读入为cell数组,标签数据读入为uint16数组(需要注意的是标签1代表实际的数字0,标签2代表实际的数字1,依此类推)。
%% read images from chars74k English Hnd dataset.
clc, clear;
% list is a struct, which contains:
% ALLlabels: [3410*1 uint16]
% ALLnames: [3410*24 char]
% classlabels: [62*1 double]
% classnames: [62*13 char]
% NUMclasses: 62
% TSTind: [1674*30 uint16]
% VALind: []
% TXNind: [930*30 uint16]
% TRNind: [930*30 uint16]
load(‘lists_var_size.mat‘);
%% extract training and test datasets
%{
There are 30 patches in the dataset(training & test)
we will select the Nth training and test dataset.
%}
N = 14;
% separats the training & test indexes in dataset
training_index = list.TRNind(:,N);
test_index = list.TSTind(:,N);
% some training patches may have some elements equal to 0
% which we must ignore them.
locate_zero = find(training_index == 0);
training_index(locate_zero) = [];
% the class labels for training set
training_labels = list.ALLlabels(training_index);
% the ground truth labels for test set
test_true_labels = list.ALLlabels(test_index);
%% read image data
for ii = 1:length(training_index)
img = imread([‘../../../English/Hnd/‘,...
list.ALLnames(training_index(ii), :), ‘.png‘]);
training_imgs{ii} = img;
% if we want to see the image
% image(img);
% pause();
end
for ii = 1:length(test_index)
img = imread([‘../../../English/Hnd/‘,...
list.ALLnames(test_index(ii), :), ‘.png‘]);
test_imgs{ii} = img;
% if we want to see the image
% image(img);
% pause();
end
Python,OpenCV版本等待更新,或有人愿意一起做可以互相交流。
有任何错误或不恰当的地方,欢迎指正。
参考链接:
http://www.ee.surrey.ac.uk/CVSSP/demos/chars74k/
参考文献:
Teófilo Emídio de Campos, Bodla Rakesh Babu, Manik Varma. Character Recognition in Natural Images.[C]// Visapp 2009 - Proceedings of the Fourth International Conference on Computer Vision Theory and Applications, Lisboa, Portugal, February. 2009:273-280.
注:本文原发于七月在线论坛,是计算机视觉公开课的一次作业。
手写字符识别资源汇总-Chars74K数据集简介及手写字符子数据集相关读取方法
标签:
原文地址:http://www.cnblogs.com/qdsclove/p/5865463.html