标签:
最近在客户那里环境中coherence集群不稳定,所以找出一些文档,需要搞清楚Coherence内部的一些机制
1.集群成员的离开
关于状态的检测,官方的说法是:
Death detection is a cluster mechanism that quickly detects when a cluster member has failed. Failed cluster members are removed from the cluster and all other cluster members are notified about the departed member.
Death detection allows the cluster to differentiate between actual member failure and an unresponsive member, such as the case when a JVM conducts a full garbage collection.(检测允许集群区分真实的成员失败或者是因为JVM做GC引起的不回映)
Death detection identifies both process failures (TcpRing component) and hardware failure (IpMonitor component).
Process failure is detected using a ring of TCP connections opened on the same port that is used for cluster UDP communication. Each cluster member issues a unicast heartbeat, and the most senior cluster member issues the cluster heartbeat, which is a broadcast message.
Hardware failure is detected using the JavaInetAddress.isReachable method which either issues a trace ICMP ping, or a pseudo ping and uses TCP port 7. Death detection is enabled by default and is configured within the <tcp-ring-listener> element.
自己找了一些文档,应该是有3种情况:
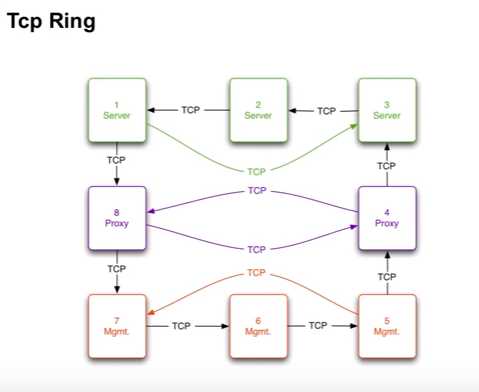
1.进程失败(包含ctrl-c,kill-9等),通过TcpRing,所谓Ring就是以TCP协议建立的连接,端口是用的集群的UDP端口,如下面图所示,第一个Ring覆盖整个集群的所有结点,连成一个环,其他的Ring根据各自的角色Role,连成环.
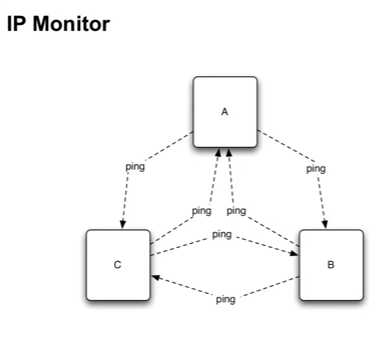
2.硬件失败,通过ping,或者文档中所的ICMP ping,连续失败的ping表示机器死亡,(15s),任意找机器,同时由对方kernel回答,不需要coherence node确认.
3.Package Timeout.
扑获所有的失败(包括硬件,网络,进程),原理是包的传输必须得到确认(acknoledge),否则缺省状态下200ms重传,5分钟后超时
无论是发送端还是接受端都被标记为被声明死亡
然后由多个结点投票决定谁的状态是死亡。
论坛上找到一个例子
* Member 27 has a timeout sending a packet to Member 16
* Member 27 asks Member 83 and member 85 to confirm departure of Member 16
* Member 83 rejects the confirmation request (@ 2010-09-22 05:21:43.411)
* Member 85 accepts the confirmation request (I assume it does as it has no rejection in its log)
* Member 27 informs the rest of the cluster that Member 16 has departed
* Member 1 (the senior member) heartbeats Member 16 causing it to re-initialise itself - it then rejoins as Member 127.
这种方式最不确定,机制细节也不是太清楚
2.集群成员的加入
集群成员是通过Cluster Service来负责加入集群的,我的理解是Cluster Service通过Multicast或Unicast的方式检测并加入集群,当然需要保证clustername一致.
-Dtangosol.coherence.cluster=MyFirstCluster
Cluster Service: This service is automatically started when a cluster node must join the cluster; each cluster node always has exactly one service of this type running. This service is responsible for the detection of other cluster nodes, for detecting the failure of a cluster node, and for registering the availability of other services in the cluster.
3.集群的通讯
Coherence Cluster的通讯通过TCMP(Tangosol Cluster Management Protocol)协议进行通讯,既能进行multicast和能进行unicast.
关于TCMP文档说得比较清楚,摘录一段.
TCMP is an IP-based protocol that is used to discover cluster members, manage the cluster, provision services, and transmit data. TCMP can be configured to use:
A combination of UDP/IP multicast and UDP/IP unicast. This is the default configuration.
UDP/IP unicast only (that is, no multicast). See "Disabling Multicast Communication". This configuration is used for network environments that do not support multicast or where multicast is not optimally configured.
TCP/IP only (no UDP/IP multicast or UDP/IP unicast). See "Using the TCP Socket Provider". This configuration is used for network environments that favor TCP.
SDP/IP only (no UDP/IP multicast or UDP/IP unicast). See "Using the SDP Socket Provider". This configuration is used for network environments that favor SDP.
SSL over TCP/IP or SDP/IP. See "Using the SSL Socket Provider". This configuration is used for network environments that require highly secure communication between cluster members.
Multicast is used as follows:
Cluster discovery: Multicast is used to discover if there is a cluster running that a new member can join.
Cluster heartbeat: The most senior member in the cluster issues a periodic heartbeat through multicast; the rate can be configured and defaults to one per second.
Message delivery: Messages that must be delivered to multiple cluster members are often sent through multicast, instead of unicasting the message one time to each member.
Unicast is used as follows:
Direct member-to-member (point-to-point) communication, including messages, asynchronous acknowledgments (ACKs), asynchronous negative acknowledgments (NACKs) and peer-to-peer heartbeats. A majority of the communication on the cluster is point-to-point.
Under some circumstances, a message may be sent through unicast even if the message is directed to multiple members. This is done to shape traffic flow and to reduce CPU load in very large clusters.
All communication is sent using unicast if multicast communication is disabled.
TCP is used as follows:
A TCP/IP ring is used as an additional death detection mechanism to differentiate between actual node failure and an unresponsive node (for example, when a JVM conducts a full GC).
TCMP can be configured to exclusively use TCP for data transfers. Like UDP, the transfers can be configured to use only unicast or both unicast and multicast.
The TCMP protocol provides fully reliable, in-order delivery of all messages. Since the underlying UDP/IP protocol does not provide for either reliable or in-order delivery, TCMP uses a queued, fully asynchronous ACK- and NACK-based mechanism for reliable delivery of messages, with unique integral identity for guaranteed ordering of messages.
The TCMP protocol (as configured by default) requires only three UDP/IP sockets (one multicast, two unicast) and six threads per JVM, regardless of the cluster size. This is a key element in the scalability of Coherence; regardless of the number of servers, each node in the cluster still communicates either point-to-point or with collections of cluster members without requiring additional network connections.
The optional TCP/IP ring uses a few additional TCP/IP sockets, and an additional thread.
The TCMP protocol is very tunable to take advantage of specific network topologies, or to add tolerance for low-bandwidth and high-latency segments in a geographically distributed cluster. Coherence comes with a pre-set configuration. Some TCMP attributes are dynamically self-configuring at run time, but can also be overridden and locked down for deployment purposes.
问题:
1.在集群成员某个node或者proxy非常忙碌的情况下,会不会被大家剔出集群?
2.让他的状态恢复以后,会不会再重新加入集群?
需要通过试验证明.
标签:
原文地址:http://www.cnblogs.com/ericnie/p/5869694.html