标签:
相比于 Hadoop 1.0,Hadoop 2.0 中的 HDFS 增加了两个重大特性,HA 和 Federaion。HA 即为 High Availability,用于解决 NameNode 单点故障问题,该特性通过热备的方式为主 NameNode 提供一个备用者,一旦主 NameNode 出现故障,可以迅速切换至备 NameNode, 从而实现不间断对外提供服务。Federation 即为“联邦”,该特性允许一个 HDFS 集群中存在 多个 NameNode 同时对外提供服务,这些 NameNode 分管一部分目录(水平切分),彼此之 间相互隔离,但共享底层的 DataNode 存储资源。
本文档重点介绍 HDFS HA 和 Federation 的安装部署方法。
在一个典型的 HDFS HA 场景中,通常由两个 NameNode 组成,一个处于 active 状态, 另一个处于 standby 状态。Active NameNode 对外提供服务,比如处理来自客户端的 RPC 请 求,而 Standby NameNode 则不对外提供服务,仅同步 active namenode 的状态,以便能够在 它失败时快速进行切换。
为了能够实时同步 Active 和 Standby 两个 NameNode 的元数据信息(实际上 editlog), 需提供一个共享存储系统,可以是 NFS、QJM(Quorum Journal Manager)或者 Bookeeper, Active Namenode 将数据写入共享存储系统,而 Standby 监听该系统,一旦发现有新数据写 入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与 Active NameNode 保持 基本一致,如此这般,在紧急情况下 standby 便可快速切为 active namenode。
注意,在 Hadoop 2.0 中,不再需要 secondary namenode 或者 backup namenode,它们的 工作由 Standby namenode 承担。
本文将重点介绍基于 QJM 的 HA 解决方案。在该方案中,主备 NameNode 之间通过一组 JournalNode 同步元数据信息,一条数据只要成功写入多数 JournalNode 即认为写入成功。 通常配置奇数个(2N+1)个 JournalNode,这样,只要 N+1 个写入成功就认为数据写入成功, 此时最多容忍 N-1 个 JournalNode 挂掉,比如 3 个 JournalNode 时,最多允许 1 个 JournalNode 挂掉,5 个 JournalNode 时,最多允许 2 个 JournalNode 挂掉。基于 QJM 的 HDFS 架构如下 所示:
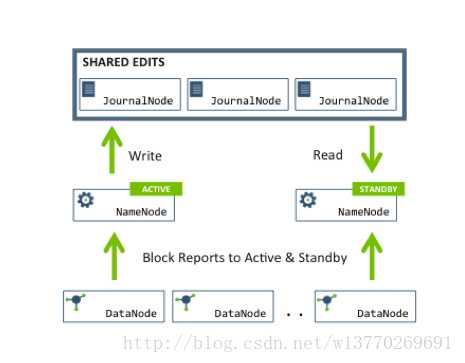
? NameNode 机器:推荐主备 NameNode 具有相同的硬件配置,且内存要足够大。
? JournalNode:通常准备 3 或 5 个 JournalNode,考虑到 JournalNode 非常轻量级,可以与 Hadoop 其他服务共用机器,比如 ResourceManager,TaskTracker 等。
? Zookeeper:由于 Hadoop 多个服务用到了 Zookeeper,可搭建一个 3 或者 5 个节点的Zookeeper 实例作为公共服务。Zookeeper 实例也可以与其他服务共用机器。
? NameNode 机器:推荐主备 NameNode 具有相同的硬件配置,且内存要足够大。
? JournalNode:通常准备 3 或 5 个 JournalNode,考虑到 JournalNode 非常轻量级,可以与 Hadoop 其他服务共用机器,比如 ResourceManager,TaskTracker 等。
? Zookeeper:由于 Hadoop 多个服务用到了 Zookeeper,可搭建一个 3 或者 5 个节点的Zookeeper 实例作为公共服务。Zookeeper 实例也可以与其他服务共用机器。
? NameNode 机器:推荐主备 NameNode 具有相同的硬件配置,且内存要足够大。
? JournalNode:通常准备 3 或 5 个 JournalNode,考虑到 JournalNode 非常轻量级,可以与 Hadoop 其他服务共用机器,比如 ResourceManager,TaskTracker 等。
? Zookeeper:由于 Hadoop 多个服务用到了 Zookeeper,可搭建一个 3 或者 5 个节点的Zookeeper 实例作为公共服务。Zookeeper 实例也可以与其他服务共用机器。
?<property> <name>dfs.nameservices</name> <value>nn</value> ??????<description>Logical name for this new nameservice</description> </property>
hdfs-federation配置,可同时有多个namenode服务:
<property> <name>dfs.federation.nameservices</name> <value>nn1,nn2</value> ??????<description>Logical name for this new nameservice</description> </property>
某个命名服务下包含的 NameNode 列表,可为每个 NameNode 指定一个自定义的 ID 名称,比如命名服务 nn 下有两个 NameNode,分别命名为 nn1 和 nn2,则配置如下:
??<property> <name>dfs.ha.namenodes.nn</name> <value>nn1,nn2</value> ???????<description>Unique identifiers for each NameNode in the nameservice </description> </property>
注意,目前每个命名服务最多配置两个 NameNode
为每个 NameNode 设置 RPC 地址,以前面的实例为例,可进行如下配置:
<property> <name>dfs.namenode.rpc-address.nn.nn1</name> <value>nn1:9000</value> </property> <property> <name>dfs.namenode.rpc-address.nn.nn2</name> <value>nn2:9000</value> </property>
为每个 NameNode 设置对外的 HTTP 地址,以前面的实例为例,可进行如下配置:
?<property> <name>dfs.namenode.http-address.nn.nn1</name> <value>192.168.10.110:50070</value> </property> <property> <name>dfs.namenode.http-address.nn.nn2</name> <value>192.168.10.111:50070</value> ??????????????????</property>
设置一组 journalNode 的 URI 地址,active NameNode 将 edit log 写入这些JournalNode,而 standby NameNode 读取这些 edit log,并作用在内存中的目录树中,该属性 值应符合以下格式:
qjournal://host1:port1;host2:port2;host3:port3/journalId
其中,journalId 是该命名空间的唯一 ID。假设你有三台 journalNode,即 dn1, dn2 和 dn3,则可进行如下配置:
<property> ???<name>dfs.namenode.shared.edits.dir</name> <value>qjournal://dn1:8485;dn2:8485; dn3:8485;dn4:8485;dn6:8485/nn</value> </property>
注意,JournalNode 默认端口号为 8485
设置客户端与 active NameNode 进行交互的 Java 实现类,DFS 客户端通过该类寻找当前的 active NameNode。该类可由用户自己实现,默认实现为 ConfiguredFailoverProxyProvider。
<property> <name>dfs.client.failover.proxy.provider.nn</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property>
<property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property>
你可以配置一个 ssh 用户和端口号,并设置一个超时时间,一旦 ssh 超过该时间,则认为执 行失败。
?<property> <name>dfs.ha.fencing.methods</name> <value>sshfence([[username][:port]])</value> </property> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property>
2) shell
执行任意一个 shell 命令隔离旧的 active NameNode,配置方法如下:
<property> <name>dfs.ha.fencing.methods</name> <value>shell(/path/to/my/script.sh arg1 arg2 ...)</value> (这里没搞懂) </property>
注意,Hadoop 中所有参数将以环境变量的形似提供给该 shell,但所有的“.”被替换成了“_”, 比如“dfs.namenode.rpc-address.ns1.nn1”变为“dfs_namenode_rpc-address”
设置缺省的目录前缀,需在 core-site.xml 中设置,比如命名服务的 ID 为 mycluster(参 数 dfs.nameservices 指定的),则配置如下:
<property> <name>fs.defaultFS</name> <value>hdfs://nn</value> ????????????</property>
JournalNode 所在节点上的一个目录,用于存放 editlog 和其他状态信息。该参数只能设置一个目录,你可以对磁盘做 RIAD 提高数据可靠性。
<property> <name>dfs.journalnode.edits.dir</name> <value>/opt/journal/node/local/data</value> </property>

标签:
原文地址:http://www.cnblogs.com/Dhouse/p/5871217.html

