标签:
Hive架构:
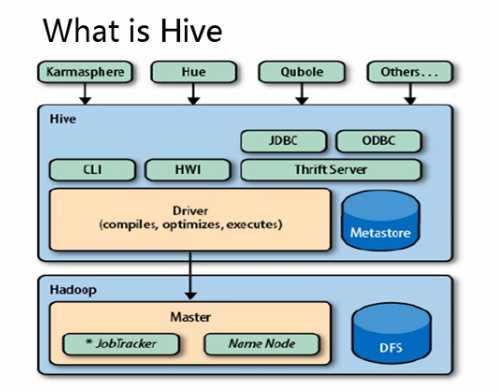
1.1.1 hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表, 并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。--OLAP
1.2.1 OLAP逻辑和SQL一样大体一致,可以将这些逻辑转化为对应的MR,不需要每种类型的查询分析都重复写MR
1.2.2 Facebook开发通用的MR程序框架,对外使用SQL接口,框架就是Hive
1.3.1 http://hive.apache.org/
1.4.2.1 Compiler编译器匹配MR模板,生成MR实例
1.4.3.1 Hive采用的方法是将SQL查询转化成MapReduce任务,这导致Hive的性能很差。 而且,Hive只能支持不到30%的SQL分析功能
1.5.1.1 使用MPP并行数据库思想,完全抛弃了MapReduce这个不太适合做SQL查询的范式。 比基于MapReduce的HiveSQL查询速度提升3~30倍。支持HDFS、HBASE作为存储引擎。
1.5.1.2 http://baike.baidu.com/link?url=wjJdGGrc150Mjrw_JX53P8aEdLOtVwi7hO6P31CKjAmq 2v7P6mEVkRLLLuyvQXI7p_GUsN3du2jF4detmY1t-q
1.5.1.3 http://www.ctocio.com/bigdata/9236.html
1.5.2.1 Impala仅支持CDH,Drill构建在Hadoop通用版本之上
1.5.3.1 Shark为了实现Hive兼容,在HQL方面重用了Hive中HQL的解析、逻辑执行计划翻译、 执行计划优化等逻辑,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业
1.5.3.2 http://zhidao.baidu.com/link?url=KsaLI5bexln9hVHFp4mABsq2xSpwdllf89-sGZlwz1lAoUo OPMJwGgS0w-eaHOVbaxGYMsxbI5KjYxFRj1sv1MC_XTW0BN2hf96NF8ZdHcu
1.5.4.1 http://www.csdn.net/article/2014-07-02/2820482-shark-spark-sql-hive-on-spark-and-the-future-of-sql-on-spark
1.5.5.1 http://baike.baidu.com/link?url=vqQi3df9gQb6pnudACgLzz6NCgRvlOvoA0mtXGDeqiawcy22yt2FTYrJkv PeRNS6uyMhvkrwmtLCb_312cmg9a
1.5.6.1 http://www.linuxidc.com/Linux/2015-07/119958.htm
1.5.6.2 http://prestodb-china.com/
1.5.6.3 http://blog.csdn.net/joomlaer/article/details/45889759
1.5.7.1 http://stackoverflow.com/questions/17113964/comparing-cassandras-cql-vs-spark- shark-queries-vs-hive-hadoop-dse-version
1.5.7.2 http://blog.163.com/xiaoji0106@126/blog/static/136134661201411322353856/
1.5.7.3 http://blog.sina.com.cn/s/blog_6277623c0102vnq2.html
1.5.7.4 http://blog.chinaunix.net/uid-29242841-id-4030543.html
1.5.7.5 https://www.zhihu.com/question/41541395
【Hive】Hive 基础
标签:
原文地址:http://www.cnblogs.com/junneyang/p/5871233.html