请求分段系统是在分段系统的基础上,增加了请求调段功能和分段置换功能所形成的分段式虚拟存储系统。分段式存储管理方式分配算法与可变分区的分配算法相似,可以采用最佳适应法、最坏适应法和首次适应法等分配算法。显然仍然要解决外碎片的问题。
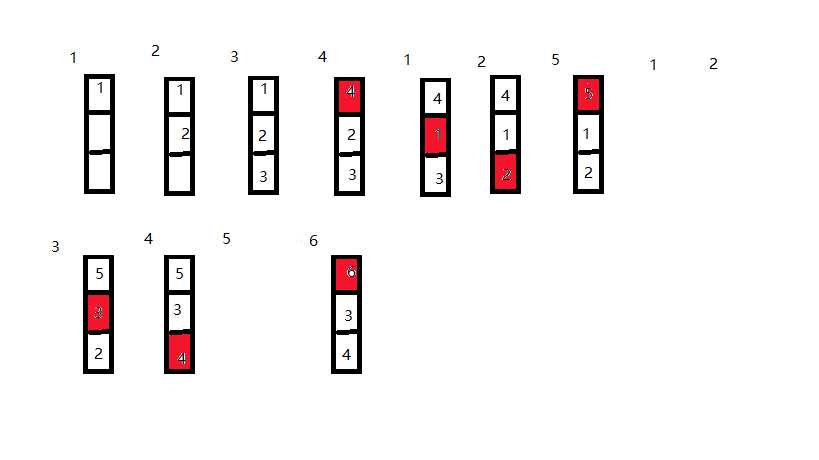
在虚拟存储系统中,若进程在内存中占三块(开始时为空,采用先进先出页面淘汰算法,当执行访问页号序列为1、2、3、4、1、2、5、1、2、3、4、5、6时,将产生( )次缺页中断。
先进先出页面替换算法(The First-In First-Out Page Replacement Algorithm)。顾名思义,这种算法的思路是把所有已在内存中的页面组织成一个队列(也可以是一个链表),每次当有页面换入到内存中的时候,就添加到队列的末尾;当需要页面换出时,直接从队列中移除页面。把留在内存中时间最长的页面换出内存,
操作系统采用缓冲技术,通过减少对CPU的()次数,提高资源的利用率。
引入缓冲的主要原因包括:缓和CPU与I/O设备间速度不匹配的矛盾;减少对CPU的中断频率,放宽对中断响应时间的限制;提高CPU和I/O设备之间的并行性。所以采用缓冲技术,可减少对CPU的中断次数,从而提高系统效率。
多级反馈队列调度算法是一种CPU处理机调度算法,UNIX操作系统采取的便是这种调度算法。
**多级(假设为N级)反馈队列调度算法可以如下原理**
1、设有N个队列(Q1,Q2....QN),其中各个队列对于处理机的优先级是不一样的,也就是说位于各个队列中的作业(进程)的优先级也是不一样的。一般来说,优先级Priority(Q1) > Priority(Q2) > ... > Priority(QN)。怎么讲,位于Q1中的任何一个作业(进程)都要比Q2中的任何一个作业(进程)相对于CPU的优先级要高(也就是说,Q1中的作业一定要比Q2中的作业先被处理机调度),依次类推其它的队列。
2、对于某个特定的队列来说,里面是遵循时间片轮转法。也就是说,位于队列Q2中有N个作业,它们的运行时间是通过Q2这个队列所设定的时间片来确定的(为了便于理解,我们也可以认为特定队列中的作业的优先级是按照FCFS来调度的)。
3、各个队列的时间片是一样的吗?不一样,这就是该算法设计的精妙之处。各个队列的时间片是随着优先级的增加而减少的,也就是说,优先级越高的队列中它的时间片就越短。同时,为了便于那些超大作业的完成,最后一个队列QN(优先级最低的队列)的时间片一般很大(不需要考虑这个问题)。
**多级反馈队列调度算法描述**
1、进程在进入待调度的队列等待时,首先进入优先级最高的Q1等待。
2、首先调度优先级高的队列中的进程。若高优先级中队列中已没有调度的进程,则调度次优先级队列中的进程。例如:Q1,Q2,Q3三个队列,只有在Q1中没有进程等待时才去调度Q2,同理,只有Q1,Q2都为空时才会去调度Q3。
3、对于同一个队列中的各个进程,按照时间片轮转法调度。比如Q1队列的时间片为N,那么Q1中的作业在经历了N个时间片后若还没有完成,则进入Q2队列等待,若Q2的时间片用完后作业还不能完成,一直进入下一级队列,直至完成。
4、在低优先级的队列中的进程在运行时,又有新到达的作业,那么在运行完这个时间片后,CPU马上分配给新到达的作业(抢占式)。
**我们来看一下该算法是如何运作的**
假设系统中有3个反馈队列Q1,Q2,Q3,时间片分别为2,4,8。
现在有3个作业J1,J2,J3分别在时间 0 ,1,3时刻到达。而它们所需要的CPU时间分别是3,2,1个时间片。
1、时刻0 J1到达。于是进入到队列1 , 运行1个时间片 , 时间片还未到,此时J2到达。
2、时刻1 J2到达。 由于时间片仍然由J1掌控,于是等待。 J1在运行了1个时间片后,已经完成了在Q1中的
2个时间片的限制,于是J1置于Q2等待被调度。现在处理机分配给J2。
3、时刻2 J1进入Q2等待调度,J2获得CPU开始运行。
4、时刻3 J3到达,由于J2的时间片未到,故J3在Q1等待调度,J1也在Q2等待调度。
5、时刻4 J2处理完成,由于J3,J1都在等待调度,但是J3所在的队列比J1所在的队列的优先级要高,于是J3被调度,J1继续在Q2等待。
6、时刻5 J3经过1个时间片,完成。
7、时刻6 由于Q1已经空闲,于是开始调度Q2中的作业,则J1得到处理器开始运行。 J1再经过一个时间片,完成了任务。于是整个调度过程结束。
从上面的例子看,在多级反馈队列中,后进的作业不一定慢完成。
路由器收到一个数据包,数据包的目标地址是202.65.17.4,该子网属于哪一个网段?
在登录到别人电脑和登录qq时都不需要DNS进行域名解析的,这就证明网络是没有问题的,但是当你输入的是网址,这样就需要DNS进行域名解析服务,网址登不上去,就证明DNS服务有问题。
c类网络只有最后8位来分配子网号和主机号,每个子网至少容纳55台主机,所以需要6位来分配主机号,只有两位来分配子网号,子网掩码就是255.255.255.11000000;就是255.255.255.192
在网络7层协议中,如果想使用UDP协议达到TCP协议的效果,可以在哪层做文章?
因为UDP要达到TCP的功能就必须实现拥塞控制的功能,而且是在路由之间实现,这个在底层明显是做不到拥塞控制的,在应用层也是做不到的,因为应用层之间和应用程序挂钩,一般只能操控主机的程序,而表示层是处理所有与数据表示及运输有关的问题,包括转换、加密和压缩,在传输层是不可能的,因为你已经使用了UDP协议,无法在本层转换它,只有在会话层.
会话层(SESSION LAYER)允许不同机器上的用户之间建立会话关系。会话层循序进行类似的
传输层 的普通数据的传送,在某些场合还提供了一些有用的增强型服务。允许用户利用一次会话在远端的分时系统上登陆,或者在两台机器间传递文件。 会话层提供的服务之一是管理对话控制。会话层允许信息同时双向传输,或任一时刻只能单向传输。如果属于后者,类似于物理信道上的半双工模式,会话层将记录此时该轮到哪一方
接入WEB服务器第一次被访问到时,不同协议的发生顺序
、当你给WEB服务器接上网线的时候,它会自动发送一条ARP信息,使得接入网关能找的到它;网关上会形成一条类似:2c 96 1e 3c
3e 9b - 192.168.1.123的MAC地址到IP地址的映射记录。
2、如用户在浏览器中输入域名,如本地DNS缓存中没有,必然会进行一次DNS查询,以确定该域名的IP地址。
3、HTTP。获得DNS对应的IP地址以后,使用HTTP协议访问web服务器(不考虑TCP三次握手建立连接的阶段)。
Linux用户分为:拥有者、组群(Group)、其他(other)
linux中的文件属性过分四段,如 -rwzrwz---
第一段 - 是指文件类型 表示这是个普通文件
文件类型部分
-为:表示文件
d为:表示文件夹
b为:表示里面可以供存储周边设备
c为:表示里面为一次性读取装置
第二段 rwz 是指拥有者具有可读可写可执行的权限
类似于windows中的所有者权限比如 administrator 对文件具有 修改、读取和执行权限
第三段 rwz 是指所属于这个组的成员对于这个文件具有,可读可写可执行的权限
类似于windows中的组权限比如administrators组,属于这个组的成员对于文件的都有 可读可写可执行权限
第四段 --- 是指其他人对于这个文件没有任何权限
类似于windows中的 anyone 一样就是说所有人对着个文件都会有一个怎样的权限
</a>
在局域网络内的某台主机用ping命令测试网络连接时发现网络内部的主机都可以连同,而不能与公网连通,问题可能是
局域网的网关或主机的网关设置有误
局域网DNS服务器设置有误
- A.主机IP设置有误的话,内网是无法联通的
- B.玩了个文字游戏吧, 局域网通讯没有网关这一说啊! 网关都是对两个网络来讲才有这一个说法, 同一个网络, 网关不起作用
- C.网关设置有误,不会影响内网的PING,内网只要保证IP在同一个网段就可以ping同。所以此时内网是可以ping通的。但是网关是两个网络之间的一扇门,要想跟外网ping通就必须又打开这扇门的钥匙即网关配置正确。
- D.DNS配置是为的域名解析。跟ping不ping的通无关。
在Linux系统中,/etc/skel你可以存储用于创建用户目录的系统用户默认文件
Linux下的/etc/skel目录往往不被人注意,其实此目录在新建用户时还是很有用的,灵活运用此目录可以节约一定的配置时间。
skel是skeleton的缩写,意为骨骼、框架。故此目录的作用是在建立新用户时,用于初始化用户根目录。系统会将此目录下的所有文件、目录都复制到新建用户的根目录,并且将用户属主与用户组调整为与此根目录相同。所以可将用户配置文件预置到/etc/skel目录下,比如说.bashrc、.profile与.vimrc等。
注:
1.如果在新建用户时,没有自动建立用户根目录,则无法调用到此框架目录。
2.如果不想以默认的/etc/skel目录作为框架目录,可以在运行useradd命令时指定新的框架目录。例如:
sudo useradd -d /home/chen -m -k /etc/my_skel chen
上述命令将新建用户chen,设置用户根目录为/home/chen,并且此目录会自动建立;同时指定框架目录为/etc/my_skel。
3.如果不想在每次新建用户时,都重新指定新的框架目录,可以通过修改/etc/default/useradd配置文件来改变默认的框架目录,方法如下:
查找SKEL变量的定义,如果此变量的定义已被注释掉,可以取消注释,然后修改其值:
SKEL=/etc/my_skel
Nagle算法主要是用来避免大量的小数据包在网络中传输,从而降低网络容量利用率。比如一个20字节的TCP首部+20字节的IP首部+1个字节的数据组成的TCP数据报,有效传输通道利用率只有将近1/40。如果网络充斥着这样的小分组数据,则网络资源的利用率是相当低下的。—— 但是对于一些需要小包场景的程序,比如像telnet或ssh这样的交互性比较强的程序,你需要关闭这个算法。可以在Socket设置TCP_NODELAY选项来关闭这个算法。
格式:sync
强制将内存中的文件缓冲内容写到磁盘。
对一个含有20个元素的有序数组做二分查找,数组起始下标为1,则查找A[2]的比较序列的下标为
(high-low)/2+low = middle; 下标从1开始,因为查找查找A[2], low始终为1;
(20-1)/2+1=10;
(10-1)/2+1 = 5;
(5-1)/2+1 = 3;
(3-1)/2+1 = 2;
一棵Huffman树有m个叶结点,使用struct Node{Node *l,*r;int val;}结构来存储该树中的结点,一共会产生多少个NULL指针?
Huffman树树中没有度为1的节点
所以节点数
n=n0+n1+n2
=n0+n2
=n0+(n0-1)
=2n0-1
=2m-1
一共有2m-1个节点,因此有2m-1-1条边,一条边占用一个指针域,因此被占用的指针域个数为2m-2
2m-1个节点一共有4m-2个指针域
未被占用的指针域个数为4m-2-(2m-2)=2m
最后答案为2m
哈夫曼树没有度为一的节点,有m个叶子节点所以就有2m个空指针