标签:
| 导读 | 很多人在实际的开发中害怕系统的QPS增高,因为觉得QPS太高会导致系统挂掉;基于这种心理会想着尽量的降低系统的请求量,甚至有人会将很多处理放置到服务中来处理,这样外部发一起请求,服务就把所有的业务处理完了。 |
这种方式降低了系统的请求量,但是降低了系统的QPS吗?这种做法系统更安全了还是更危险了?
首先来介绍一下基本概念。
吞吐量指单位时间内系统处理的请求数量,体现系统的整体处理能力。
请求的平均响应时间
一般来说,一个系统的性能收到系统吞吐量和响应时间两个条件的约束,缺一不可。比如,我的系统可以顶得住一百万的并发,但是系统的延迟是2分钟以上,那么,这个一百万的负载毫无意义。系统延迟很短,但是吞吐量很低,同样没有意义。
一般情况下,针对一个系统
• 吞吐量(Throughput)越大,系统延迟(Latency)越差。因为请求量过大,系统太繁忙,所以响应速度自然会低。
• 系统延迟(Latency)越好,能支持的吞吐量(Throughput)就会越高。因为Latency短说明处理速度快,于是就可以处理更多的请求。
• 并发数
系统同时能够处理的请求数/事务数。
• QPS(也称TPS,Query per second/transaction per second)
并发数/响应时间
整体来看QPS能够概括系统吞吐量和延迟两方面指标,因此也是系统最重要的指标之一。但当系统的QPS升高,到底会对系统产生哪些影响,或者在我们如何避免QPS升高而对系统造成的危害呢?
我们紧接这来看看服务化系统的主要模式及系统资源的消耗。
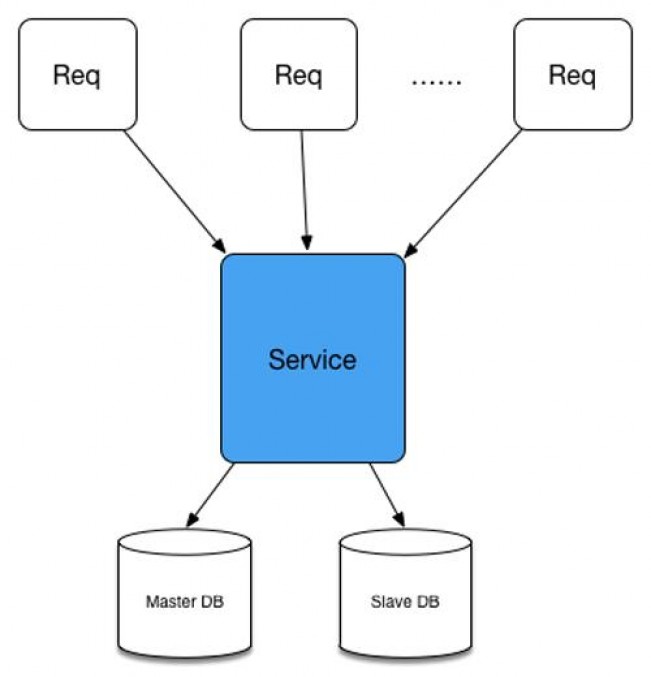
一个最基础的服务,一般就包含两种操作:业务逻辑处理和DB的读写。
当一个请求发过来的时候,会消耗哪些系统资源呢?
请求对系统资源的占用
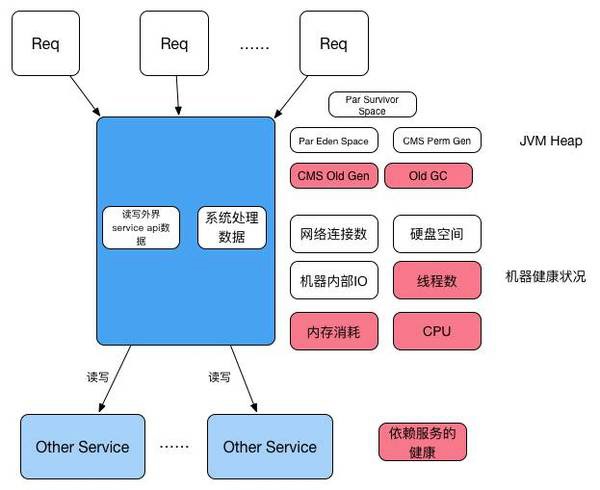
当一个请求发过来之后,常规的这个请求会消耗一下资源:CPU(负责计算)、系统内存、网络链接等系统自身资源;如果我们的系统是基于Java的,那还涉及到JVM资源的占用,JVM的heap和stack资源,其中Heap是更重要的指标。如果在这个请求需要与DB有交互,在连接DB进行操作的过程中,会消耗系统的数据库链接池资源。对应的在DB侧,会消耗DB的计算资源,而DB的计算最重要的指标就是DB的响应时间和DB的连接数。
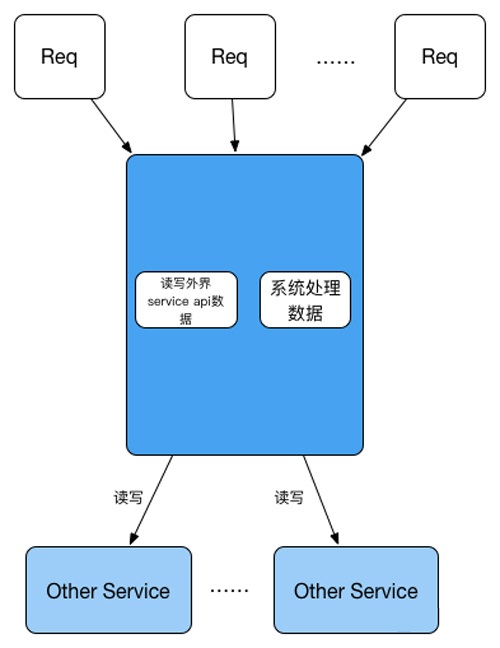
这种服务相对基础服务是另一个极端,这种服务只依赖与其他的服务,并没有自己的数据。
请求对系统资源的占用
在这个系统里面,我们可以将依赖服务当作DB来看待,只不过在请求的过程中不再消耗系统的数据库连接池资源。
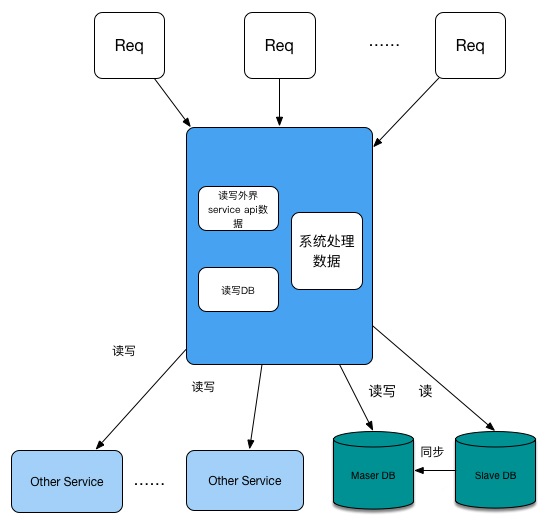
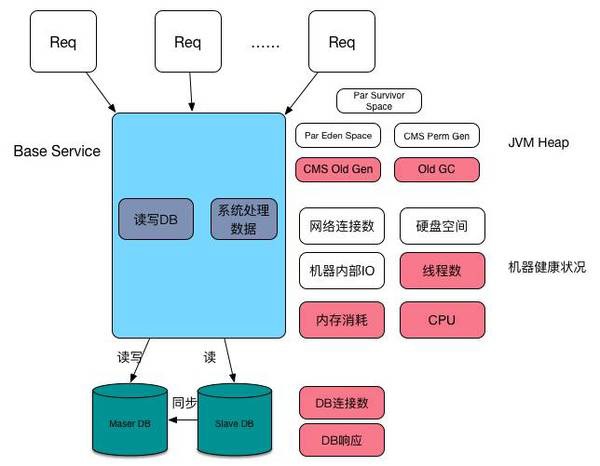
这种系统结构是我们最常用的结构,既有自身的业务数据,也会有部分计算依赖与其他服务。
混合服务的资源消耗
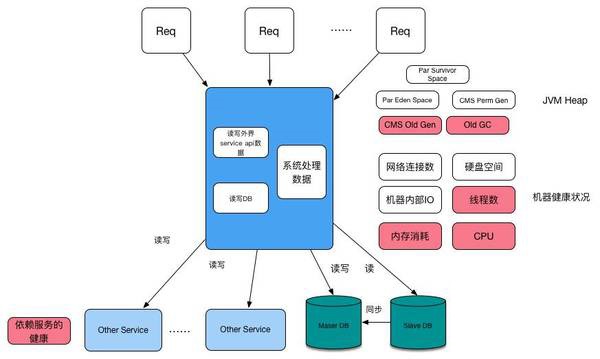
这种结构里面会集成上面两种结构的系统消耗。
系统负载
如果系统的CPU使用率已经很高,说明我们的系统是个计算度很复杂的系统,这时候如果QPS已经上不去了,就需要赶紧扩容,通过增加机器分担计算的方式来提高系统的吞吐量。
如果CPU使用率一般,但是系统的QPS已经负载不了了,说明我们的机器并没有忙于计算,而是收到其他资源的限制,如内存或者io。这时候首先看下内存是不是已经不够了,如果内存不够了,那就赶紧扩容了。
针对Java项目来说,JVM中Heap信息也是内存的一个直接反应,如Java的老年代的内存占比,是否发生Full GC的情况等。
系统的IO一般是和CPU使用率相反的,CPU利用率高的时候,IO使用率就不大,而IO使用率高的时候CPU一般利用率不高。
当我们自身系统的网络带宽被占用完毕的时候,相当于把系统的入口和出口给堵死了,这时候外界的需求排不进来了,QPS自然上不去。
在我们的系统中时常会使用连接池的方式来连接DB,也会使用HTTP连接池的方式向依赖系统发起服务,或者使用线程池的方式提供给其他服务使用。很多时候因为系统的本身连接池自身有最大连接数的限制,会导致系统连接数耗尽,单系统其他资源依然属于正常情况。这时候可以适当增加连接数的方式,来增加系统的吞吐能力,但这种方法需要慎重,因为过多的连接池,会更快的消耗系统资源,并且会将压力传递给依赖系统。
依赖系统的性能
DB性能很多时候是系统的根本,因为一旦DB出现了大问题,不单单会导致一个系统出问题,很可能会导致所有依赖此DB的系统出现业务逻辑问题。
一般开发在实践中,遇到最多的问题就是不当的SQL导致DB读写性能很低,如未使用索引的读写SQL;如数据库表不适当的锁范围;另外,如果DB本身的读写已经达到了自身的限度,这时候可以考虑更换机器,更换系统的硬盘,或者增加读库等方法,但这方面的优化内容非常复杂,在后面会有专门的篇幅来讨论。
如果上面所说的系统自身指标和依赖系统的指标都相对正常,但系统的QPS依然无法负载,说明系统内部出现问题,如系统被阻塞了。
在进行系统优化之前需要进行Profile测试分析,根据2:8原则来说,20%的代码耗了你80%的性能,找到那20%的代码,你就可以优化那80%的性能。
调用依赖服务时,采用异步并行的方式调用,将多个耗时的请求合并发出,可以降低很多无谓的等待时间。
针对其他需要进行文件读写的操作,建议使用异步化的方式,降低阻塞的可能。
过大的request和response会增加网络带宽的压力,且过大的字节传入容易造成数据丢失。
这个是在互联网服务中最常用的优化方式了,在此不再详述。
有人说,thread is evil,因为多线程瓶颈就在于互斥和同步的锁上,以及线程上下文切换的成本,怎么样的少用锁或不用锁是根本。另外在系统中使用线程池时,避免因为使用线程池模式和数量限制设置不当,而成为系统瓶颈。
并发情况下,锁是非常非常影响性能的。各种隔离级别,行锁,表锁,页锁,读写锁,事务锁,以及各种写优先还是读优先机制。性能最高的是不要锁,所以,分库分表,冗余数据,减少一致性事务处理,可以有效地提高性能。
在读写数据的时候都需要在where条件中检查索引的使用。
SQL中的join操作对索引的优化是个很复杂的问题,因为互联网的项目经常会发生变化,针对数据表的索引也会不断优化,如果使用join很可能会无法正确索引;且SQL级的索引的功能维护性也非常差。
在查询上增加适当的limit

标签:
原文地址:http://www.cnblogs.com/linux130/p/5876665.html