标签:
Spark Streaming
Spark Streaming 是Spark为了用户实现流式计算的模型。
数据源包括Kafka,Flume,HDFS等。

DStream 离散化流(discretized stream), Spark Streaming 使用DStream作为抽象表示。是随时间推移而收到的数据的序列。DStream内部的数据都是RDD形式存储, DStream是由这些RDD所组成的离散序列。
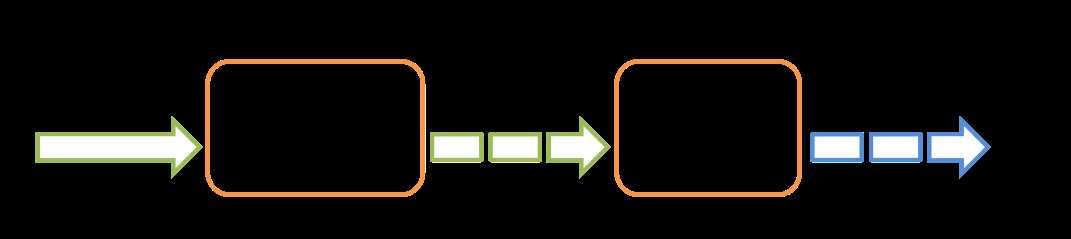
编写Streaming步骤:
1.创建StreamingContext
// Create a local StreamingContext with two working thread and batch interval of 5 second.
// The master requires 2 cores to prevent from a starvation scenario.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
创建本地化StreamingContext, 需要至少2个工作线程。一个是receiver,一个是计算节点。
2.定义输入源,创建输入DStream
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("node1", 9999)
3.定义流的计算过程,使用transformation和output operation DStream
// Split each line into words val words = lines.flatMap(_.split(" ")) // Count each word in each batch val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKey(_ + _) // Print the first ten elements of each RDD generated in this DStream to the console wordCounts.print()
4.开始接收数据及处理数据,使用streamingContext.start()
ssc.start() // Start the computation
5.等待批处理被终止,使用streamingContext.awaitTermination()
ssc.awaitTermination() // Wait for the computation to terminate
6.可以手工停止批处理,使用streamingContext.stop()
数据源
数据源分为两种
1.基本源
text,HDFS等
2.高级源
Flume,Kafka等
DStream支持两种操作
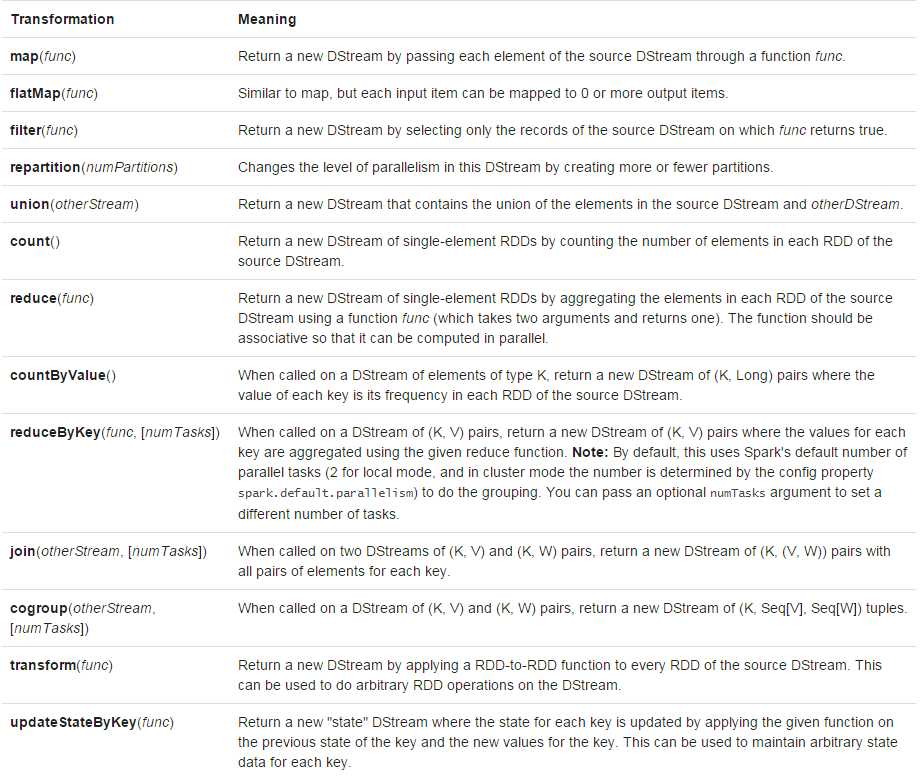
无状态转化(stateless):每个批次的处理不依赖于之前批次的数据
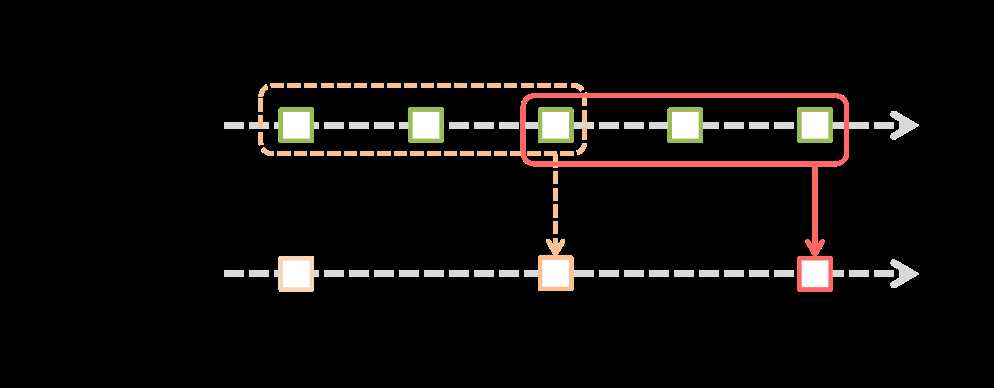
有状态转化(stateful):跨时间区间跟踪数据的操作;一些先前批次的数据被用来在新的批次中参与运算。
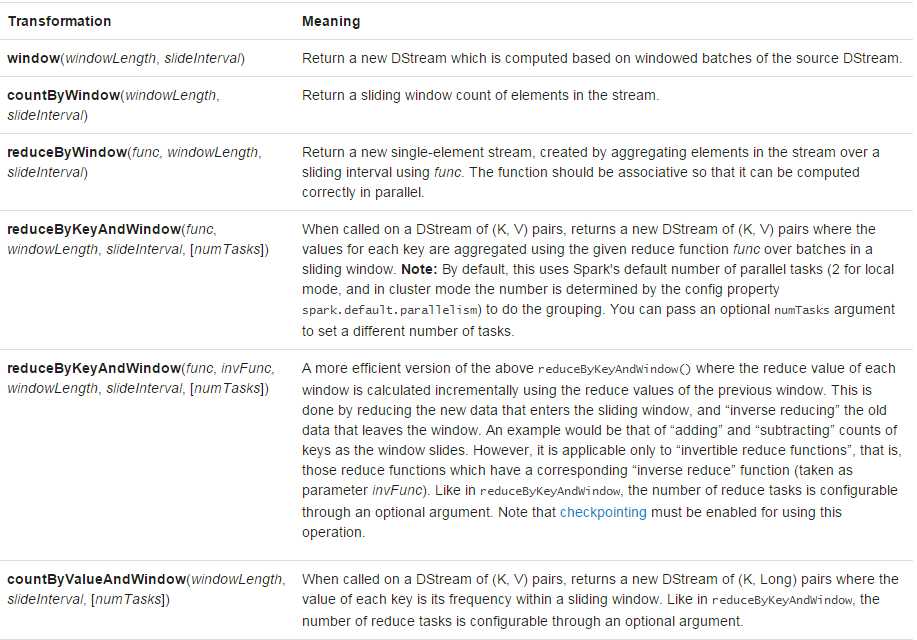
窗口函数

标签:
原文地址:http://www.cnblogs.com/one--way/p/5877552.html