标签:
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
它有3个基本性质:
可以看出:
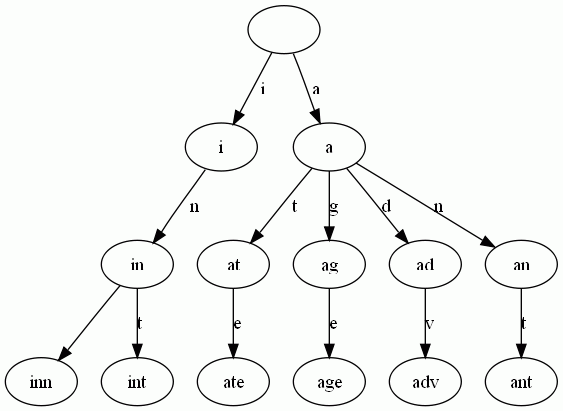
查询操纵非常简单。比如要查找int,顺着路径i -> in -> int就找到了。
搭建Trie的基本算法也很简单,无非是逐一把每则单词的每个字母插入Trie。插入前先看前缀是否存在。如果存在,就共享,否则创建对应的节点和边。比如要插入单词add,就有下面几步:
public class TrieST<Value> {
private static final int R = 256; // extended ASCII
private Node root; // root of trie
private int n; // number of keys in trie
// R-way trie node
private static class Node {
private Object val;
private Node[] next = new Node[R];
}
/**
* Initializes an empty string symbol table.
*/
public TrieST() {
}
/**
* Returns the value associated with the given key.
* @param key the key
* @return the value associated with the given key if the key is in the symbol table
* and {@code null} if the key is not in the symbol table
* @throws NullPointerException if {@code key} is {@code null}
*/
public Value get(String key) {
Node x = get(root, key, 0);
if (x == null) return null;
return (Value) x.val;
}
/**
* Does this symbol table contain the given key?
* @param key the key
* @return {@code true} if this symbol table contains {@code key} and
* {@code false} otherwise
* @throws NullPointerException if {@code key} is {@code null}
*/
public boolean contains(String key) {
return get(key) != null;
}
private Node get(Node x, String key, int d) {
if (x == null) return null;
if (d == key.length()) return x;
char c = key.charAt(d);
return get(x.next[c], key, d+1);
}
/**
* Inserts the key-value pair into the symbol table, overwriting the old value
* with the new value if the key is already in the symbol table.
* If the value is {@code null}, this effectively deletes the key from the symbol table.
* @param key the key
* @param val the value
* @throws NullPointerException if {@code key} is {@code null}
*/
public void put(String key, Value val) {
if (val == null) delete(key);
else root = put(root, key, val, 0);
}
private Node put(Node x, String key, Value val, int d) {
if (x == null) x = new Node();
if (d == key.length()) {
if (x.val == null) n++;
x.val = val;
return x;
}
char c = key.charAt(d);
x.next[c] = put(x.next[c], key, val, d+1);
return x;
}
/**
* Returns the number of key-value pairs in this symbol table.
* @return the number of key-value pairs in this symbol table
*/
public int size() {
return n;
}
/**
* Is this symbol table empty?
* @return {@code true} if this symbol table is empty and {@code false} otherwise
*/
public boolean isEmpty() {
return size() == 0;
}
/**
* Returns all keys in the symbol table as an {@code Iterable}.
* To iterate over all of the keys in the symbol table named {@code st},
* use the foreach notation: {@code for (Key key : st.keys())}.
* @return all keys in the symbol table as an {@code Iterable}
*/
public Iterable<String> keys() {
return keysWithPrefix("");
}
/**
* Returns all of the keys in the set that start with {@code prefix}.
* @param prefix the prefix
* @return all of the keys in the set that start with {@code prefix},
* as an iterable
*/
public Iterable<String> keysWithPrefix(String prefix) {
Queue<String> results = new Queue<String>();
Node x = get(root, prefix, 0);
collect(x, new StringBuilder(prefix), results);
return results;
}
private void collect(Node x, StringBuilder prefix, Queue<String> results) {
if (x == null) return;
if (x.val != null) results.enqueue(prefix.toString());
for (char c = 0; c < R; c++) {
prefix.append(c);
collect(x.next[c], prefix, results);
prefix.deleteCharAt(prefix.length() - 1);
}
}
/**
* Returns all of the keys in the symbol table that match {@code pattern},
* where . symbol is treated as a wildcard character.
* @param pattern the pattern
* @return all of the keys in the symbol table that match {@code pattern},
* as an iterable, where . is treated as a wildcard character.
*/
public Iterable<String> keysThatMatch(String pattern) {
Queue<String> results = new Queue<String>();
collect(root, new StringBuilder(), pattern, results);
return results;
}
private void collect(Node x, StringBuilder prefix, String pattern, Queue<String> results) {
if (x == null) return;
int d = prefix.length();
if (d == pattern.length() && x.val != null)
results.enqueue(prefix.toString());
if (d == pattern.length())
return;
char c = pattern.charAt(d);
if (c == ‘.‘) {
for (char ch = 0; ch < R; ch++) {
prefix.append(ch);
collect(x.next[ch], prefix, pattern, results);
prefix.deleteCharAt(prefix.length() - 1);
}
}
else {
prefix.append(c);
collect(x.next[c], prefix, pattern, results);
prefix.deleteCharAt(prefix.length() - 1);
}
}
/**
* Returns the string in the symbol table that is the longest prefix of {@code query},
* or {@code null}, if no such string.
* @param query the query string
* @return the string in the symbol table that is the longest prefix of {@code query},
* or {@code null} if no such string
* @throws NullPointerException if {@code query} is {@code null}
*/
public String longestPrefixOf(String query) {
int length = longestPrefixOf(root, query, 0, -1);
if (length == -1) return null;
else return query.substring(0, length);
}
// returns the length of the longest string key in the subtrie
// rooted at x that is a prefix of the query string,
// assuming the first d character match and we have already
// found a prefix match of given length (-1 if no such match)
private int longestPrefixOf(Node x, String query, int d, int length) {
if (x == null) return length;
if (x.val != null) length = d;
if (d == query.length()) return length;
char c = query.charAt(d);
return longestPrefixOf(x.next[c], query, d+1, length);
}
/**
* Removes the key from the set if the key is present.
* @param key the key
* @throws NullPointerException if {@code key} is {@code null}
*/
public void delete(String key) {
root = delete(root, key, 0);
}
private Node delete(Node x, String key, int d) {
if (x == null) return null;
if (d == key.length()) {
if (x.val != null) n--;
x.val = null;
}
else {
char c = key.charAt(d);
x.next[c] = delete(x.next[c], key, d+1);
}
// remove subtrie rooted at x if it is completely empty
if (x.val != null) return x;
for (int c = 0; c < R; c++)
if (x.next[c] != null)
return x;
return null;
}
}
标签:
原文地址:http://www.cnblogs.com/wxgblogs/p/5878956.html