标签:
从数据库中读取数据,具体操作为:
# -*- coding: utf-8 -*- from numpy import * import numpy as np import pandas as pd from sqlalchemy import create_engine engine = create_engine(‘mysql+pymysql://root:123456@127.0.0.1:3306/db_websiterecommend?charset=utf8‘) sql = pd.read_sql(‘t_url_classify‘, engine, chunksize = 110000) output=‘C:\\Users\\lenovo\\Desktop\\count_.xls‘ ‘‘‘z 用create_engine建立连接,连接地址的意思依次为“数据库格式(mysql)+程序名(pymysql)+账号密码@地址端口/数据库名(test)”,最后指定编码为utf8; all_gzdata是表名,engine是连接数据的引擎,chunksize指定每次读取1万条记录。这时候sql是一个容器,未真正读取数据。 ‘‘‘ counts = [ i[‘classify‘].value_counts() for i in sql] #逐块统计 counts = pd.concat(counts).groupby(level=0).sum() #合并统计结果,把相同的统计项合并(即按index分组并求和) counts = counts.reset_index() #重新设置index,将原来的index作为counts的一列。 counts.columns = [‘type‘, ‘num‘] counts=pd.DataFrame(counts) print(counts) import matplotlib.pyplot as plt plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘] plt.rcParams[‘axes.unicode_minus‘]=False print(counts.type) print(counts.num) #plt.style.use(‘mystyle‘) x=np.arange(counts.type.size) plt.bar(x,counts.num,color=‘red‘) ax=plt.gca() ax.set_xticklabels(counts.type) plt.show()
画图的代码为:
import matplotlib.pyplot as plt plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘] plt.rcParams[‘axes.unicode_minus‘]=False print(counts.type) print(counts.num) #plt.style.use(‘mystyle‘) x=np.arange(counts.type.size) plt.bar(x,counts.num,color=‘red‘) ax=plt.gca() ax.set_xticklabels(counts.type) plt.show()
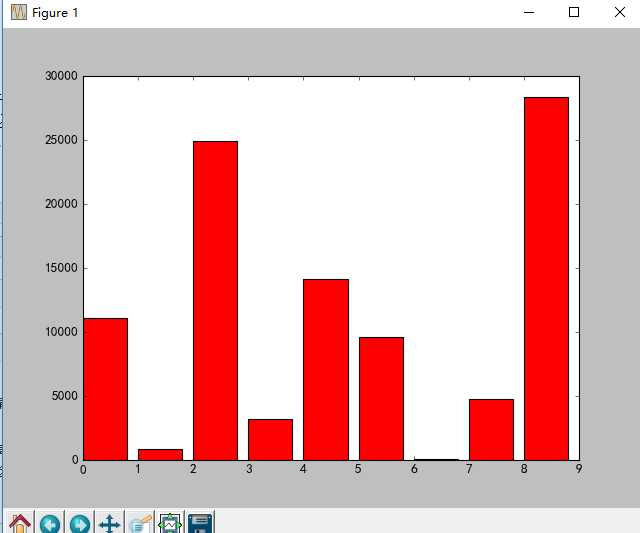
ax=plt.gca()
ax.set_xticklabels(counts.type)
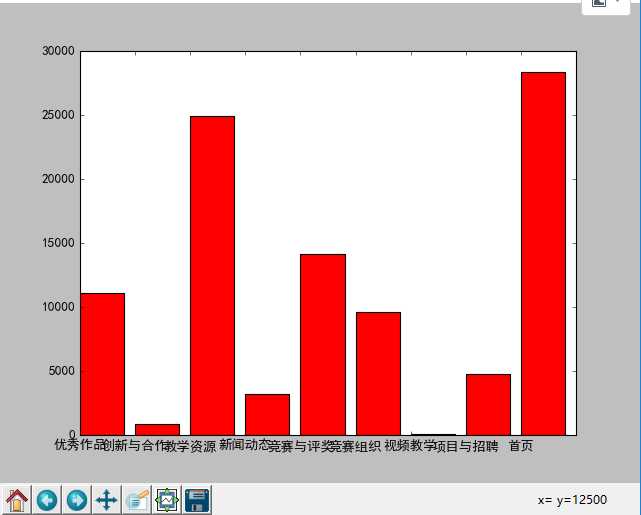
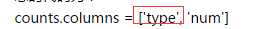

counts.plot(kind=‘bar‘,color=‘red‘) ax=plt.gca() ax.set_xticklabels(counts.type) plt.show()

标签:
原文地址:http://www.cnblogs.com/caicaihong/p/5887845.html