标签:
哈希表基础知识
哈希法又称散列法、杂凑法以及关键字地址计算法等,相应的表称为哈希表,是基于快速存取的角度设计的,也是一种典型的“空间换时间”的做法。
其基本思想是:首先在元素的关键字k和元素的存储位置p之间建立一个对应关系f,使得p=f(k),f称为哈希函数。创建哈希表时,把关键字为k的元素直接存入地址为f(k)的单元;以后当查找关键字为k的元素时,再利用哈希函数计算出该元素的存储位置p=f(k),从而达到按关键字直接存取元素的目的。
但关键字集合很大时,关键字值不同的元素可能会映射到哈希表的同一地址上,即k1!=k2,但H(k1)==H(k2),这种现象称为冲突,此时称k1和k2为同义词。实际中,冲突是不可避免的,但是可以通过一些方法减少冲突。
综上所述,哈希法主要包括两方面内容:
1) 如何构造哈希函数
2) 如何处理冲突
哈希函数的构造方法:
注意事项:
1) 哈希函数的构造不是越复杂越好,因为往往哈希函数越复杂,取得关键字地址所消耗的时间越长,可能对哈希法性能造成一定的影响,因此选取哈希函数的时候,应该多方面权衡,选择合适的哈希函数(即不存在特别好与坏的哈希函数,需视情况而定)。
2) 哈希函数有一个共同的性质,即哈希值应当以同等概率取其值域的每个值。
常用的构造哈希函数的方法:
1) 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即H(key) = key或H(key) = a * key + b,其中a和b为常数(这种散列函数叫做自身函数)。
2) 数字分析法:分析一组数据,比如某班学生的出生年月日时发现出生年月日的前几位数字大体相同,这样的话,冲突的几率会很大,但是发现年月日的后几位表示月份和具体日期的数字差别比较大,如果用后几位构成散列地址,则冲突的几率会明显降低。因此数字分析法是找出数字的规律,尽可能利用这些数字构造冲突几率低的散列地址。
3) 平方取中法:先通过求关键字的平方值扩大相近数的差别,然后根据表长度取中间的几位数作为散列函数值。又因为一个乘积的中间几位数和乘数的每一位都相关,所以由此产生的散列地址较为均匀。
4) 除余法:该方法是最为简单常用的一种方法。它是以表长m来除关键字,取其余数作为散列地址,即 h(key) = key % m。
该方法的关键是选取m。选取的m应使得散列函数尽可能与关键字的各位相关。m最好为素数。
5) 相乘取整法:该方法包括两个步骤:首先用关键字key乘上某个常数A(0<A<1),并抽取出key.A的小数部分;然后用m乘以该小数后取整。即:
该方法最大的优点是选取m不再像除余法那样关键。比如,完全可选择它是2的整数次幂。虽然该方法对任何A的值都适用,但对某些值效果会更好。
6) 折叠法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。
7) 随机数法:选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。
8) 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key % p, p<=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。
处理冲突的方法:
常用的处理冲突的方法:
1) 开放定址法:以关键字K的哈希地址P=H(K)出现冲突时,以P为基础重新产生一个哈希地址P1,如果还是冲突则重复上述动作知道不冲突为止。
这种方法有一个通用的再散列函数形式:
Hi = (H(key) + di) % m (i = 1, 2, ..., n)
其中H(key)为哈希函数,m为表长,di为增量序列。增量序列的取值方式不同,相应的再散列方式也不同
具体的散列的方法有:
a) 线性探测再散列:冲突发生时就简单的顺序查看下一个相邻存储单元是否可用,重复该动作直到找到可用地址为止。
di = 1, 2, 3, ... , m-1
这种方法的特点是:冲突发生时,顺序查看表中的下一个单元,直到找出一个空单元或查遍全表。
b) 二次探测再散列的方法:冲突发生是进行左右跳跃式的查找可用存储单元,重复该动作直到找到可用存储单元为止。
di = 12 ,-12, 22, -22, ..., k2, -k2 (k <= m/2)
这种方法的特点是:冲突发生时,在表的左右进行跳跃式探测,比较灵活。
c) 伪随机探测再散列:通过一个伪随机数发生器给定一个随机数作为新的起点查找。
di = 伪随机序列
2) 拉链法:把所有同义词,即hash值相同的记录,用单链表连接起来。
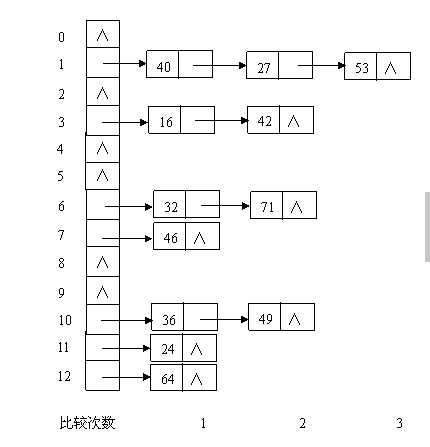
例如,已知一组关键字(30, 40, 36, 53, 16, 46, 71, 27, 42, 24, 49, 64),哈希表长度为13,哈希函数为:H(key) = key % 13,则用拉链法处理冲突的结果如下图所示:
3) 再哈希法:这种方法是同时构造多个不同的哈希函数:
Hi = RH1(key) i = 1, 2, ..., k
当哈希地址Hi = RH1(key)发生冲突时,再计算Hi = RH2(key), ..., 直到不再产生冲突。
这种方法的特点是:不易产生聚集,但增加了计算时间。
4) 建立一个公共溢出区:这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
哈希法的性能分析:
平均查找长度ASL
影响因素:
1) 计算哈希函数所需时间
2) 关键字长度
3) 哈希表大小
4) 关键字的分布情况
5) 记录查询频率
后面两个比较系统,自行查看严蔚敏老师的《数据结构》一书即可解惑。
参考资料:
http://blog.csdn.net/u013074465/article/details/45059639
http://www.360doc.com/content/14/0721/09/16319846_395862328.shtml
严蔚敏 《数据结构》
标签:
原文地址:http://www.cnblogs.com/skcxy/p/5890706.html