标签:
四、 How Can Machines Learn Better?
我个人感觉第四讲是整个基石课程的精髓所在,很多东西说的很深也很好。
首先是overfitting的问题,过拟合是一个常发生的情况,简单的理解就是下图,low Ein不一定是好事,因为我们的目的是low Eout。所以不能过拟合你的训练集是每个machine learning工程师需要注意的事情。
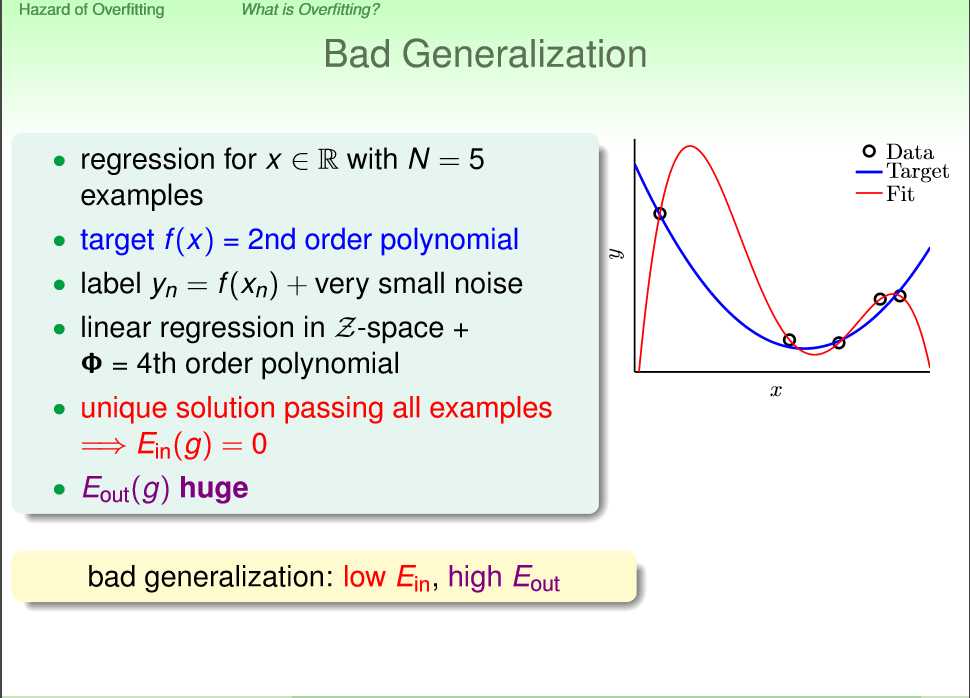
overfitting简单的理解就是:学习的人太厉害,而需要学习的知识太简单,如上图,你用一个5次的函数去学习这样一个数据集,实在是大材小用了。
当然影响overfitting的还有其他因素,总的来说要避免overfitting我们需要做到:1、很少的噪声数据 2、适合的dvc 3、足够多的数据。
下图是一个悲伤的故事,我们知道十次函数的学习能力肯定远远的超过二次函数,但似乎在这两种情况下,它的表现都很令人捉鸡...
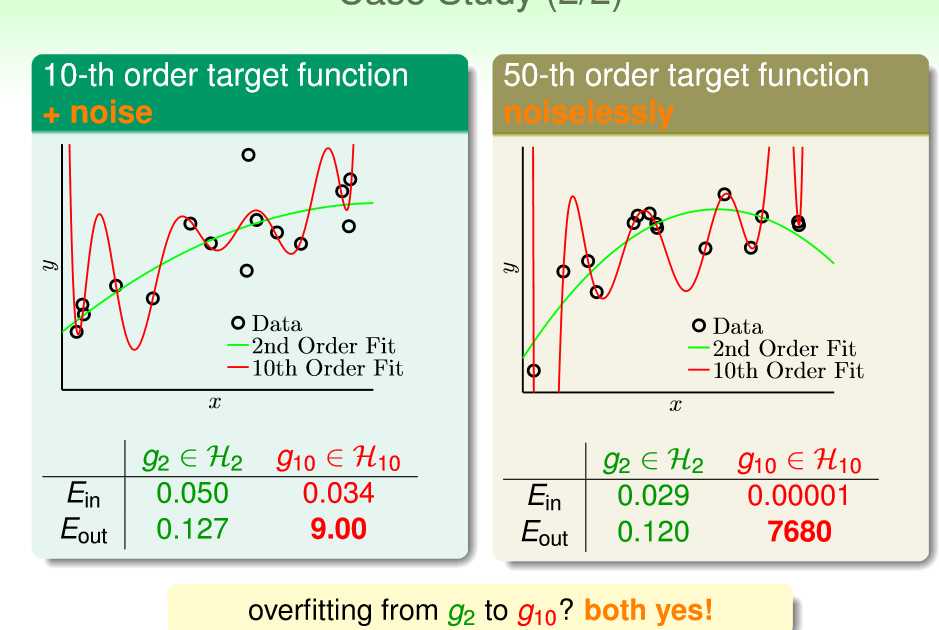
Why?如果你还记得之前的学习曲线和公示的话大概就会清楚了,如下图所示,需要注意的是,这一切都建立在N比较小的时候。
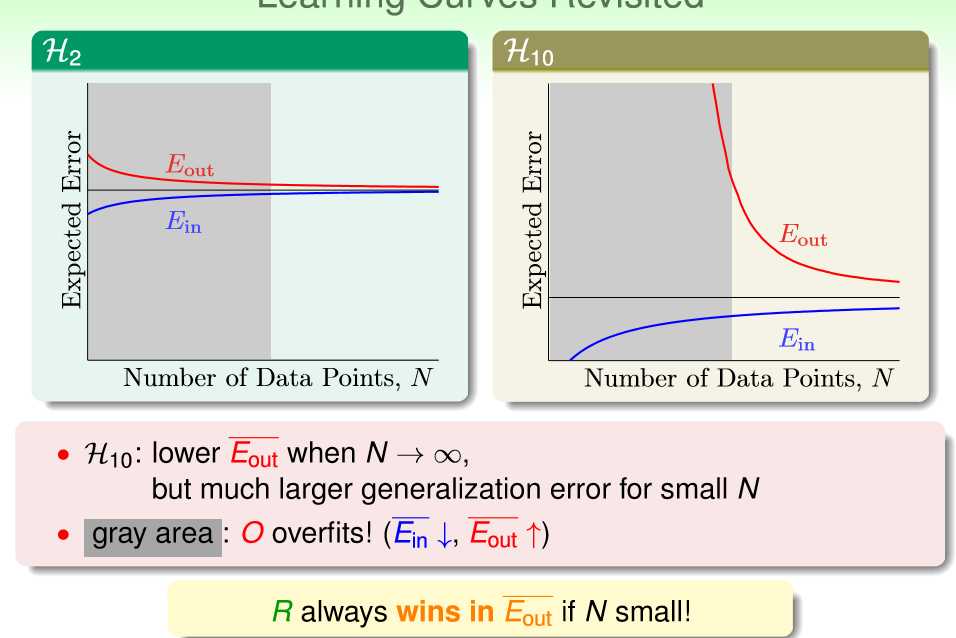
需要注意的是,我们通常可能认为g10不如g2的时候,是因为它对噪声的影响太过敏感了,而事实上在完全没有噪声的数据上,他也是完败的,这里引出来的问题是,真的没有“噪声”么?或许目标的复杂度一定程度上也可以看做噪声?
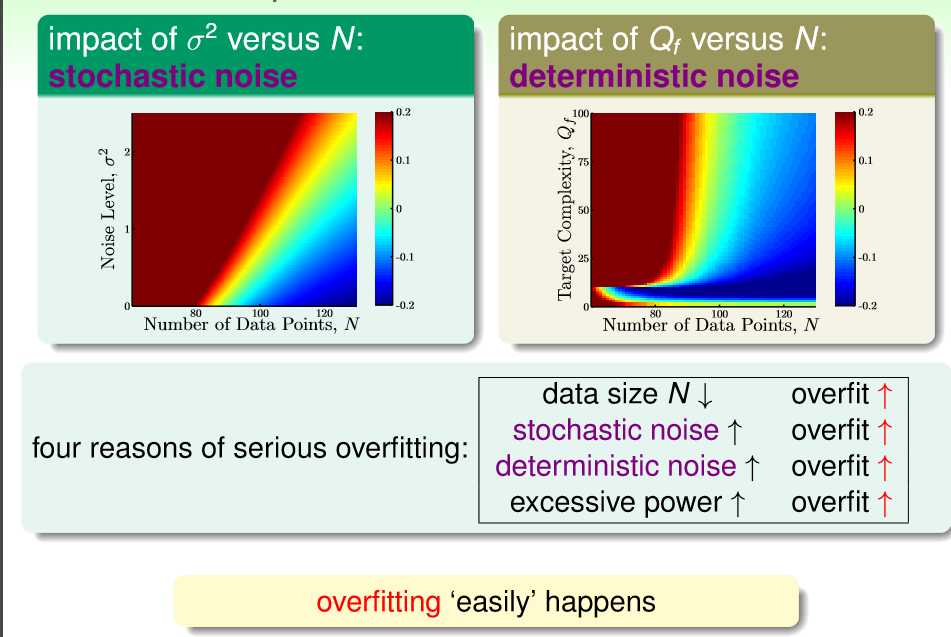
In fact,我们可以把噪声分为两类,stichastic noise,真实世界产生的噪声数据,deterministic noise,由模型的复杂度引起的噪声数据,后者简单的理解就是,我用10次多项式去拟合一个由50次多项式产生的数据,肯定有很多地方我是做不到拟合的,那么那些数据从某种意义上来说,就是噪声。
下图蓝色表示好,红色表示很差。左图很好理解,右图在左下角需要解释一下。因为目标函数是一个十次函数产生的数据,所以在模型的复杂度从10往下走的时候,表现的会越来差。因为当你用10次多项式的函数去拟合小于10次的目标函数的时候,表现的当然回事overftting
标签:
原文地址:http://www.cnblogs.com/daihengchen/p/5899903.html