标签:
之前我们在做例子的时候,我们看到过这种捕获的形式,我们也试过反向引用。那像我们捕获的内容,可以通过一个正则表达式的模式,或者部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。每个缓冲区都可以使用 ‘\n‘ 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。当然,如果我们不想捕获我们的文本,可以使用非捕获元字符 ‘?:‘、‘?=‘ 或 ‘?!‘ 来重写捕获,忽略对相关匹配的保存。
捕获
(exp)
匹配exp,并捕获文本到自动命名的组里。
(?<name>exp)
匹配exp,并捕获文本到名称为name的组里,可以写成(?‘name‘exp),使用命名捕获分组可以通过\k<name>进行引用。
(?:exp)
匹配exp,不捕获匹配的文本,也不给此组分配组号。
示例
捕获和非捕获的例子。
<?php
header(‘content-type:text/html;charset=utf-8‘);
echo ‘<pre>‘;
//捕获和非捕获的例子
$subject=‘2016-05-01‘;
$pattern=‘#(\d{4})-(\d{2})-(\d{2})#‘;
preg_match($pattern, $subject,$matches);
print_r($matches);
echo ‘</pre>‘;
得到的结果,这是我们匹配到的内容。
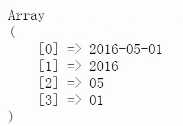
<?php
header(‘content-type:text/html;charset=utf-8‘);
$replacement=‘\2\3\1‘;
echo preg_replace($pattern, $replacement, $subject);
echo ‘<hr/>‘;
结果。
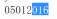
要使用分隔符的话。
<?php
header(‘content-type:text/html;charset=utf-8‘);
$replacement=‘\2-\3-\1‘;
echo preg_replace($pattern, $replacement, $subject);
echo ‘<hr/>‘;
结果。
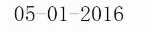
使用$形式。
<?php
header(‘content-type:text/html;charset=utf-8‘);
$replacement=‘$2-$3-$1‘;
echo preg_replace($pattern, $replacement, $subject);
echo ‘<hr/>‘;
使用命名捕获分组的形式。
<?php
header(‘content-type:text/html;charset=utf-8‘);
//使用命名捕获分组的形式,好处是调用结果比较方便,可以根据起的名字进行调用
$subject=‘2016-05-01‘;
$pattern=‘#(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})#‘;
preg_match($pattern, $subject,$matches);
print_r($matches);
echo ‘<hr/>‘;
结果。

另外的命名形式。
<?php
header(‘content-type:text/html;charset=utf-8‘);
$subject=‘000000‘;
$pattern=‘#(?<n>0{3})#‘;
preg_match($pattern, $subject,$matches);
print_r($matches);
结果,匹配到了3个0,存储到了我们的n中。
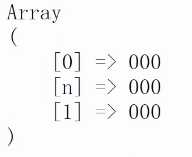
想反向引用一下。
<?php
header(‘content-type:text/html;charset=utf-8‘);
$subject=‘000000‘;
$pattern=‘#(?<n>0{3})#‘;
$pattern=‘#(?<n>0{3})\k<n>#‘; //引用到第一个里面匹配到的内容
preg_match($pattern, $subject,$matches);
print_r($matches);
结果,下面是我们匹配到的内容。
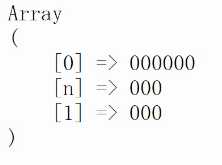
还可以使用这种方式进行,引用效果是一样的。
<?php
header(‘content-type:text/html;charset=utf-8‘);
$subject=‘000000‘;
$pattern=‘#(?<n>0{3})#‘;
$pattern="#(?<n>0{3})\k‘n‘#"; //引用到第一个里面匹配到的内容
preg_match($pattern, $subject,$matches);
print_r($matches);
结果一样,并没有变。
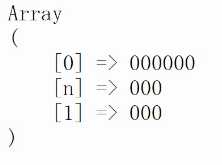
另外一种引用方式,效果一样。
<?php
header(‘content-type:text/html;charset=utf-8‘);
$subject=‘000000‘;
$pattern=‘#(?<n>0{3})#‘;
$pattern=‘#(?<n>0{3})\g{n}#‘; //引用到第一个里面匹配到的内容
preg_match($pattern, $subject,$matches);
print_r($matches);
结果。
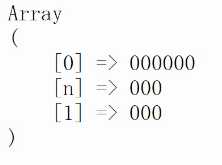
另外一种引用方式,效果一样。
<?php
header(‘content-type:text/html;charset=utf-8‘);
$subject=‘000000‘;
$pattern=‘#(?<n>0{3})#‘;
$pattern=‘#(?<n>0{3})\k{n}#‘; //引用到第一个里面匹配到的内容
preg_match($pattern, $subject,$matches);
print_r($matches);
结果。
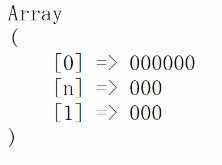
另外一种形式的命名分组。
<?php
header(‘content-type:text/html;charset=utf-8‘);
//另外一种形式的命名分组
$pattern=‘#(?P<name>0{3})(?P=name)#‘;
preg_match($pattern, $subject,$matches);
print_r($matches);
echo ‘<hr/>‘;
得到的结果也是一样的。
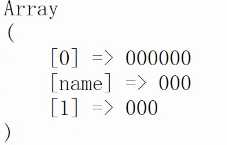
实现ubb的效果。
<?php
header(‘content-type:text/html;charset=utf-8‘);
//[url]1.jpg[/url] [url]2.jpg[/url]
$subject=‘[url]1.jpg[/url][url]2.jpg[/url]‘; //在这里已经拷好了两张图片
echo preg_replace(‘#\[url\](\d+\.jpg)\[/url\]#‘, ‘<img src="$1" />‘, $subject);
结果,这样的效果已经实现了我们的替换。

假如我们不想把我们匹配的内容放到我们的分组里,也是可以的,也就是我们的非捕获分组。
<?php
header(‘content-type:text/html;charset=utf-8‘);
//非捕获分组,
echo ‘<hr/>‘;
$subject=‘hello king‘;
$pattern=‘#hello (world|king|maizi)#i‘;
preg_match($pattern, $subject,$matches);
print_r($matches);
结果,下面有个1,代表放在我们的内存当中。

假如我们不想放在内存当中。
<?php
header(‘content-type:text/html;charset=utf-8‘);
//非捕获分组,?:代表我们不匹配,也就是不放在我们的内存当中,这样也能提高我们的性能
echo ‘<hr/>‘;
$subject=‘hello king‘;
$pattern=‘#hello (world|king|maizi)#i‘;
preg_match($pattern, $subject,$matches);
print_r($matches);
结果,现在就没有放了。
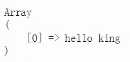
原子分组, 好处是对组内的内容不进行回溯操作,说到回溯操作,它也是影响我们性能的一个,因为回溯操作会尝试每一种可能性,这样就会消耗时间去计算我们的资源,有时候我们正则很复杂,它就会占用大量的时间,有时候我们也可以把它叫做灾难性的操作。原子分组可以关闭我们的部分回溯操作,因为我们只针对原子分组内的部分内容,不是整个表达式,我们也可以通过其他操作,完全关闭我们的回溯操作。
<?php
header(‘content-type:text/html;charset=utf-8‘);
/*原子分组(?>)*/
echo ‘<hr/>‘;
$subject=‘hello king‘;
$pattern=‘#hello (?>world|king|maizi)#i‘;
preg_match($pattern, $subject,$matches);
print_r($matches);
echo ‘</pre>‘;
结果,匹配到了,但是它也没有进行回溯操作,而且没有把我们的子模式放到分组里。

文章来源:麦子学院
原文链接:http://www.maiziedu.com/wiki/phptop/capture/
标签:
原文地址:http://www.cnblogs.com/maizi008/p/5901129.html