标签:
将Mahout on Spark 中的机器学习算法和MLlib中支持的算法统计如下:
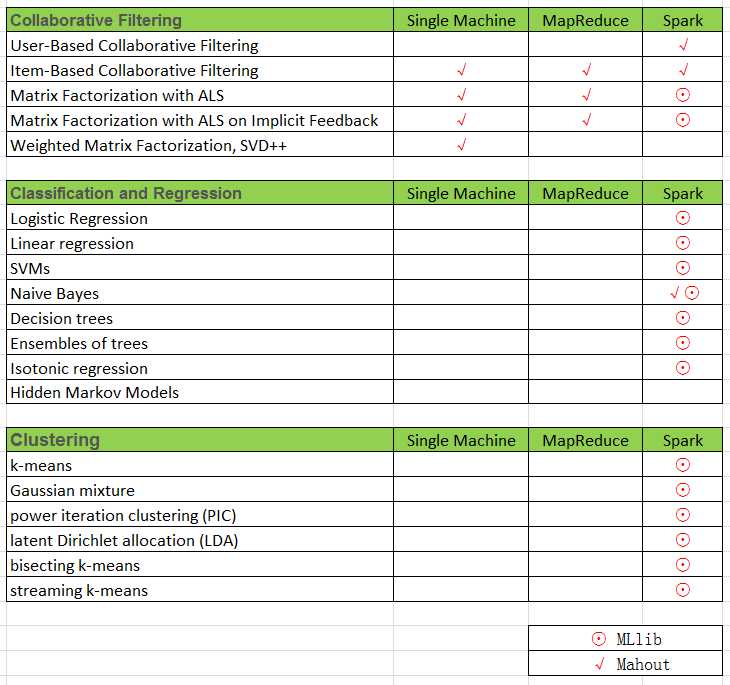
主要针对MLlib进行总结
分类和回归是监督式学习;
监督式学习是指使用有标签的数据(LabeledPoint)进行训练,得到模型后,使用测试数据预测结果。其中标签数据是指已知结果的特征数据。
分类和回归的区别:预测结果的变量类型
分类预测出来的变量是离散的(比如对邮件的分类,垃圾邮件和非垃圾邮件),对于二元分类的标签是0和1,对于多元分类标签范围是0~C-1,C表示类别数目;
回归预测出来的变量是连续的(比如根据年龄和体重预测身高)
线性回归
线性回归是回归中最常用的方法之一,是指用特征的线性组合来预测输出值。
线性回归算法可以使用的类有:
LinearRegressionWithSGD
RidgeRegressionWithSGD
LassoWithSGD
参数:
stepSize:梯度下降的步数
numIterations:迭代次数
设置intercept:是否给数据加上一个干扰特征或者偏差特征,一个始终值为1的特征,默认不增加false
{stepSize: 1.0, numIterations: 100, miniBatchFraction: 1.0}
模型的使用:
1、对数据进行预测,使用model.predict()
2、获取数据特征的权重model.weights()
模型的评估:
均方误差
例子:
import org.apache.spark.{SparkContext, SparkConf} import org.apache.spark.mllib.regression.LabeledPoint import org.apache.spark.mllib.regression.LinearRegressionModel import org.apache.spark.mllib.regression.LinearRegressionWithSGD import org.apache.spark.mllib.linalg.Vectors /** * Created by Edward on 2016/9/21. */ object LinearRegression { def main(args: Array[String]) { val conf: SparkConf = new SparkConf().setAppName("LinearRegression").setMaster("local") val sc = new SparkContext(conf) // Load and parse the data val data = sc.textFile("data/mllib/ridge-data/lpsa.data") val parsedData = data.map { line => val parts = line.split(‘,‘) LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(‘ ‘).map(_.toDouble))) }.cache() // Building the model val numIterations = 100 val model = LinearRegressionWithSGD.train(parsedData, numIterations) // var lr = new LinearRegressionWithSGD().setIntercept(true) // val model = lr.run(parsedData) //获取特征权重,及干扰特征 println("weights:%s, intercept:%s".format(model.weights,model.intercept)) // Evaluate model on training examples and compute training error val valuesAndPreds = parsedData.map { point => val prediction = model.predict(point.features) (point.label, prediction) } //计算 均方误差 val MSE = valuesAndPreds.map{case(v, p) => math.pow((v - p), 2)}.mean() println("training Mean Squared Error = " + MSE) // Save and load model model.save(sc, "myModelPath") val sameModel = LinearRegressionModel.load(sc, "myModelPath") } }
数据:
-0.4307829,-1.63735562648104 -2.00621178480549 -1.86242597251066 -1.02470580167082 -0.522940888712441 -0.863171185425945 -1.04215728919298 -0.864466507337306 -0.1625189,-1.98898046126935 -0.722008756122123 -0.787896192088153 -1.02470580167082 -0.522940888712441 -0.863171185425945 -1.04215728919298 -0.864466507337306 -0.1625189,-1.57881887548545 -2.1887840293994 1.36116336875686 -1.02470580167082 -0.522940888712441 -0.863171185425945 0.342627053981254 -0.155348103855541 -0.1625189,-2.16691708463163 -0.807993896938655 -0.787896192088153 -1.02470580167082 -0.522940888712441 -0.863171185425945 -1.04215728919298 -0.864466507337306 0.3715636,-0.507874475300631 -0.458834049396776 -0.250631301876899 -1.02470580167082 -0.522940888712441 -0.863171185425945 -1.04215728919298 -0.864466507337306 0.7654678,-2.03612849966376 -0.933954647105133 -1.86242597251066 -1.02470580167082 -0.522940888712441 -0.863171185425945 -1.04215728919298 -0.864466507337306
...
数据第一列表示标签数据,也就是结果数据,其他列表示特征数据;
预测就是再给一组特征数据,预测结果;
结果:
weights:[0.5808575763272221,0.18930001482946976,0.2803086929991066,0.1110834181777876,0.4010473965597895,-0.5603061626684255,-0.5804740464000981,0.8742741176970946], intercept:0.0
training Mean Squared Error = 6.207597210613579
持续更新中...
标签:
原文地址:http://www.cnblogs.com/one--way/p/5902242.html