标签:
我这次用构造单词树的形式进行词频统计,此次的任务是对已有的程序进行单元测试。选用的工具是JUnit。它是基于测试驱动开发(TDD)原理的。
此次词频统计的主体思想是,每次读入文章中的128(自己设定)个字符(目的是防止溢出),将这些字符存储到一颗树中,树中的节点有一个存储词频的变量和一个指向子节点的数组(类似于c语言中的指针)。最后遍历整棵树,按照词频进行排序。
下面是我的片段代码
下面这段代码是定义的节点的结构
class CharTreeNode{ int count=0; CharTreeNode children[]=new CharTreeNode[26]; }
下面这段代码是全局变量的声明,因为涉及到建树时都是从根节点开始生成,所以根节点定义为全局变量
//设置为全局变量,每读入一行,在原来生成的树的基础上继续生成子节点 public static CharTreeNode root=new CharTreeNode(); public static CharTreeNode p=root; private static FileReader reader=null; private static BufferedReader buffer=null; private Scanner scan;
下面这段代码实现的是对每个输入的字符串进行树的构造,最后返回的是树的根。
/* * 生成单词树 * */ public static CharTreeNode generateCharTree(String text) { char c = ‘ ‘; for (int i = 0; i < text.length(); i++) { c = text.charAt(i); if (c > ‘A‘ && c < ‘Z‘) { c = (char) (c + ‘a‘ - ‘A‘); // 变大写字母为小写字母 } if (c >= ‘a‘ && c <= ‘z‘) { if (p.children[c - ‘a‘] == null) { p.children[c - ‘a‘] = new CharTreeNode(); } p = p.children[c - ‘a‘]; } else { p.count++; p = root; } } if (c >= ‘a‘ && c <= ‘z‘) p.count++; return root; }
下面这段代码用方法重载的形式遍历整棵树,然后将遍历到的单词存储在List
/* * 遍历整棵树,将遍历得到的每个单词存到list中 * */ public static void searchTree(List<Word> list, CharTreeNode node, char buffer[], int len) { for (int i = 0; i < 26; i++) { if (node.children[i] != null) { buffer[len] = (char) (i + ‘a‘); if (node.children[i].count > 0) { // 遍历到了单词的最后一个字母 Word word = new Word(); word.setNum(node.children[i].count); word.setWord(String.valueOf(buffer, 0, len + 1)); list.add(word); } searchTree(list, node.children[i], buffer, len + 1); // 递归调用,每次以上一个叶节点作为下次递归的头结点 } } } /* * searchTree()为重载的方法 * */ public static void searchTree(List<Word> list, CharTreeNode node) { searchTree(list, node, new char[100], 0); }
下面这段代码是对不同路径构造的树数进行单词的排序和输出
/* * 对文章用generateCharTree()函数生成单词树,在对生成的单词树进行排序并且输出 */ public static void sortAndOutput(String filePath) throws IOException { reader = new FileReader(filePath); buffer = new BufferedReader(reader); char c[] = new char[128]; // 防止读入一行太长而出现溢出的情况 int len; String temp = ""; // 存储buffer读出的字符 String lastWord = ""; // 若读出的最后一个字符是字母,lastWord存储那个字符所在的单词,lastWord就被加到下一轮的temp中 while ((len = buffer.read(c)) > 0) { temp = ""; // 清空上一轮temp的内容 temp += lastWord; for (int i = 0; i < len; i++) { temp += c[i]; } lastWord = ""; // 清空上一轮lastword的内容 if (Character.isLetter(c[len - 1])) { // 当128个字符的最后一个字符为字母时,就得分情况讨论 int j, t; for (j = len - 1, t = 0; Character.isLetter(c[j]); j--, t++) ; // t代表最后一个字符(c[len-1])为字符时,前面有几个连续的字符 temp = temp.substring(0, temp.length() - t); // 当检测到最后一个字符为字母时,直接将最后一个字符所在的单词剔除本轮的temp,而转接到下一轮的temp中 for (int k = j + 1; k < len; k++) { lastWord += c[k]; } } root = generateCharTree(temp); } List<Word> list = new ArrayList<Word>(); searchTree(list, root); // 对生成的单词树按照单词的次数逆向排序排序 Collections.sort(list, new Comparator<Object>() { @Override public int compare(Object o1, Object o2) { Word word1 = (Word) o1; Word word2 = (Word) o2; return word2.getNum() - word1.getNum(); } }); buffer.close(); reader.close(); root=new CharTreeNode(); //但对于输入的是目录时,对每篇文章建立的树统计完后,应当初始化这棵树,便于下篇文章建树 System.out.println("单词\t数量"); for (int i = 0; i < 5; i++) { System.out.println(((Word) list.get(i)).getWord() + "\t" + ((Word) list.get(i)).getNum()); } }
下面进入此次的重头戏:单元测试。引入Junit后在每个测试的方法前加上@Test,选中方法名即可测试
下面这段代码是对输入目标的文件的路径进行该文件的词频统计
@Test public void testInputFilePath() throws IOException { scan = new Scanner(System.in); String filePath = scan.next(); while (filePath != null) { sortAndOutput(filePath); filePath = scan.next(); } }
结果截图如下

下图当输入的文件名找不到时

下面这段代码是对输入目标文件的文件名进行该文件的词频统计
@Test public void testInputFileName() throws IOException { scan = new Scanner(System.in); String filePath = scan.next(); sortAndOutput("F:\\document\\" + filePath); }
结果截图如下
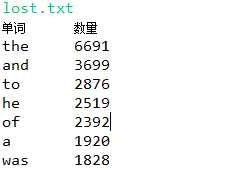
下面这段代码是对输入目标文件所在的目录名,进行该文件的词频统计
@Test public void testInputDirectoryPath() throws IOException { scan = new Scanner(System.in); String DirectoryPath = scan.next(); File f = new File(DirectoryPath); File s[] = f.listFiles(); for (int i = 0; i < s.length; i++) { String fileName = s[i].getName(); if (fileName.endsWith(".txt")) { sortAndOutput(DirectoryPath + "\\" + fileName); } } }
结果截图如下

下面这段代码测试重定向输入
@Test public void reDirectInputByConsole() throws IOException { Scanner scan = new Scanner(System.in); String command = scan.nextLine(); String filePath = command.substring(command.indexOf("<") + 1); reader = new FileReader(filePath.trim()); buffer = new BufferedReader(reader); String line = null; line = buffer.readLine(); String targetFile = "F:\\document\\new.txt"; FileWriter out = new FileWriter(targetFile); while (line != null) { out.write(line + "\r\n"); line = buffer.readLine(); } out.close(); buffer.close(); reader.close(); sortAndOutput(targetFile); } }
结果如下

测试后的感受:
测试过程中发现了程序的bug,比如在测试输入目录时,因为没将数进行清空,下一篇文章的单词会追加到以前的树上,通过单元测试解决了这个问题。
标签:
原文地址:http://www.cnblogs.com/liquan/p/5904068.html