标签:
1、DashBoard:
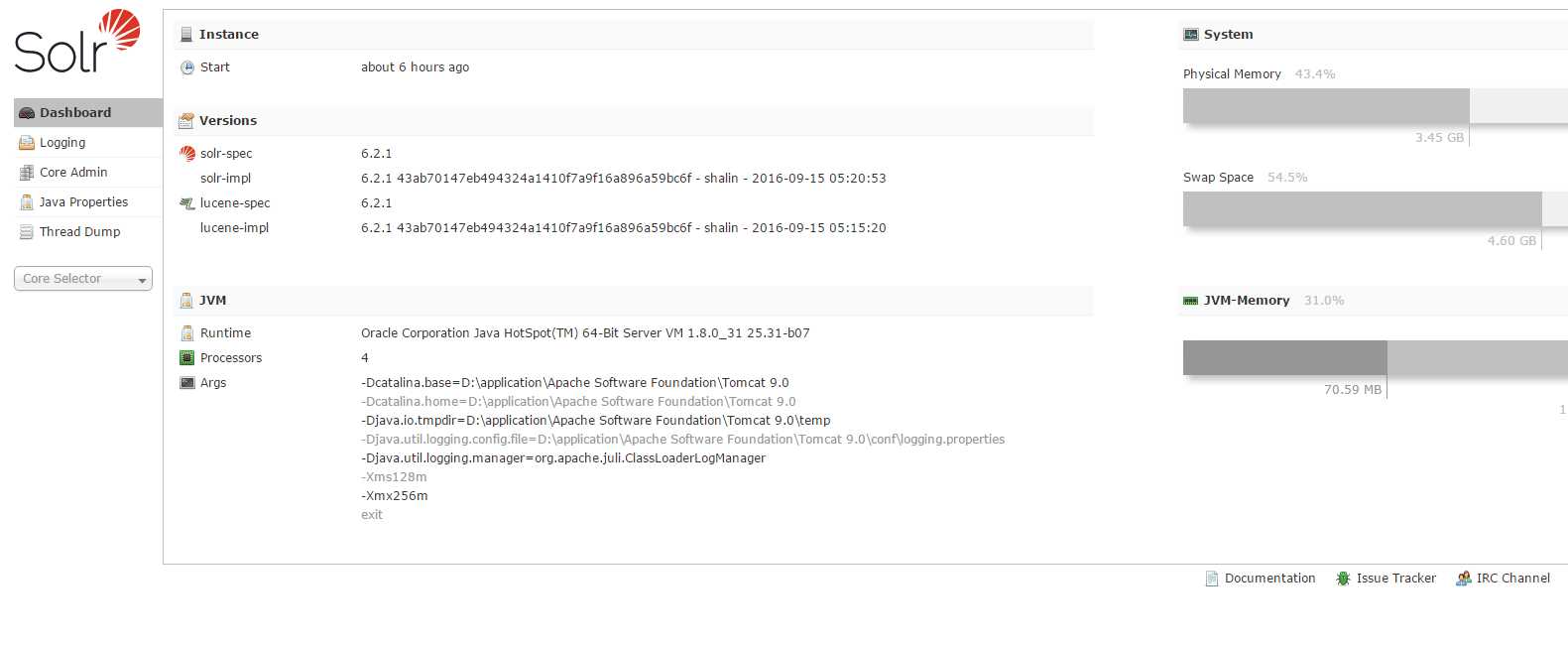
介绍了当前solr的相关信息,运行时间,版本信息,java虚拟机的配置信息。
注意我们的solr与lucence的版本号是保持一致的,而不同的lucence版本也需要对应的java版本。
2、core admin
独立的索引库
介绍我们当前索引库的安装位置与索引数据的位置,已经当前索引文档的大小等相关信息。
3、selected core
1)Analyzer 可以查看当前索引库中的字段(域)列表,以及分词效果。
字段(域)列表:所有的字段都是定义在schema.xml文件中,字段都是先定义引用。想修改的话都需要修改该文件。
查看字段的分析效果,每个字段都定义了不同分词效果,对于中文来说,分词效果比较差,需要相关分词器的支持。
2)DataImport 直接配置连接数据库的数据域导入
3)Document:进行文档的增删改操作。
添加文档:
文档支持多种数据类型,最常见的json格式,json格式的key就应该要对应schema.xml文件中的字段,
在solr文档中必须要有一个id字段并且不能重复,当id重复时,相关的文档插入将会变成更新操作。
更新文档:
当更新文档时将先删除不会当前文档id的数据,然后在添加该文档。
删除文档:
<delete>
<id>1280</id>
</delete>
<commit>(该方式为在后台中使用xml格式删除)
4)Query查询:
q:查询条件,*:*为匹配所有,“name:ygl”精确匹配name为ygl的数据。
fq:过滤条件,基于q查询条件上在添加条件进行过滤,类似于mongo的管道,社会多个
sort:排序
start,rows:分页,起始记录数与每页大小
fl:指定返回的字段。
df:默认搜索字段,指定name,则只回去匹配name字段
hl:高亮
标签:
原文地址:http://www.cnblogs.com/DASOU/p/5904553.html