标签:
前言:在寻错及修改两天之后,发现之前的程序不能处理大文件的原因在于所写的排序部分,于是做了两件事:
第一是修改了所写的quick排序部分,现在可以处理大文件了;
第二是学习了http://www.blogjava.net/killme2008/archive/2010/09/08/quicksort_optimized.html 中写的关于快速排序算法的优化改进,也移植到了我的程序里试了试。
分别使用两种方法处理同一份文件,大小是1M,不同的词有17000,这个大小的文件之前是一处理就崩溃的,算是有所进步了。
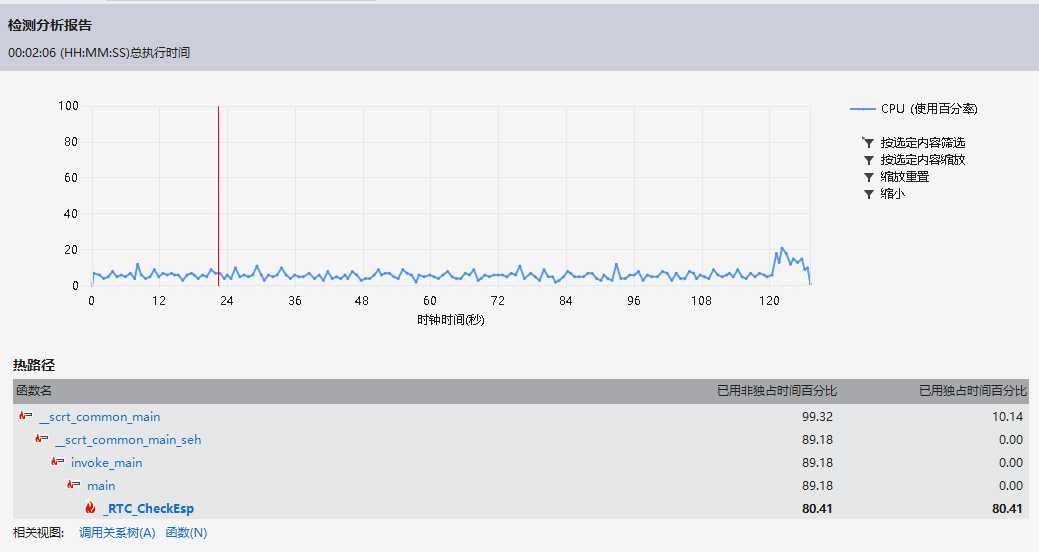
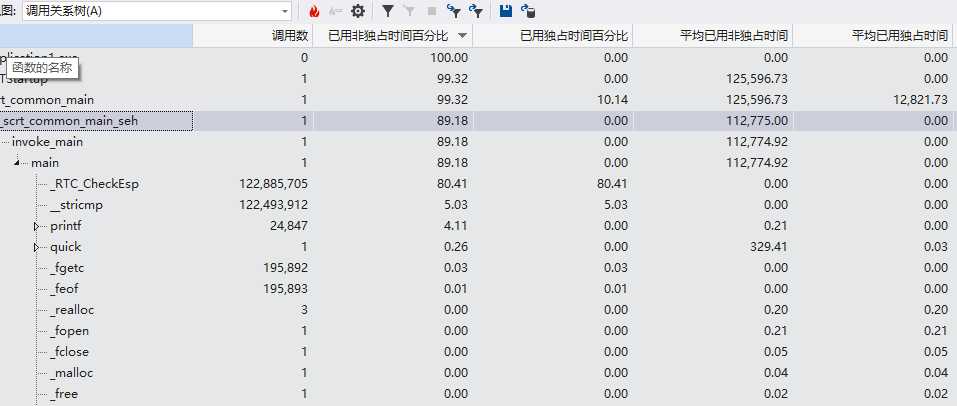
方法一:
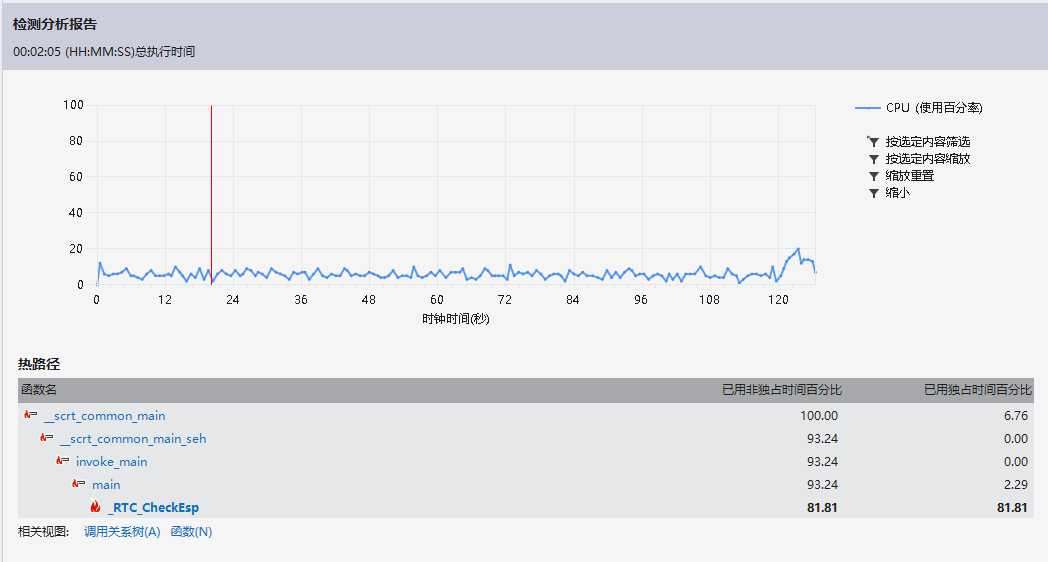
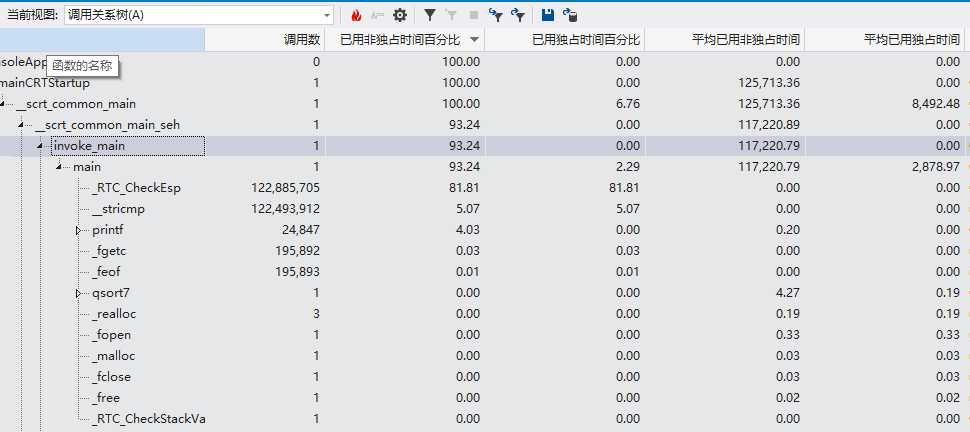
方法二:
方法二的代码:
void qsort7(struct fre_word *f, int p, int r)
{
char x[word_size];
int len = r - p + 1;
if (p >= r)
return;
// 在数组大小小于7的情况下使用直接插入排序
if (len< 7)
{
for (int i = p; i <= r; i++)
{
for (int j = i; j > p && f[j - 1].num > f[j].num; j--)
{
swapf(f, j, j - 1);
}
}
return;
}
// 选择中数,与qsort6相同。
int m = p + (len >> 1);
if (len > 7)
{
int l = p;
int n = r;
if (len > 40)
{
int s = len / 8;
int s2 = 2 * s;
l = med3(f, l, l + s, l + s2);
m = med3(f, m - s, m, m + s);
n = med3(f, n - s2, n - s, n);
}
m = med3(f, l, m, n);
}
int v = f[m].num;
strcpy(x, f[m].wd);
// a,b进行左端扫描,c,d进行右端扫描
int a = p, b = a, c = p + len - 1, d = c;
while (true)
{
// 尝试找到大于pivot的元素
while (b <= c && f[b].num <= v)
{
// 与pivot相同的交换到左端
if (f[b].num == v)
swapf(f, a++, b);
b++;
}
// 尝试找到小于pivot的元素
while (c >= b && f[c].num >= v)
{
// 与pivot相同的交换到右端
if (f[c].num == v)
swapf(f, c, d--);
c--;
}
if (b > c)
break;
// 交换找到的元素
swapf(f, b++, c--);
}
// 将相同的元素交换到中间
int s, n = p + len;
s = (a - p)>(b - a) ? (b - a) : (a - p);
vecswap(f, p, b - s, s);
s = (d - c)>(n - d - 1) ? (n - d - 1) : (d - c);
vecswap(f, b, n - s, s);
// 递归调用子序列
if ((s = b - a) > 1)
qsort7(f, p, s + p - 1);
if ((s = d - c) > 1)
qsort7(f, n - s, n - 1);
}
方法二特点是分情况进行排序,在需要排序的数组数量小于一个值的时候使用直接插入排序,大于的时候使用快速排序,在选取枢轴的时候也是用的是三数取中,可以避免快速排序的在选枢轴的弊端。
其中涉及到三个调用的函数:
swapf目的是交换两个结构体的数据。
void swapf(struct fre_word *f, int a, int b)//交换两个结构体内的数据
{
int temp;
char x[word_size];
temp = f[b].num;
strcpy(x, f[b].wd);
f[b].num = f[a].num;
strcpy(f[b].wd, f[a].wd);
f[a].num = temp;
strcpy(f[a].wd, x);
}
vecswap目的是批量交换连续的结构体。
void vecswap(fre_word *f, int a, int b, int n)
{
for (int i = 0; i < n; i++, a++, b++)
swapf(f, a, b);
}
med3目的是三数取中。
int med3(struct fre_word *f, int a, int b, int c)
{
return f[a].num< f[b].num ? (f[b].num < f[c].num ? b : f[a].num < f[c].num ? c : a) : f[b].num > f[c].num ? b : f[a].num > f[c].num ? c : a;
}
结论:但是从测试结果来看,跟排序算法关系并不大,所耗时间几乎是没改变的,也就是说那么多高端的方法并没有什么实质性的提升,真正影响性能的还是在程序主体。但是在这次改进排序的过程中,改正了之前程序里的一些边界情况,也使得程序可以处理稍大些的文件了,收获还是挺大的。
https:https://git.coding.net/gongcr/word-frequency.git
ssh:git@git.coding.net:gongcr/word-frequency.git
git:git://git.coding.net/gongcr/word-frequency.git
标签:
原文地址:http://www.cnblogs.com/gongcr/p/5894051.html