标签:
MapReduce概述
MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
MapReduce合并了两种经典函数:
映射(Mapping)对集合里的每个目标应用同一个操作。即,如果你想把表单里每个单元格乘以二,那么把这个函数单独地应用在每个单元格上的操作就属于mapping。
如:[1,2] ==> [1X2,2X2] ==> [2,4]
化简(Reducing )遍历集合中的元素来返回一个综合的结果。即,输出表单里一列数字的和这个任务属于reducing。
Mapreduce原理图:
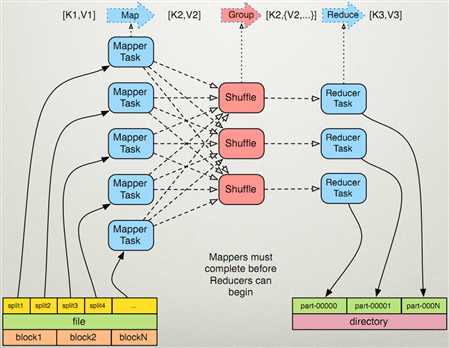
数据源为:k1,v1
客户的需求为k2,v2
一个block块对应多个split,一个split对应一个map任务,一个reduce任务会生成一个part-00000文件则一个reduce输出一个文件
执行的过程:
map任务的阶段:
1.1:读取文件,解释成为key,value键值对,每一行的字节偏移量会作为key, 每一行的文本内容会作为value.每一键值对调用都会执行一次(hadoop系统)
1.2:自定义的Mapper函数,k1,v1为输入值,进行编写自己的逻辑,完成后输出k2,v2(自己手写)
public static class WorldCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> { public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] worlds = value.toString().split(","); for(String world :worlds){ context.write(new Text(world), new LongWritable(1)); } } }
1.3:对输出的key、value进行分区。(hadoop系统)
1.4对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。(hadoop系统)
1.5分组后的数据进行归约
reduce任务阶段:
2.1对多个map函数的输出,按照不同的分区,通过网络把数据copy到同一个reduce节点上(hadoop系统)
2.2自定义的reduce函数,k2,v2为输入值,进行编写自己的逻辑,完成后输出k3,v3(自己手写)
public static class WorldCountReduce extends Reducer<Text, LongWritable, Text, LongWritable>{ protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub long sum =0 ; for(LongWritable v2:v2s){ sum += v2.get(); } context.write(k2, new LongWritable(sum)); } }
2.3 把reduce的输出保存到文件中。
驱动代码:
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); //加载配置文件 Job job = new Job(conf); //创建一个job,供JobTracker使用 job.setJarByClass(WordCountApp.class); job.setMapperClass(WorldCountMapper.class); job.setReducerClass(WorldCountReduce.class); FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.1.10:9000/input"));//hadoop2.x能够读取文件夹与文件 //如果想读取子文件夹则需要设置属性 FileInputFormat.setInputDirRecursive(job, true); FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.1.10:9000/output")); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); job.waitForCompletion(true); }
标签:
原文地址:http://www.cnblogs.com/feihaoItboy/p/5906691.html