标签:
Hadoop 2.0 产生背景

客户端发送读写请求先要经过NameNode,NameNode的元数据会不断增大,需要将元数据分开存放(内存)
MapReduce为离线计算框架,Storm为流式计算框架,Spark为内存计算框架
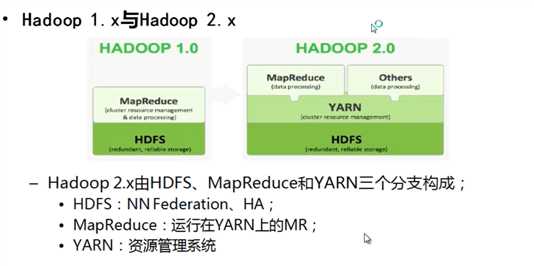
NNFederation : 将元数据分为两个独立的进行运行,两个互不影响
YARN:资源管理系统(内存,cpu...)

HDFS 2.x
解决HDFS 1.0 中单点故障和内存受限问题
解决单点故障
HDFS HA : 通过主备NameNode解决(一个为主,其他为备,只有一个工作)
如果主NameNode发生故障,则切换到备NameNode上
解决内存受限问题
HDFS Federation(联邦);
水平扩展,支持多个NameNode;
每个NameNode分管一部分目录;
所有NameNode共享所有DataNode存储资源
2.x仅是架构上发生变化,使用方式不变
对HDFS 使用者透明
HDFS1.x中的命令和API扔可以使用
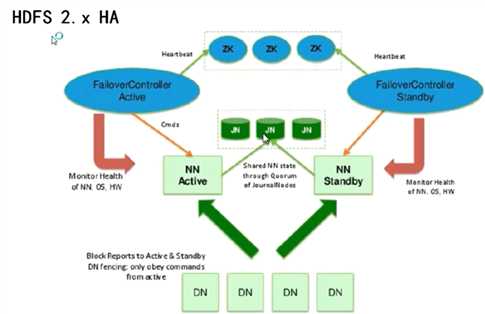
HA: 解决单点故障问题
Hadoop是集群方式运行,集群方式最重要的问题是 解决单点故障问题
DN: DataNode ,数据内容(block),启动后会把位置信息上报给所有的NameNode(NN)
NN: NameNode,分为主备,Active为主,Standby为备,有一个主多个备,所有NameNode都会收到DN的汇报数据,NameNode会把元数据信息放到磁盘上(edits,fsimage),NameNode(主)挂掉后内存中的metaData会丢失,Standby会加载Active共享的edits和fsimage数据
JN:NameNode(Active)把edits和fsimage数据不再备份到本地磁盘,而是共享到JN(JournalNode)中,所有的NameNode不管是主还是备,如果要读或写元数据都会在JN进行读写元数据,JN有多个。
JN是一种方式,还有一种方式是NFS(Network File System)网络文件系统,也就是共享文件夹,所有读写到一台共享机器上,本地会有一个文件映射系统,类似于进行本地读写一样,如果这台共享机器挂掉,但这种方式也存在单点故障问题,不推荐。
FailoverController:控制NameNode切换的一个任务(服务),且可以对NameNode进行心跳检查,并向zk反馈本身心跳
ZK:在Hadoop的高可用性中不是使用 Keepalived 而是使用ZooKeeper,主要作用是高可用,zk为用户提供了二次开发接口,可以为任何服务提供高可用
在2.x的 HA中 客户端不去指定访问那个NameNode,而是访问ZK,zk知道访问哪个NameNode,即哪一个NameNode(Action)工作的机器

客户端访问zk,zk知道哪一个NameNode是属于Active的
每一个NameNode都对应一个ZKFC(ZooKeeper FailoverController )
架构中zk必须为大于1的奇数个,因为zk的内部算法为投票机制,如果为偶数有可能无法选出一个ZKFC

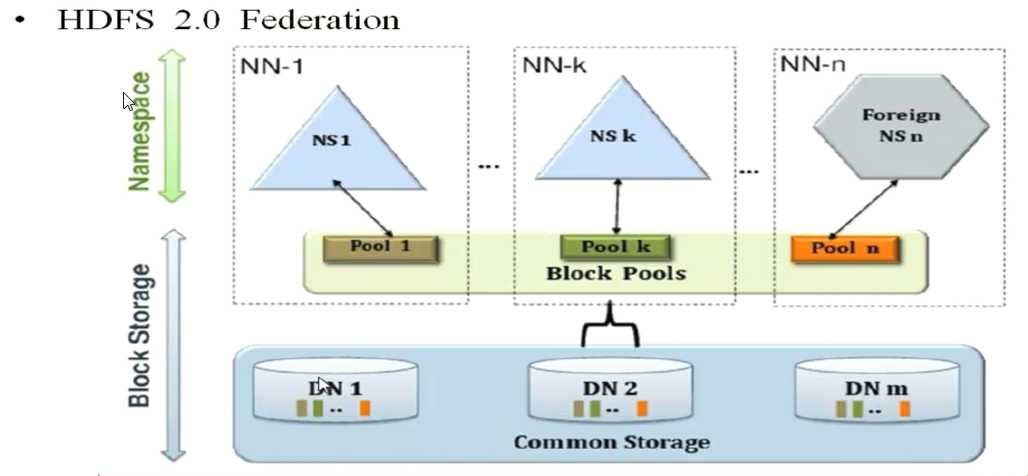
所有的DN(DataNode)为所有的NameNode服务,NameNode之间的工作是相互独立的
Federation 应用在数据超大的场景中,比如电信的数据,从业务场景从业务角度分类多个NN
如果在Federation上加 HA ,需要在每个NameNode上分别做 HA,即独立的集群,但DataNode是共享的

YARN(Yet Another Resource Negotiator),两个最大特性
1.实现了接口化,实现计算框架接口化,可以兼容第三方计算框架,例如Spark,Storm等。
2.引入资源管理系统,而且是分布式资源管理系统,两种节点 ResourceManager,ApplicationMaster,ApplicationMaster是运行在某一个真正的节点上,ApplicationMaster可能会有多个,ResourceManager只有一个

HDFS HA 集群搭建:
DN(DataNode):3个;NN(NameNode):2;ZK(ZooKeeper):3(大于1的奇数个);ZKFC:和NN在同一台机器;JN:3;RM(ResourceManager):1;DM(DataManager):3个;与DN在同一台,就近原则
√表示在该机器上有该进程。
| NN | DN | ZK | ZKFC | JN | RM | DM | |
| Node1 | √ | √ | √ | √ | |||
| Node2 | √ | √ | √ | √ | √ | √ | |
| Node3 | √ | √ | √ | √ | |||
| Node4 | √ | √ | √ |
标签:
原文地址:http://www.cnblogs.com/wq3435/p/5860891.html