标签:
Hive数据操作
hive没有行级别数据插入、数据更新和删除操作。
采用“大量”的数据装载操作,或者通过其它方式仅仅将文件写入到正确目录下。
LOAD DATA LOCAL INPATH ‘${env:HOME}/california-employees‘
OVERWRITE INTO TABLE employees
PARTITION (country=‘US‘, state=‘CA‘);
关于PARTITION:
- 如果分区目录不存在,该命令会先创建分区,然后将数据拷贝到该分区目录。
- 如果目标表为非分区表,需要省略PARTITION子句。
关于LOCAL:
- LOAD DATA LOCAL......拷贝本地数据到位于分布式文件系统上的目标位置。
- LOAD DATA......转移数据到目标位置。
关于OVERWRITE:
- 若有该关键字,目标文件夹中之前存在的数据会先被删除。
- 若没有该关键字,会把新增的文件增加到目标文件夹中而不会删除之前的。
- 若目标文件夹中存在和装载的文件同名文件,旧的文件将会被覆盖重写。
2.通过查询语句向表中插入数据
一次创建一个分区语法:
INSERT OVERWRITE TABLE employees
PARTITION (country=‘US‘,state=‘OR‘)
SELECT * FROM staged_employees se
WHERE se.cnty=‘US‘ AND se.st=‘OR‘;
关于OVERWRITE:
- 若使用了该关键字,之前 分区中内内容(或无分区表中内容)将会被覆盖掉。
- 若未使用该关键字或者使用了INTO关键字,hive将会以追加的方式写入数据。
一次创建多个分区语法:
如果表staged_emplyees非常大,用户需要对65个州都执行这些语句,那就意味着要扫描staged_employees 65次,所以可以采用另一各INSERT语法,例子中显示了如何为3个州创建表employees分区:
FROM stage_employees se
INSERT OVERWRITE TABLE employees
PARTITION (country=‘US‘,state=‘OR‘)
SELECT * WHERE se.cnty=‘US‘ AND se.st= ‘OR‘
INSERT OVERWRITE TABLE employees
PARTITION (country=‘US‘,state=‘CA‘)
SELECT * WHERE se.cnty=‘US‘ AND se.st= ‘CA‘
INSERT OVERWRITE TABLE employees
PARTITION (country=‘US‘,state=‘IL‘)
SELECT * WHERE se.cnty=‘US‘ AND se.st= ‘IL‘;
当然这里可以混合使用INSERT OVERWRITE 或INSERT INTO句式。
动态分区插入语法:
根据前边语法,当创建非常多的分区时,就需要写非常多的SQL,所以hive提供了动态分区功能,前边用到的属于静态分区。
动态分区语法如下:
INSERT OVERWRITE TABLE employees
PARTITION (country,state)
SELECT ..., se.cnty,se.st
FROM staged_employees se;
- HIVE根据SELECT语句中最后2列确定分区字段country和state的值。这就是为什么在表staged_employees中我们使用了不同的命名,是为了强调源表字段值和输出分区值之间的关系是根据位置而不是根据命名来匹配的。
- 假设表staged_employees中有100个国家和州的话,执行完上述语句后,表employees就会有100个分区。
动态分区和静态分区混合使用语法:
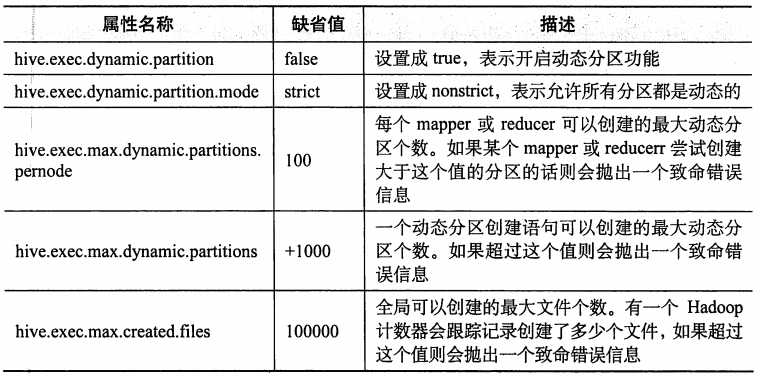
动态分区功能默认情况下未开户,开启后默认是“严格”模式执行,该模式下要求至少有一列分区字段是静态的。这样设计有助于防止因设计错误导致查询产生大量的分区。
动态分区属性:
属性设置:
属性查看:
混合使用语法:
INSERT OVERWRITE TABLE employees
PARTITION (country=‘US‘,state)
SELECT ..., se.cnty,se.st
FROM staged_employees se;
WHERE se.cnty=‘US‘;
3.单个查询语句创建并加载数据
CREATE TABLE ca_employees
AS SELECT name,salary,address
FROM employees
WHERE se.state =‘CA‘;
- 该功能常用于从一个大的宽表中选取部分需要的数据集。
- 该功能不能用于外部表。
4.导出数据
数据文件恰好与用户需要格式一致时,直接拷贝:
hadoop fs -cp source_path target_path
否则,可使用INSERT...DIRECTORY...:
INSERT OVERWRITE LOCAL DIRECTORY ‘/tmp/ca_employees‘
SELECT name,salary,address
FROM employees
WHERE se.state=‘CA‘;
同向表中插入数据,也可导出文件到多个文件夹目录:
FROM staged_employees se
INSERT OVERWRITE DIRECTORY ‘/tmp/or_employees‘
SELECT * WHERE se.cty=‘US‘ and se.st=‘OR‘
INSERT OVERWRITE DIRECTORY ‘/tmp/or_employees‘
SELECT * WHERE se.cty=‘US‘ and se.st=‘CA‘
INSERT OVERWRITE DIRECTORY ‘/tmp/or_employees‘
SELECT * WHERE se.cty=‘US‘ and se.st=‘IL‘
HIVE数据操作
标签:
原文地址:http://www.cnblogs.com/dreamfly2016/p/5912495.html