标签:
线性回归。
从本节课开始,我会适当的结合一些《机器学习实战》中的相关知识点对各个模型做一个更加全面的归纳和总结。

继续试着用加权(打分)的方式对每一个输入x进行计算,得出的线性回归的模型为h(x)=WTX。衡量的目标是找一个向量W使得squared error最小。由于Ein≈Eout,所以我们还是只看Ein就好了。

那么怎么最小化Ein呢?以下是一些数学推导:
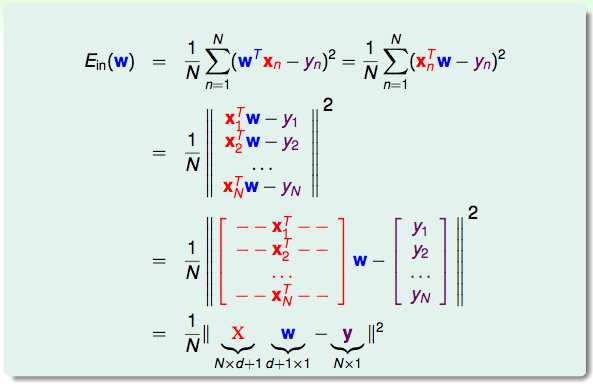
我们的目标变成了最小化Ein,也就是说要求下面式子的最小值。
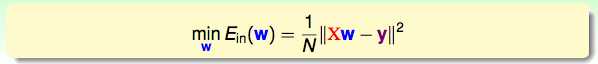
Ein的一些特点:连续,可微的凸函数,求最小的Ein就是求Ein函数上每一个点的梯度。
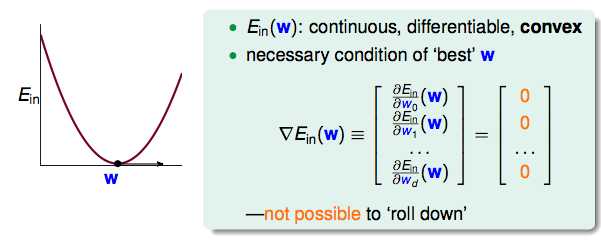
梯度是0的时候,函数在该点上,不管是朝哪一个方向,都不能往下滚了。也就是说在凸函数谷底的梯度(偏微分)一定要是0。我们的目标又变成了找到一个wlin,使得梯度Ein(wlin)=0
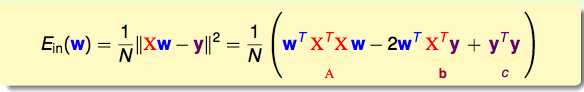
这是一个关于w的一元二次方程,求导之后得出:
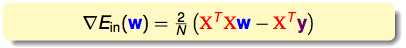
其中,X和y都是已知的,只有要求的w是未知的。
根据XTX的性质不同(是不是invertible),我们分两种情况进行求解:

线性回归基本步骤:
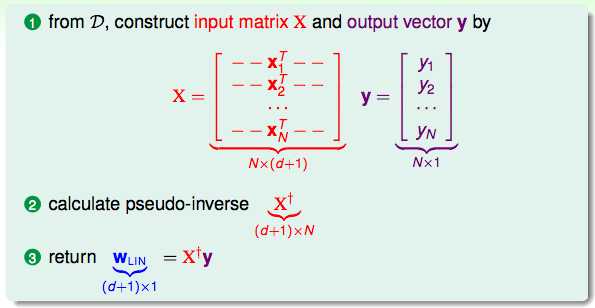
了解了线性回归的基本步骤,那么这个演算法真的是机器学习吗?

只要Eout的结果是好的,机器学习就在这个演算法里发生了。
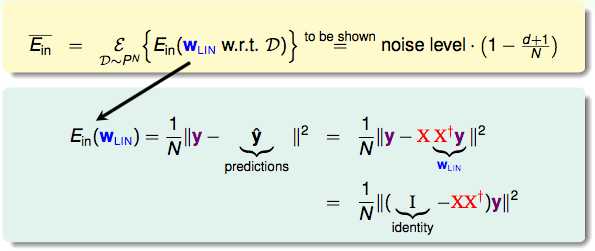
抛开单个的Ein,我们想看一下Ein的平均,通过证明得出Ein和噪声程度,自由度和样本数量有关。

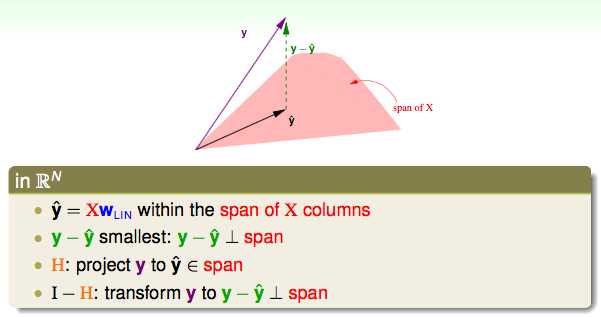
向量y表示所有的真实值,y hat表示所有的预测值。
y^=Xwlin是X的一个线性组合,而X中的每一个column对应一个向量,d+1个向量组合起来就是构成了一个平面span of X;
而我们的目标就是找到y和y hat最小的差值(距离最短),而这个最短的距离一定是垂直于平面span of X的;
H hat的意义就是做这个投影的动作;
I–H的意义就是得到与span垂直的那条向量。
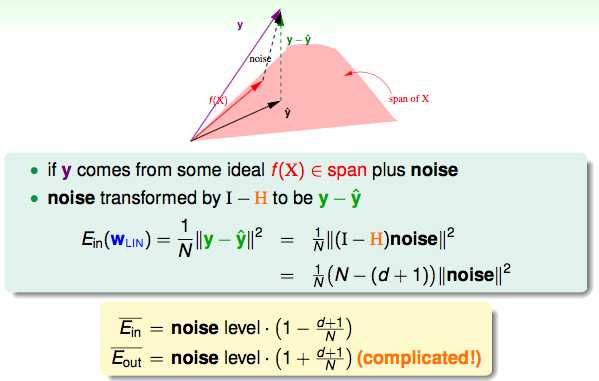
加上噪声之后做同样的转换,得出入下Ein和Eout的图形:
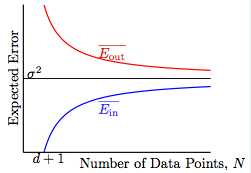
样本量越大的时候,Ein和Eout都会越趋近于噪声的等级;
给出了Ein和Eout的平均差别是2(d+1)/N。
总结:

线性回归的优缺点:
优点:结果易于理解,计算不复杂。
缺点:对非线性数据拟合不好。
适用:数值型和标称型数据。
1 from numpy import * 2 def LinearRegression(x,y): 3 #读入x,y并将它们保存在矩阵中 4 xMat = mat(x) 5 yMat = mat(y).T 6 #计算x的内积 7 xTx = xMat.T * xMat 8 #判断x的内积是否为零,也就是判断x是否可逆 9 if linalg.det(xTx) == 0: 10 print "This matrix is singular, cannot do inverse" 11 return 12 #求出w 13 w = linalg.solve(xTx, xMat.T*yMat) 14 return w
标签:
原文地址:http://www.cnblogs.com/cyoutetsu/p/5914001.html