dfs.datanode.max.locked.memory:
DataNode最大的缓存size,默认为4G。
io.compression.codecs文件压缩:
配置Hadoop集群文件压缩策略:DefaultCodec, GzipCodec, BZip2Codec, DeflateCodec, SnappyCodec,Lz4Codec
YARN/GateWay Tuning
mapreduce.job.reduce.slowstart.completedmaps:
Map tasks执行完成百分之多少,开始创建reducer执行的容器。
mapreduce.reduce.shuffle.parallelcopies reducer:
Reducer内部可开的线程数。CM默认为10。推荐值计算方式:ln(count(cluster nodes)*4)
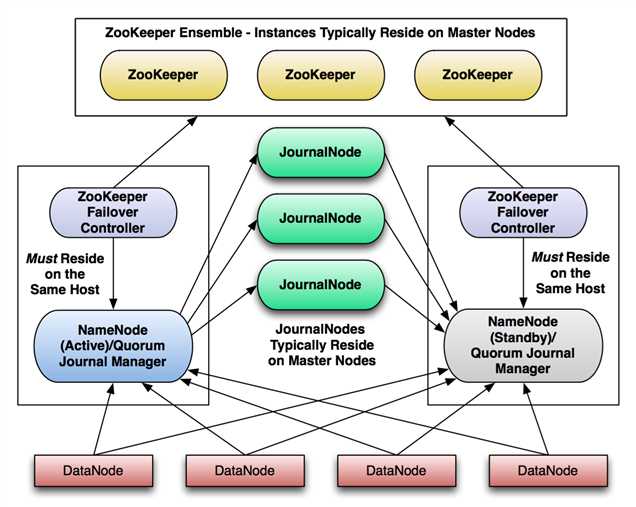
Hadoop cluster产线环境的HA配置:
HA主要是解决NameNode的单点故障,主要指NameNode crash, NameNode manitenance。
启用HA之后,会有两个NameNode(active,standby)和两个Failover Controllers以及若干个同步NameNode的Journal Nodes。不在需要SecondaryNameNode。
clients只连接actvie NameNode。
DataNodes的heartbeat会同时发给active和standby NameNode。
Active NameNode会把metadata写入指定数目(奇数个)的JournalNode。
Standby NameNode从JournalNodes读取metadata信息,完成与Active的sync。
ZooKeeper failover Controller 自动进行Failover。
没有failback,恢复的NameNode自动变为standby。
配置选项:dfs.ha.automatic-failover.enabled
配置HA之后,Hive,impala,Hue均要进行一定的update。