标签:style blog http 使用 os io strong 数据
决策树(decision tree)
决策树:是一种基本的分类和回归方法。它是基于实例特征对实例进行分类的过程,我们可以认为决策树就是很多if-then的规则集合。
优点:1)训练生成的模型可读性强,我们可以很直观的看出生成模型的构成已经工作方式,因为模型就是由数据属性和类别构成一棵树。
2)由于是一棵树,所以它的预测分类速度快,想想一棵树能有多大的深度。如果是一颗二叉树即使有N个数据,深度也只有logN。
原则:根据损失函数最小化的原则建立决策树模型(其实大部分模型都是这个原则)
步骤:1)特征选择(不同的算法,选择不一样,比如CART就是随机选择m个特征)
2)决策树的生成(就是通过数据的属性进行不断的分裂,直到叶子节点为止)
现在目前主要的决策树算法:ID3,C4.5,CART,RandomForest.....
信息熵:
(有关信息熵的介绍在吴军的著作《数学之美》有着非常好的介绍,强烈介绍)
说到决策树算法,这个是不得不提的。因为在构建决策树的时候,节点选择的属性是依据信息熵来确定的,就是根据信息熵来确定选择哪个属性用于当前数据集的分类。 ”信息熵“是香农提出来的。我们知道信息是有用的,但是如何来定量描述这个信息量的大小呢。而“信息熵”就是为了解决这个问题而提出来的,用来量化信息的作用。
一条信息的信息量是和它的不确定性有着直接关系的,当我们对于一件不确定的时候,就需要比较多的信息来搞懂这件事,相反,如果对于一件事情我们很确定,那么我们就需要比较少的信息就可以知道这件事。因此从这个角度看,我们就可以认为信息量的大小就是不确定的多少。但是如何来量化这个信息量呢(也就是不确定性)
香农给出了这个公式:H=-(P1logP1+P2logP2+....) (P(X)为出现的概率)
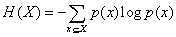
变量的不确定性越大,熵也就越大,把它弄清楚所需要的信息量也就越大。
(1)ID3算法:
核心:在决策树的各个节点上应用信息增益准则来选择特征属性(就是我们上面提到的信息熵)
步骤:
信息增益计算:g(D,A)=H(D)-H(D/A) (具体如何计算可以参考李航的统计学习这本书)
H(D):表示原来未使用属性的信息熵。H(D/A):表示使用属性值A为某个节点后的信息熵。 二者之差就是信息增益。
(2)C4.5算法
C4.5是ID3算法的改进版,ID3使用信息增益比,但是信息增益有个缺点就是会偏向选择取值较多的特征,这样会造成数据过拟合。所以C4.5通过改进ID3使用信息增益率为特征选择准则。就是信息增益g(D,A)与训练数据集D有关于特征A的值得熵之比。
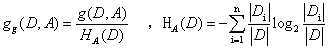
其他的步骤和ID3一样。
(3)CART算法
CART(classification and regression tree),分类与回归树。既可以用于分类也可以用于回归。
步骤:
对决策树(CART)的生成其实就是递归的构建二叉树的过程,对回归树用平方误差最小原则,对分类树采用基尼系数(Gini index)原则.
(1) 回归树
问题,如何对输入空间进行划分?
这里采用启发式的方法:选择第j个变量的x(j)和它的取值s作为切变量和切分点对数据进行划分,然后需找最优的s和j。具体求解:
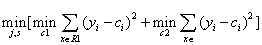
遍历所有输入变量,寻找最优切分遍历,依此将空间划分为两个空间。通常称为最小二乘回归树。
(2)分类树
利用基尼指数选择最优特征。基尼指数其实就代表了集合的不确定性,基尼指数越大,样本集合的不确定性也就越大,这一点与熵相似。基尼指数的曲线趋势和分类误差率差不多。
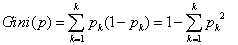 ,表示有K个类别,以及样本属于第K类的概率PK.
,表示有K个类别,以及样本属于第K类的概率PK.
选择基尼指数最小的特征及其对应的切分点作为最优特征和最优切分点。
(4)Random Forest算法
核心:其实就是集成学习的概念包括(bagging,boosting),通过集成投票的方式提高预测精度。
数据的选择:
(1)使用bootstrap重复有放回采样获取数据,这样可以避免数据的过拟合。这样就获取了很多训练数据集合,而且它们是相互独立,并且可以并行的。
(2)随机的抽取m个特征值与获取到的采样样本通过CART构建决策树。
(3)构建多棵决策树,用这些决策树进行投票预测
我们可以看出来,基分类器(即每一棵树)它们的训练数据不一样,它们的属性集合也不一样,这样就可以构建出许多有差异性的分类器出来,通过集成可以获取很好的预测精度。
就是一片树林里种植好多棵树,用这片森林来预测数据。
标签:style blog http 使用 os io strong 数据
原文地址:http://www.cnblogs.com/GuoJiaSheng/p/3907842.html