标签:
简单介绍一下外卖现在的情况:我们从2013年10月份做外卖的事情,是从餐饮外卖开始的。经过两年多的发展,我们不光可以提供餐饮外卖,也可以提供水果、鲜花、蛋糕、下午茶甚至是超市和便利店一些外送的服务。我们做外卖过程中,我们发现用户对外送的体验有两个关注点:
我们发现如果要把用户体验做到极致的话,做得足够好能保证用户得到足够好的体验,我们就要做专送的服务。所以我们正在做的是美团外卖的平台和我们自己的配送服务。
我们从2013年10月份确立做这个事情,到11月份正式上线,到14年底11月份时突破日订单一百万单,15年的5月份大概突破了每天两百万单,然后大概15年12月份做到每天三百万单,今年5月份的时候我们做到了四百万单每天。我们希望在响应国家大的号召下,我们做供给侧改革。我们希望给大家提供更多的、优质的、可选的外送服务,希望未来的某一天做到每天1000万单。
介绍一下我们的业务,也介绍一下在做这个业务过程中技术架构的演进的历程。我们在开始做外卖的时候发现,那时候都是通过电话来点外卖的,小餐馆的老板发传单,我们用传单上的电话给老板打电话下单。我们在思考我们是不是可以把电话点餐的事情变成网络点餐,让用户只需要在网络上点点点就行了,不用打电话。
于是我们在公司周围的商家摸索这个事情,我们早上下了地铁在地铁口发传单。我们怎么能够最快地去验证这个事情是否可行?我们提供了一个非常简单的Web版本和Android的App,对于商家那一边我们没有提供任何软件的服务,用户在我们平台里下单以后,我们再打电话给商家下单,有时候我们是发传单的,有时候我们是接线员,用户在我们平台上下单,我们再打电话给商家下单,然后再去写代码。那时候基本上没有太多架构考虑,就是怎么快怎么来,以最快的速度去把我们的功能给变上去。
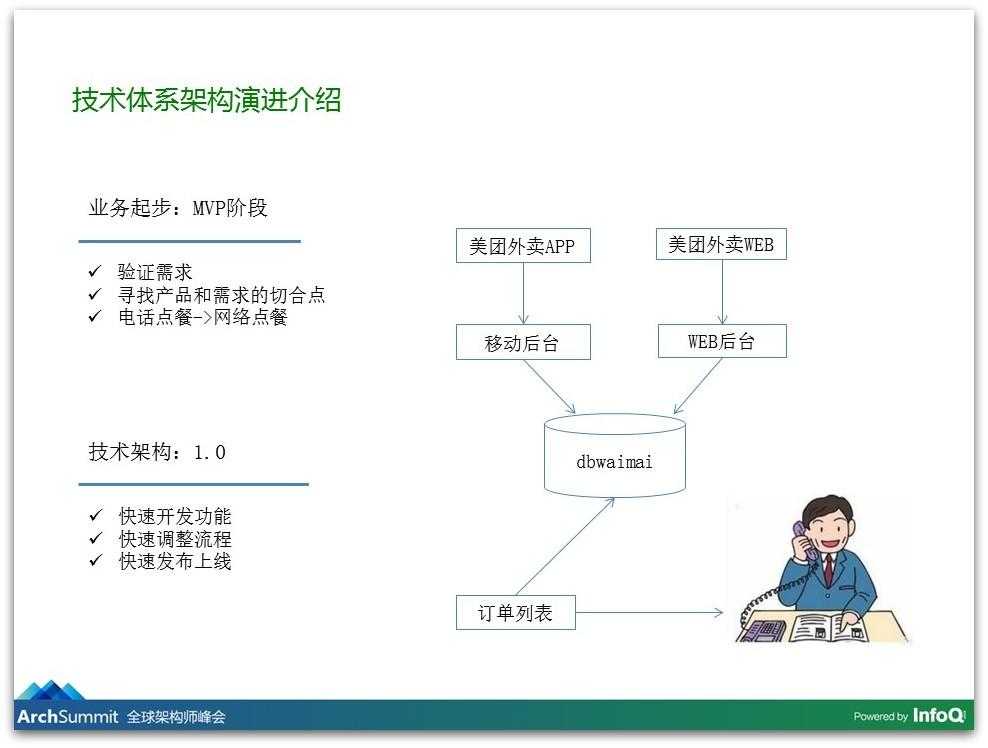
这个事情我们验证之后发现确实可行,我们发现“懒”是极大的需求。因为懒得去换台,所以发明了遥控器,懒得爬楼梯就发明了电梯,人都是很懒的,因为懒得打电话订餐,所以在网上点点点就好了。我们发现这是极强的需求,于是我们就考虑规模化,因为只有规模化之后边际的成本才可以变低,这套软件在一个区域可以用,在一个城市可以用、在全国也可以用,我们的开发成本就是这么多,所以我们在尝试在做规模化。
这个过程爆发性产生了非常多系统,我们在用户这边提供各种APP,商家这一边我们也开始提供服务。我们给商家提供PC的版本、App版本,还给商家提供打印机。打印机是跟我们后台是联网的,如果用户在我们平台上下单,我们会直接推送到这个打印机上,这个打印机可以直接打出单子,同时可以用林志玲或者郭德纲的声音告诉你:“你有美团外卖的订单请及时处理”,这是对商家非常好的效率提升;同时我们给自身运营的系统加了很多功能,我们有上单、审核等各种各样的系统等爆发性地产生了。
在这个阶段我们业务发展特别快导致我们堆了特别多的系统,这个时候也并没有做非常清晰的架构,就是想把这个系统尽快地提供上线。这时候所有的表都在一个数据库里,大家都对这件事情非常熟悉,我可以做订单,也可以做管理系统。
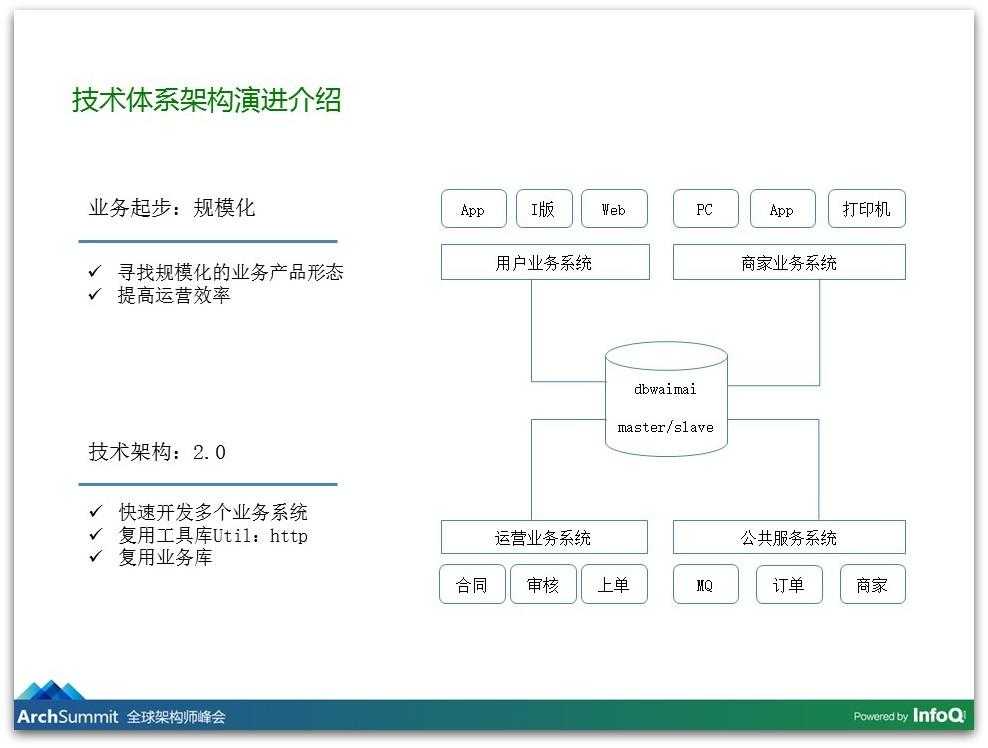
但是这个事情在规模化、用户量迅速上升之后给我们带来非常大的困扰,因为之前我们是有很多技术欠债的,在这个阶段里面我们就做了重大的架构调整,在这个调整里主要说两点:
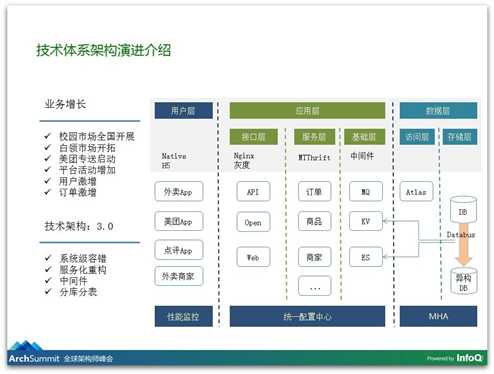
总结一下的话,我们的演进大概分了这样一个阶段:整体上有一个多逻辑耦合在一起的情况按服务化拆分出来,每一个服务独立专注地做一个事情,然后我们再做应用级的容错,到现在我们在做多机房的容错。
在缓存上,我们早期使用了Redis,在Redis Cluster还没发布之前我们用了他们的Alpha版本,当然也踩了很多坑。后来我们用了自研的KV系统,最早的时候我们把所有业务的KV都是共用的,这个也有很大的问题:如果所有的业务共用的KV集群,其中某一个业务导致这个KV集群有问题的话,所有的业务都受影响。后来我们也做了每一个业务拆分自己专用的KV集群。
在数据库这一层上,基本上是把一些大表的查询、对数据库有较大伤害的查询变成了高级的搜索,在数据库和应用层之间加了中间件。在360开源的Atlas基础上做了我们自己的定制,这个中间件有个好处:我们对数据库的变更对于业务层是透明的,比如说觉得能力不够要扩容,我们加几台从库,业务方是无感知的,而且我们会做SQL的分组,即数据库的分组,哪些SQL到哪个数据库上,到主库还是从库上去,我们业务是不用关心的。

下面介绍一下做外卖这个事情上遇到的挑战:
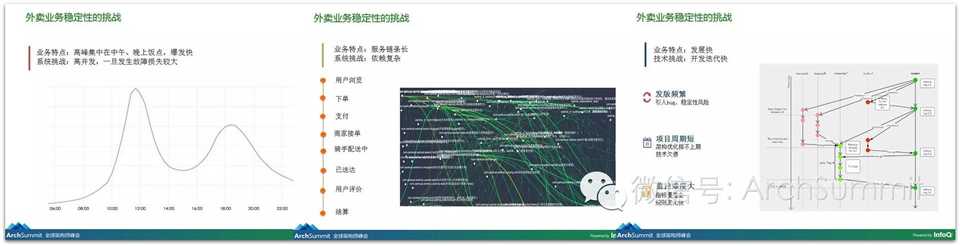
介绍一下我们对于稳定性的定义,我们也是拿四个“9”来衡量稳定性,但是我们分别用于两个指标:系统可用性和订单的可用性。
我们还是要保证四个"9"的可靠性,而我们怎么去做:我们从四个阶段来扎实地做这些事情:一个是日常运行,二是事前预警,三是事故处理,四是事后总结,我会详细地介绍这四个环节:
首先在日常运行里面,我们要做好稳定性的架构设计,这里有几个原则:

日常运行里面,另外一个工作是做例行的稳定性巡检
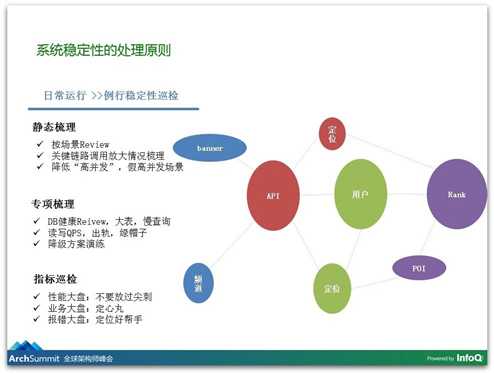
对于平时来讲,给我们增强稳定性最可靠的信心就是在线压测,我们和其他大厂差不多,我们也在做在线压测这个东西,我们有一个在线压测的平台。我们希望通过压测来发现什么呢?首先发现系统里面的性能瓶颈,到底哪个系统是里面最弱的,以及我们要知道系统服务的上限和能力。
另外更关键的是,我们需要通过压测来验证我们的监控和报警机制是否生效的,可能很多时候大家都说我们配置了非常完整的监控方案,但是它可能不生效,一旦不生效就惨了。另外,我们要通过压测指导我们报警的警戒线是怎么设置,到底CPU是设置是30%还是70%,什么时候该报警,我们就通过压测来确立。
这个压测告诉我们指导意见,警戒线设置到哪个位置是给你留有充足时间的,如果你的报警发生之后马上挂了,其实报警是没有用的。我们可以通过压测来要设置警戒行动线,到这个时候我们要考虑和关注这个问题,留给稳定性处理有足够的时间。
我们怎么做呢?我们把线上的流量经过日志录取下来,把录取的流量放到我们的压测平台里,这是对于读请求的。对于写请求的,我们做一些事务的模拟,我们有一些模拟的脚本伪造一些根据我们场景做的数据。这些数据再经过一次染色,把真实数据和测试数据隔离开,经过我们异步阶梯加压的模块,我们先通过异步的方式把它迅速打起来,我们可以把量打地非常高;另外我们是通过阶梯性地打,我们不是一次打到2万,我们可能先到5000,然后再到9000,然后打到15000,然后再持续10分钟,我们对这个监控的流量施压过程和跟我们监控指标关联起来,我们做压测之前先看和哪几个指标关联,哪几个指标到了什么阈值就自动中止压测,毕竟我们是在线上做这些事情,不能对真实线上的情况产生影响。对于其他依赖的服务,比如说支付,这些真的不能压到银行去,外部的服务我们做了一些Mock。
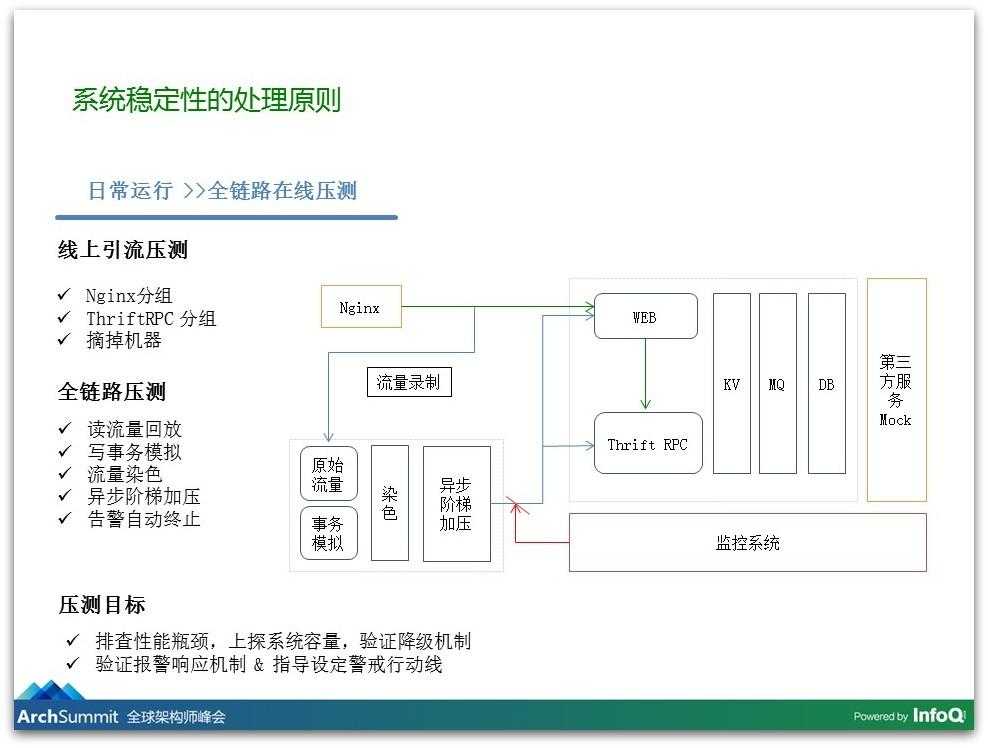
对于事前预警阶段,如果真的有事故发生我们希望更早曝露出来触发报警,然后有充足的时间去应对这些事情,我们在这个地方在事前预警阶段我们有一些监控心得:
首先是有分层的监控:有系统级的监控,例如性能指标的监控,还有业务监控,我们还有平时健康度的分析,我们的应用是不是健康的。
我们分享一下在业务监控的想法,业务监控其实是最让你放心的,你有一个业务大盘,这个大盘如果有一个波动你就立马发现了,说明现在可能会有影响,你可能会收到报警,例如什么CPU的报警,你去看大盘,大盘可能说没有什么影响,这样你不会那么慌。
另外,我们系统里面把订单相关的所有信息和重要节点做了日志的输出,日志通过flume收集到Kafka再到Storm里,我们在Storm里对这些日志进行汇聚,汇聚的结果放在HBase里,在这些结果里我们有几个非常好的应用:
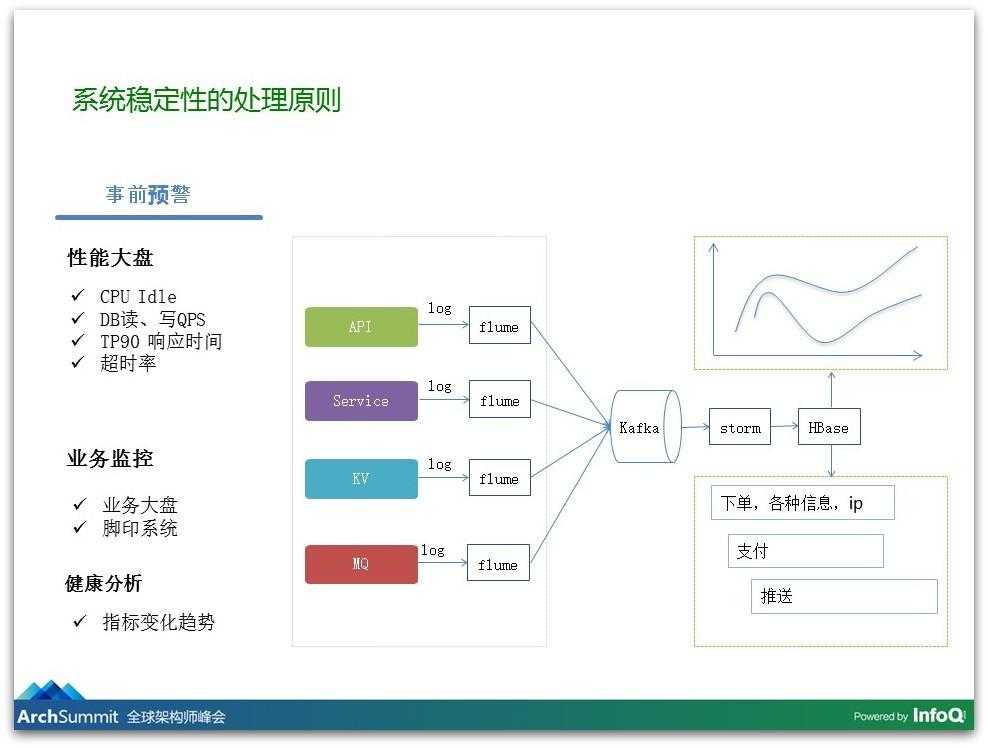
还有可能有一些意想不到的事情发生,真的出现了事故怎么办?第一原则就是及时止损。我们知道发版是导致稳定性变化的第一因素,如果立马确定是由发版引起的这次事故,最快速最有效的方法就是回滚。另外可能还有一些流量异常,对于流量异常我们有限流的模块,我们提供了三种限流的策略:
事故发生之后,我们需要对事故做一个非常深刻的总结。这里面有几个非常强的要求,第一是必须找到根源,根源我们采用5whys的分析方法,一定要追踪到最根本的原因,从现象开始追踪。另外去要核算清楚这次造成多少损失,因为我们要算我们的稳定性。还有一个方面,你要对这次系统出现问题的过程、你处理的过程和中间的流程进行总结,看哪些地方可以优化。
我建议的做法是:我们需要把这次事故处理的过程详细记录下来,它可能是需要精确到分钟的,比如说某一分钟谁跟谁做了什么动作,这对我们总结很有帮助。因为有可能事故处理过程本身是有问题的,比如说你去扩容花了30分钟时间,这是有问题的;比说你在处理过程中做了错误的决定也是有问题的,所以我们把过程中做了详细的记录。我们对于这个事故的总结和Review,我们希望能看到什么?在这个总结里面,我们希望看到到底哪里出了问题,我们能不能更快的发现它,将来如果再发现,能不能比现在处理的更快一点。
讲完这些处理原则,再介绍一下我们做这个事情的实践。我们对稳定性的要求是极高的,每一个订单的损失我们非常敏感,我们就有一个实践的动作:就是力保关键路径不挂,我们要保住订单,那要保住和订单交易相关的所有路径不能挂,所以平时我们就梳理出了和订单交易的关键路径,从用户下单、从用户开始选门店,然后开始选菜,然后下单,然后到配送完成,这个过程里边每一个环节关联了哪些服务,这些服务都应该具备有降级的功能。
比如说Rank服务,用户首先打开我们App的时候,我们就会给他最附近的、可以配送到的一些商家,这些服务会给用户之前的购买记录来做推荐,我们会给他更好的排序。如果我们Rank的服务出现问题了,我们可以迅速地将这个Rank的服务给降级掉,改成默认按销量去排序,这样用户也是可以选餐的。所以这个环节里面的每一步我们都可以降级的,从而保证在下单这个关键路径上服务都OK,其他服务可以接受它的挂掉。
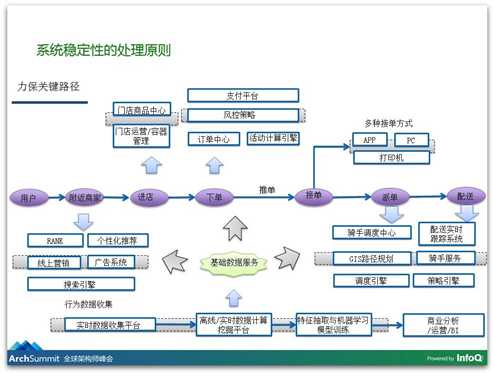
另外,预案的建设,你永远需要想一下你将来可能发生什么,如果发生这些事情的话,我们该怎么办?所以你在做这个事情之前就要去考虑,我们认为性能是功能的一部分,稳定也是功能的一部分,而不是大家做这一次技术方案设计,做完之后再来优化性能和稳定性,我们需要在做这个架构设计的时候考虑到性能和稳定,它们是产品功能的一部分,同时也要考虑到如果性能稳定性出现问题,用户体验是怎样的,用户不希望看到很傻的提示。
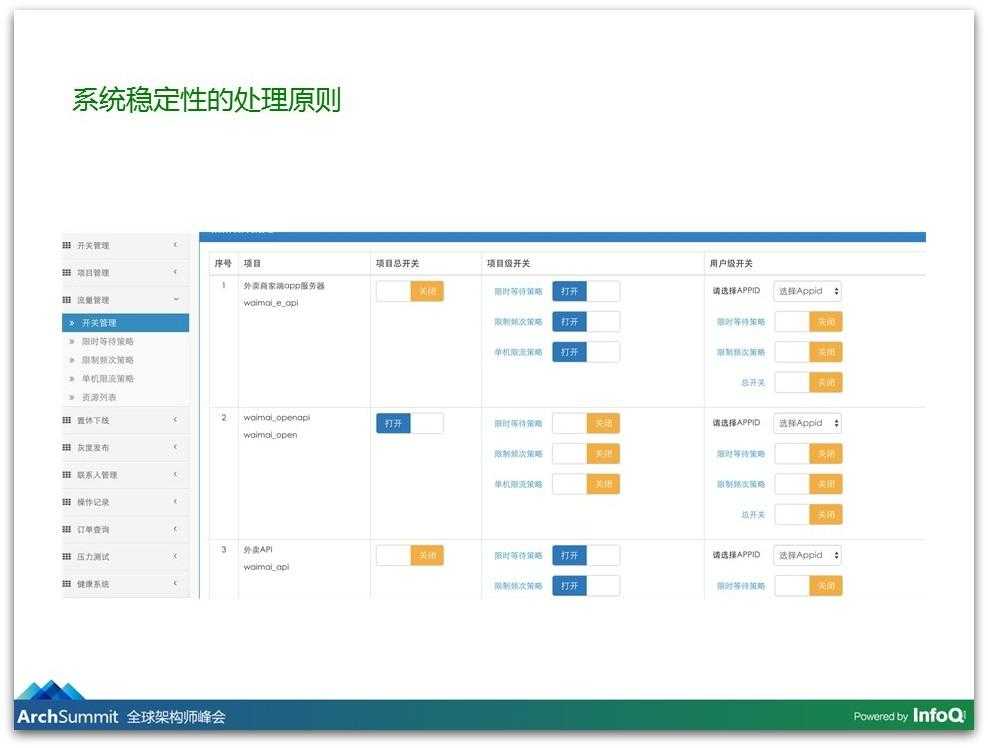
所以我们在功能设计的时候,就考虑到了出现这样的情况我们可能要降级,这个降级的方案可能是一个开关,就会有非常多降级开关,有些情况下是更复杂的场景:如果这个情况发生了,我们可能把这个开关和那个开关给关掉,这是我们的降级管理平台,我们真的把一个降级开关给做成了一个开关,就是开启和关闭,同时我告诉你开启意味着什么、影响着什么。
再介绍一下这个平台里面我们有对灰度的管理,有对压测的管理,有对健康度的分析,另外有一块我们称为核按钮,即如果事情发生之后你要保住的底线,如果我们的系统出现问题,商家不能接单或者配送无法送出的话,用户下的这些单子都会被取消掉,这个体验是很糟的。我下了单,然后5分钟你告诉我商家不能接单这个订单被取消掉了,我忍了我换了一家,结果又被取消了,这会骂人的。如果商家不能接单,就不要让用户下单,如果这些情况发生,我们就迅速启动核按钮,把我们筛选的这些不能接单的商家迅速变为休息,可以保证用户向可以服务的商家去下单。
在整个实践的过程中,与稳定性斗智斗勇的过程中,我们总结了非常多的流程,我们叫做标准操作流程SOP,这些流程涵盖了从需求、开发、测试、上线、监控、故障处理的每个环节,每一个环节都是标准的、非常严格的、经过认真思考的流程来供大家参考的,一定要按照流程来操作。为什么这样做?
给大家举个例子,按照这个步骤走是值得信赖的,每一步都有非常好的预案与系统的配合。比如说出现事故,大家是很慌的,因为那么多人在投诉、那么多人在等着说不能点餐了,为什么,美团外卖怎么了?然后我们处理事故的同学说:你不要慌。怎么可能呢?那么多用户在投诉,老板还在后面问你怎么样了,什么时候才能处理好,怎么可能不慌呢,臣妾做不到呀。这个时候你肯定很慌的,这个时候你还要把很多问题考虑清楚几乎是不可能的,有些同学说我这里需要这么做、我需要写条SQL,结果忘了Where的语句,所以你在非常紧张的情况下根本想不全这件事情的,那怎么办?我们只能提前想好,如果会出现这种情况我们就执行这条SQL,然后放在那里经过无数人的Review和实验,它是可靠和可以被执行的。所以,我们在整个过程里面收集了非常非常多的操作流程,每一步都有非常严格的要求。

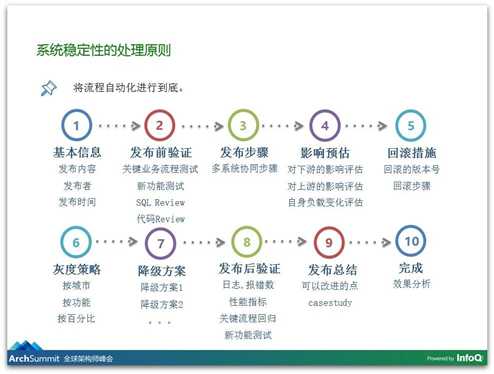
我们梳理完了这些流程,希望把这些流程变成自动化的,否则人工操作的话,我们是可以要求大家严格执行,但是毕竟也是效率低下的,我们需要把很多的操作变成自动化。举个例子,下图是我们发版的流程,看上去还蛮复杂的,一共有10步,我们有非常多的要求,你在发版之前需要验证哪些事情,发完版之后要验证哪些功能,最重要的是你要去评估,你要去评估有什么影响,你对下游有什么影响。更重要的是,我们对每次发版都一定要有回滚措施,就是应急预案,你要回滚到哪个版本,如果是一个大的项目,大家一起联合发布的,是怎样的回滚过程,谁先操作谁后操作。对于每一次发版,没有预案是不允许发布的。
大家可能会说,我要改库、我要改表,我已经把表结构变了,还要写数据,这时候无法回滚,回不去了。那不行,那是不可能的,你一定有办法把它回退过去。另外,我们有每一次的降级方案和灰度的策略,如果是这一次发版引发的故障的,发版之后整个过程做一次非常详细的整理,到底哪些地方出了什么问题。
在处理的过程中有几句总结的话跟大家分享:
标签:
原文地址:http://www.cnblogs.com/WeiGe/p/5923507.html