标签:
#include<stdio.h>
#include<string.h>
char prog[80],token[8];
char ch;
int syn,p,m=0;
int n,row,sum=0;
char *rwtab[6]={"begin","if","then","while","do","end"};
void get1()
{
/*分3块,标识符,数字,符号3块,分别对应if,else——if和else*/
for(n=0;n<8;n++)
token[n]=NULL;
ch=prog[p++];
while((ch==‘ ‘)||(ch==‘/n‘))
{
ch=prog[p];
p++;
}
if((ch>=‘a‘&&ch<=‘z‘)||(ch>=‘A‘&&ch<=‘Z‘))//标识符或变量名
{
m=0;
while((ch>=‘0‘&&ch<=‘9‘)||(ch>=‘a‘&&ch<=‘z‘)||(ch>=‘A‘&&ch<=‘Z‘))
{
token[m++]=ch;
ch=prog[p++];
}
token[m++]=‘\0‘;
p--;
syn=10;
for(n=0;n<6;n++)
{
if(strcmp(token,rwtab[n])==0)
{
syn=n+1;
break;
}
}
}
else if(ch>=‘0‘&&ch<=‘9‘)//number
{
sum=0;
while(ch>=‘0‘&&ch<=‘9‘)
{
sum=sum*10+ch-‘0‘;
ch=prog[p++];
}
p--;
syn=11;
}
else {
switch(ch)//other string
{
case‘<‘:
m=0;
token[m++]=ch;
ch=prog[p++];
if(ch=‘>‘)
{
syn=22;
}
else if(ch==‘=‘)
{
syn=21;
token[m++]=ch;
}
else
{
syn=20;
p--;
}break;
case‘>‘:
m=0;
token[m++]=ch;
ch=prog[p++];
if(ch==‘=‘)
{
syn=24;
token[m++]=ch;
}
else
{
syn=23;
p--;
}break;
case‘:‘:
m=0;
token[m++]=ch;
ch=prog[p++];
if(ch==‘=‘)
{
syn=18;
token[m++]=ch;
}
else
{
syn=17;
p--;
}break;
case‘*‘:syn=11;token[0]=ch;break;
case‘/‘:syn=16;token[0]=ch;break;
case‘+‘:syn=13;token[0]=ch;break;
case‘-‘:syn=14;token[0]=ch;break;
case‘=‘:syn=25;token[0]=ch;break;
case‘;‘:syn=26;token[0]=ch;break;
case‘(‘:syn=27;token[0]=ch;break;
case‘)‘:syn=28;token[0]=ch;break;
case‘#‘:syn=0;token[0]=ch;break;
case‘\n‘:syn=-2;break;
default: syn=-1;break;
}
}
}
int main()
{
p=0;
row=1;
printf("输入一串字符串(以#结束):");
do
{
scanf("%c",&ch);
prog[p++]=ch;
}while(ch!=‘#‘);
p=0;
do
{
get1();
switch(syn)
{
case 11:
printf("(%d,%d)",syn,sum);
break;
case -1:
printf("错误(row)!");
getch();
break;
case -2:
row=row++;
break;
default:
printf("(%d,%s)",syn,token);
break;
}
}while(syn!=0);
getch();
}
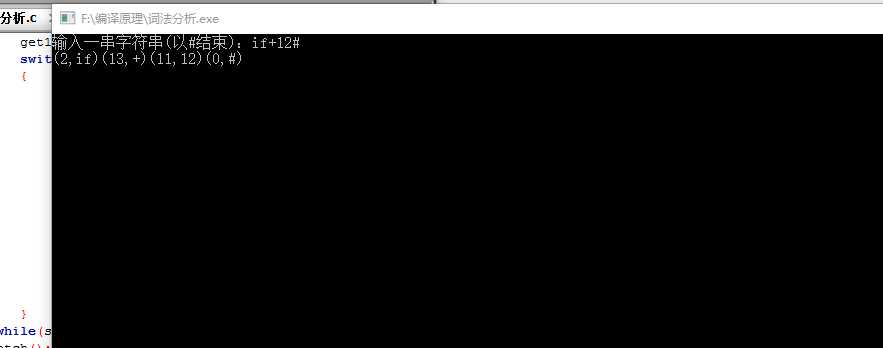
本次实验,通过自己思考与在网上找资料参考下解决。
程序中除了(begin,if,while,end,do,then)六个关键字符,还根据老师给出的种别码表加入了{>....等字符}
我认为词法分析是作为扫描器一样的功能,将字符一个一个读取标记,为接下来的语法分析使用。
标签:
原文地址:http://www.cnblogs.com/shadows24/p/5924970.html