标签:
1> HDFS系统架构
HDFS(Hadoop Distributed File System),及Hadoop分布式文件系统
作用: 为Hadoop分布式计算框架提供高性能,高可靠,高可扩展的存储服务
架构:典型的主(NameNode)从(DataNode)架构,两者一对多的关系,一个节点对应一个DataNode
NameNode是整个文件系统的管理节点(文件系统的最高管理者), 负责对文件系统命名空间的
管理与维护,另外, 也负责面向于客户端对文件的操作,控制,存储统一管理与分配,
而DataNode则是存储具体文件
数据类型:在HDFS上,有两种数据类型,分别是元数据类型(Metadata由NameNode存储在镜像文件中),
所谓元数据就是文件除了实际内容外所有表示文件信息的数据,即MetaNode
另外一种数据类型则是实际的文件数据了,在DataNode上存储形式是
块(block,Hadoop1.x:64M;Hadoop2.x:128M),每个块可能有多个
副本(默认3个,可自定义),因为由于副本机制,提高了文件数据的可靠性
NameNode启动时加载镜像文件(fsimage.xxx)和操作文件(edits.xxx)到内存,
并等待DataNode上报元数据,形成文件系统结构
一旦NameNode宕掉,则导致整个HDFS无法正常服务
2> HA定义
HA(High Availability,高可用性):系统对外提供正常服务时间的百分比
举个例子:Hadoop运行时会有两种情况,一是Hadoop正常提供服务时间(MTTF),
二是不能提供正常服务时间(MTTR), 所以HA=MTTF/(MTTF+MTTR)*100%
通过上面可以看出,HA能精确度量系统对对外提供正常服务的能力,也就是说系统的高可用程度
HDFS出现无法提供正常服务情况: 正常的软硬件升级,维护;客户误操作导致HDFS发生故障
绝大部分是由于软件导致
3> HDFS HA 原因分析及应对措施
可靠性: NameNode作为管理节点,统一维护和控制HDFS文件系统,而DataNode存储实际文件,
且有副本护驾,也就是说NameNode成为了HDFS系统的单一故障点,
NameNode能否正常运行决定了HDFS的可靠性
可维护性: 一旦NameNode无法提供正常服务,如果元数据没有损坏,那就好说,重新启动即可,
但元数据一旦损坏且没有任何措施,那么,NameNode的维护时间将无限大;
DataNode因为副本的原故,既是块文件损坏,也会很快恢复,NameNode也决定了
系统的可维护性,精确一点是NameNode元数据的可维护性决定HDFS的可维护性
4> 现有HDFS HA解决方案
主要是从使用者的角度出发,提高元数据的可靠性,减少NameNode服务恢复时间,
措施主要是给元数据做备份,另外HDFS自身就有多种机制来确保元数据的可靠性
减少NameNode服务恢复时间的措施有两种思路:
a. 基于NameNode重启恢复模式,对NameNode自身启动过程进行分析,优化加载过程,减少启动时间
b. 启动一个NameNode热备节点,当主节点不能正常提供服务,切换为热节点,切换时间成为恢复时间
从效率上分析,第一种思路尽管进行了优化,但NameNode的启动时间仍受文件系统规模的限制,
第二种则突破了这种限制,现有比较成熟的HA解决方案有:
a. Hadoop元数据备份
利用Hadoop自身元数据备份机制,NameNode可以将元数据保存到多个目录,一般是一个本地目录,
有个远程目录(通过NFS进行共享),当NameNode发生故障,可以启动备用机器NameNode,加载远程目录
中的元数据信息提供服务
优点:
Hadoop自带机制,成熟可靠,使用简单方便,无需开发,配置即可
元数据有多个备份,可有效保证元数据的可靠性,并且元数据内容保持在最新状态
缺点:
元数据需要同步写入多个备份目录,效率低于单个NameNode
恢复NameNode也就是重启NameNode,这样恢复时间与文件系统规模成正比
由于备份的元数据在远程目录上,那么NFS在操作阻塞情况下,将无法提供正常服务
b. Hadoop的SecondaryNameNode方案
启动一个SecondaryNameNode节点,定期从元数据信息(fsimage)和元数据操作日志(edits)下载,
然后两个文件合并生生成新的镜像文件,推送给NameNode并重置edits
NameNode启动时,只需加载新的fsimage
优点:
Hadoop自带机制,成熟可靠,使用简单方便,无需开发,配置即可
减少NameNode启动所需时间,防止edits文件过去庞大
缺点:
没有做热备,那么重启时,文件系统的规模和启动时间成正比
有概率在NameNode宕掉时,SecondaryNameNode并未做同步
也就可能一部分操作数据会丢失,重启后的文件系统并不是最新的
c. Hadoop 的 CheckPoint Node 方案
CheckPoint(检查点)原理基本与SecondaryNameNode相同,实现方式不同,
该方案利用Hadoop 的CheckPoint机制进行备份,配置一个CheckPoint Node节点,
该节点定期区合并元数据镜像文件和用户操作日志edits,在本地形成最新的CheckPoint并上传到
Primary NameNode 进行更新,一旦NameNode宕掉,可以启动备份NameNode节点读取CheckPoint信息
并提供服务
优点:
使用简单方便,无需开发,配置即可
元数据有多个备份
缺点:
没有做热备,切换节点时间长
和SecondaryNameNode一样,有概率恢复的元数据信息不是最新的
d. Hadoop 的Backup Node 方案
利用Hadoop自身的Failover措施,配置一个Backup Node,Backup Node 在内存和本地都保存
一份HDFS最新的命名空间元数据信息,一旦NameNode宕掉,可使用Backup Node中最新的元数据信息
优点:
Hadoop自带机制,无需开发,配置即用
Backup Node的内存中保留了最新的元数据信息避免NFS挂载进行备份的所带来的风险
Backup Node可以直接利用内存中的元数据信息进行CheckPoint并保存到本地,效率比从
NameNode下载元数据进行CheckPoint效率高
Backup Node在内存中保存,一旦有操作日志,Backup Node内存同步并更新本地磁盘的edits,
两个步骤都成功,整个操作才算成功,并保证了元数据的最新状态
缺点:
该方案还不成熟,NameNode无法提供服务时,Backup Node 还不能直接接替NameNode提供服务
Backup Node 未保存Block的位置信息,等待DataNode上报,即便后期实现了热备,仍需要一部分时间进行切换
当前版本只允许一个Backup Node 连接到NameNode
e. DRDB方案
利用DRDB方案机制进行元数据备份
也就是在NameNode无法提供服务时,启动备用机器的NameNode,读取DRDB备份的元数据信息
优点:
比较成熟的备份机制
元数据有多个备份,保证了元数据的最新状态
备份工作由DRDB完成,对于新的操作日志,NameNode无需同步到多个备份目录,效率上优于元数据备份
缺点:
没有做热备,切换机器启动NameNode时间长
元数据的可靠性没有保障,需要引入新的机制去保证
f. FaceBook 的AvatarNode方案
一种热备机制,首先AvatarNode作为Primary NameNode对外提供服务,Standby Node 处于SafeMode模式
在内存中保存Primary NameNode最新的元数据信息,两者依靠NFS进行交互,DataNode报告操作日志时会同时
向两个Node中发送Block位置信息,因此保证了元数据的最新状态一但Primary NameNode宕掉,直接由
Standby Node接替并成为Primary Node对外提供服务,大大缩短切换时间
优点:
提供热备、切换时间大大缩短
集成在FaceBook自用的Hadoop中,并部署到了自己的集群
缺点:
修改了部分源码,增加了一定的复杂性,在软件维护上带来一定问题
参考资料少,只提供一个备份节点
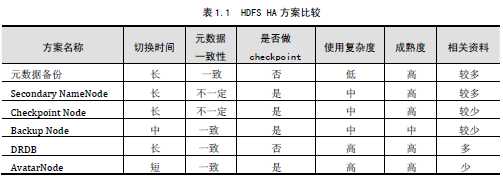
5> 方案优缺点比较
标签:
原文地址:http://www.cnblogs.com/eRrsr/p/5927355.html