标签:blog http 使用 数据 ar 2014 问题 div
聚集索引扫描,首先我们知道数据它是以索引键为叶节点排列起来的树形数据结构,表中每行的数据都附属在索引键中,对这样的表进行数据查找时,最快的方式当然是“聚集索引查找”。什么情况下才是“聚集索引扫描”呢?是当你要查找的数据的条件字段上没有索引时,此时查询执行器将对整个表中的数据挨个的进行读取确认符合查询条件的数据,但当该表上有字段设有聚集索引时,该扫描过程称之为“聚集索引扫描",相反的情况是当该表上没有一个字段设有”聚集索引“时,该扫描过程称之为”表扫描“。其实他们本质上的过程都是一样的,就是挨个的获取表中每一行的数据,确认满足符合条件的数据的过程。从性能上看也几乎是一样的。
表扫描,表中的数据是以”堆“的形式存放起来的,也就是该表在插入一条新数据时,不用考虑这条新数据应该逻辑上放在哪个位置,只需知道它前一条数据的位置,放在它的后面即可,这里要注意一点,就是大家千万不要以为以聚集索引存放的数据在物理磁盘上也是顺序存放的哟!它们以块的方式存放在磁盘上的随机位置,只是使用链表的方式通过指针指示其前驱和后继节点的位置。这其中的道理,大家悟悟吧!原因很简单,假设聚集索引表在磁盘上数据存放是先后聚集在一起的,那么当一条中间节点的数据插入到一个靠前的位置时,那么岂不是要移动几万或是几亿的数据向磁盘的后位置去。那是太可怕了。
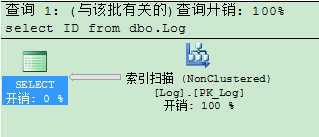
我们对于聚集索引扫描和表扫描比较容易理解的,但是对于非聚集索引扫描不太容易理解,这一点也往往容易使初学者感到很是困惑,原因是总认为没必要存在非聚集索引扫描,因为如果查询结果不具有高选择性的话,在聚集索引表中可以使用聚集索引扫描,在对表中会使用表扫描的,那么为什么要会存在非聚集索引扫描呢?
之所以有这样的问题,是因为我们没有考虑到一种情况,那就是查询结果如果被建有非聚集索引的字段覆盖或包含了,而此时where条件字段上的非聚集索引对于本次查询结果又不具有高选择性,那么你说查询优化器会选择怎样的查询计划呢?1、非聚集索引查找?这肯定不行,因为结果集不具有高选择性。2、聚集索引扫描(或表扫描)?答案也不是,因为前两者开销还是比较大的。我们的优化器何不选择该非聚集索引呢?只要对该该索引执行一次扫描,那么查询根本不用访问数据页,因为查询结果字段都被该索引覆盖或包含了,这个代价可比前两者小多了。
哈哈!
蛋疼的郁闷——聚集索引扫描、非聚集索引扫描、表扫描区别,布布扣,bubuko.com
蛋疼的郁闷——聚集索引扫描、非聚集索引扫描、表扫描区别
标签:blog http 使用 数据 ar 2014 问题 div
原文地址:http://www.cnblogs.com/liuche/p/3908528.html