标签:
第八课时作业
静哥
by 2016.4.11~2016.4.17
【作业描述】
1.总结redis在节省内存开销方面做过哪些设计
2.总结概括五种对象的关键点
【作业-1:总结redis在节省内存开销方面做过哪些设计】
(1)跳跃表是一种有序数据结构,查询效率和平衡树媲美,实现上比平衡树简单,可以用跳跃表代替平衡树;查找复杂度平均是O(logN)z,最坏是O(N);
(2)跳跃表在redis里只有2个地方使用:一个是实现有序集合键(sorted set)、一个是集群节点中用作内部数据结构;也就是说,跳跃表是sorted set类型的底层实现之一;
(3)每个节点都有层高,层高越高,查找效率越高;存储节点的时候,随机生成1-32之间的随机数,假设生成的层高随机数为N,则,该节点数值在第一层~第N层都会被插入,且每层的数据都是有序的,这样在查找该节点时从最高层依次查找,最高层查不到,接着查次高层;
(4)同节点的层次直接通过数组实现,不是通过链表
整数集合(intset)就是将所有整数类型封装到intset这个结构体里,根据实际存储的数据长度来动态选择使用哪种数据类型;
(1)整数类型有int16_t int32_t int64_t等;分别表示的整数范围如下:

(2)整数集合(intset)将所有整数类型封装的目的是:减少内存使用。可以根据存入的整数数值大小,动态选择用int16_t类型的还是int32_t类型的等;
FB")
当设置一个集合后,会判断集合里元素的整数值大小,最大的元素是什么类型的整数,就会将intset设置为该类型;例如一个集合里最大的元素是50000,那么这个集合的数据类型就是int32_t类型的,其他元素值也将被设置为int32_t类型;一个集合里最大的元素是30000,那么这个结婚的数据类型就是in16_t类型的;
例如:新增一个元素,该元素长度超过原来的类型范围,就需要类型升级,例如从int16_t升级到int32_t;
(1)Redis里说的SDS字符串、链表、字典。压缩列表、整数集合等都是数据结构,redis并没有直接使用数据结构来实现键值对数据库,而是创建了一个对象系统,这个系统包含字符串对象、列表对象、哈希对象、集合对象、有序集合对象这5种类型的对象;通过不同类型的对象来判断一个对象是否可以执行给定的命令。
(2)redis的对象系统还实现基于引用计数技术的内存回收机制:有个引用计数参数,通过识别这个参数判断对象是否被使用,没有被引用则是否该对象的内存;此外,还实现了对象共享机制,一定条件下,可以多个数据库共享一个对象来节约内存;
(3)redis的5种数据类型,都是通过redisObject结构体来实现的,通过对该结构体的引用,根据实际使用生成5种数据类型的对象;结构体如下:
T3W(5`2KO]6}YOK%8~EC")
(3.1)Type属性表示类型,type:4的意思是定义属性type,占4个比特,unsigned等同于unsigned int;
(3.2)Encoding属性也占4个比特位;lru属性占24个比特位;
也就是type属性、encoding属性、lru属性合在一起,占用32个比特,也就是4个字节;
(3.3)Refcount属性,是int类型,占4个字节;ptr属性也占用4个字节;
综上,redisObject结构体一共占用12个字节,也就是redisObject结构体,巧妙运用位字段,节省内存,同时相对直接操纵位来编程也更容易。
(3.4)Type属性对应的值有5种,也就是5种对象类型:REDIS_STRING/REDSI_LIST/REDIS_HASH/REDIS_SET/REDIS_ZSET
0}TZZA2A%{Y1L`[DUH`2")
(3.5)Encoding属性表示编码类型:5种对象类型,对应不同的编码类型,会有不同的底层实现;即,编码不同,底层支撑的数据结构不同;
5565RA9_0DW$NO(BI_@RR")
Redis在减少内存开销方面做的设计:(1)整数集合;(2)定义redisObject一个结构体,来实现5种数据类型的引用,也即是5种对象;redisObject结构体里,定义type属性区分5种数据类型,多种底层存储结构支撑;而且,redisObject结构体里的type属性、encoding属性、lru属性是用位字段定义的,巧妙运用位字段,节省内存;
【作业-2:总结概括五种对象的关键点】
9`UZIMN)Z$DV)$CVEB0")
RawL类型的字符串长度大于39字节,不利于连续内存的分配,因此Raw类型的内存分片不是连续的;
可以用object encoding命令来查看数据的底层存储结构;
(2)

--- ziplist类型的使用要满足如下2个条件:所有节点长度都小于64字节+元素个数小于512;
列表对象使用ziplist类型的2个条件,是默认在redis.conf配置文件里的:

--- linkedlist类型:不能满足ziplist类型的条件的,都会采用linkedlist
--- Linkedlist是链表,扩展性好;且不需要连续的内存空间,内存利用率高;但是查找性能相对差;
--- ziplist类似数组,有高效的访问,查找性能更高;但是因为ziplist需要连续内存空间,对内存的利用率较低;
(3)
~D]TN@6_0B5JFA@$DG")
--- ziplist类型:同事满足2个条件:所有节点长度都小于64字节 + 列表元素个数小于512 (注意:键值对挨在一起,先添加的键值对会被放在表头方向,后添加的放在表尾方向)
哈希对象使用ziplist类型的这2个限制条件是默认在redis.conf配置文件里的:

--- 字典类型:不能满足使用ziplist类型的2个条件,则采用字典类型
(2)
~AVYQJAGO`MM88DY@X)K")
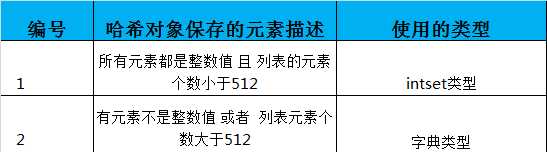
--- intset类型:整数集合,满足2个条件才行:所有元素都是整数值 + 列表元素个数小于512
--- 字典类型:不满足上述2个条件,则采用字典;
(2)集合对象使用intset类型的限制条件是默认在redis.conf配置文件里的:
B%(9JN(0YDP)TI")
(1)有序集合对象有2种类型实现:ziplist类型、字典+跳跃表
--- ziplist类型:需要满足2个条件:所有节点长度都小于64字节 + 列表元素的个数小于128;(注意:元素和分支紧挨一起;先添加的键值对会被放在表头方向,后添加的放在表尾方向)
在redis.conf配置文件里的默认参数如下:
(5H1P90ZBWCE4(X")
--- 字典和跳跃表:不能满足用ziplist类型的,就用字典+跳跃表实现
(2)用字典+跳跃表组合实现,而不是只用字典的原因如下:
跳跃表保存分值和元素,字典也保存分值和元素;之所以用字典+跳跃表的组合,总体是为了在不同场景下的高性能;
zrank zrange等命令是通过跳跃表api实现;zscore命令通过字典实现;
字典和跳跃表都通过指针共享内存的方式避免重复存储;

标签:
原文地址:http://www.cnblogs.com/cjing2011/p/9c2656ae8a3bb9b52352f9a977842f52.html