标签:
#include <stdio.h> #include <string.h> char prog[80],token[8],ch; int syn,p,m,n,sum; char *rwtab[6]={"begin","if","then","while","do","end"}; void scaner(void); main() { p=0; printf("\n please input a string(end with ‘#‘):\n"); do{ scanf("%c",&ch); prog[p++]=ch; }while(ch!=‘#‘); p=0; do{ scaner(); switch(syn) { case 11: printf("( %-10d%5d )\n",sum,syn); break; case -1: printf("you have input a wrong string\n"); //getch(); return 0; break; default: printf("( %-10s%5d )\n",token,syn); break; } }while(syn!=0); //getch(); } void scaner(void) { sum=0; for(m=0;m<8;m++) token[m++]= NULL; ch=prog[p++]; m=0; while((ch==‘ ‘)||(ch==‘\n‘)) ch=prog[p++]; if(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘))) { while(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘))||((ch>=‘0‘)&&(ch<=‘9‘))) { token[m++]=ch; ch=prog[p++]; } p--; syn=10; for(n=0;n<6;n++) if(strcmp(token,rwtab[n])==0) { syn=n+1; break; } } else if((ch>=‘0‘)&&(ch<=‘9‘)) { while((ch>=‘0‘)&&(ch<=‘9‘)) { sum=sum*10+ch-‘0‘; ch=prog[p++]; } p--; syn=11; } else { switch(ch) { case ‘<‘: token[m++]=ch; ch=prog[p++]; if(ch==‘=‘) { syn=22; token[m++]=ch; } else { syn=20; p--; } break; case ‘>‘: token[m++]=ch; ch=prog[p++]; if(ch==‘=‘) { syn=24; token[m++]=ch; } else { syn=23; p--; } break; case ‘+‘: token[m++]=ch; ch=prog[p++]; if(ch==‘+‘) { syn=17; token[m++]=ch; } else { syn=13; p--; } break; case ‘-‘: token[m++]=ch; ch=prog[p++]; if(ch==‘-‘) { syn=29; token[m++]=ch; } else { syn=14; p--; } break; case ‘!‘: ch=prog[p++]; if(ch==‘=‘) { syn=21; token[m++]=ch; } else { syn=31; p--; } break; case ‘=‘: token[m++]=ch; ch=prog[p++]; if(ch==‘=‘) { syn=25; token[m++]=ch; } else { syn=18; p--; } break; case ‘*‘: syn=15; token[m++]=ch; break; case ‘/‘: syn=16; token[m++]=ch; break; case ‘(‘: syn=27; token[m++]=ch; break; case ‘)‘: syn=28; token[m++]=ch; break; case ‘{‘: syn=5; token[m++]=ch; break; case ‘}‘: syn=6; token[m++]=ch; break; case ‘;‘: syn=26; token[m++]=ch; break; case ‘\"‘: syn=30; token[m++]=ch; break; case ‘#‘: syn=0; token[m++]=ch; break; case ‘:‘: syn=17; token[m++]=ch; break; default: syn=-1; break; } } token[m++]=‘\0‘; }
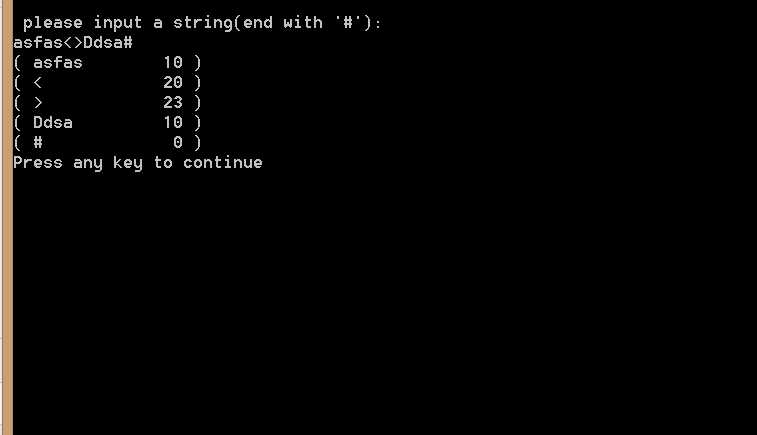
PS: 只是一个很简单的词法分析器,还是觉得有很多不尽人意的地方,需要学习与修改,请老师指导!
标签:
原文地址:http://www.cnblogs.com/dami666/p/5936968.html