标签:
文章链接:https://zhuanlan.zhihu.com/p/20900216
1、图像可能分类是事先已知的,比如:分类集合={小猫,小狗,小花,......}
2、图像分类就是为给定的图像给它一个从分类集合中挑出一个,打上标签,表示它就是这个类。
以下为了计算的方便,图像统一用矩阵表示,这是因为,在计算机的世界里,对图像的操作就是对一堆0-255的像素进行操作,而这些像素都存放在矩阵中。
一个32*32的图片,含有32*32*3个像素,每个像素的值是[0,255](从黑到白,哈哈),3表示RGB三个通道的信息。
3、最近邻分类器的思想,是利用距离来作为评价准则。比如:
---------------------------------------------------------------------------------
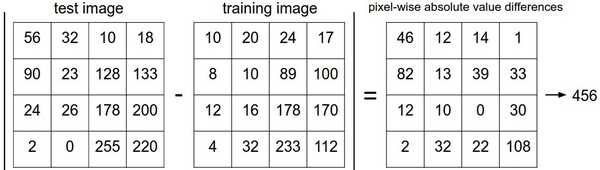
两张图片使用L1距离来进行比较。逐个像素求差值,然后将所有差值加起来得到一个数值。如果两张图片一模一样,那么L1距离为0,但是如果两张图片很是不同,那L1值将会非常大。这也就说明了,最近邻分类器是根据像素进行分类的。这就可能会出现两张根本就不同的图像但差值相同,就误以为同一个类别的问题,比如:
-------------------------------------------------------------------------------------------------------------------------------------

在高维度数据上,基于像素的的距离和感官上的非常不同。上图中,右边3张图片和左边第1张原始图片的L2距离是一样的。很显然,基于像素比较的相似和感官上以及语义上的相似是不同的。
所以:
-------------------------------------------------------------------------------------------------------------------------------------
4、Knn(k近邻分类器)。k个分类中的k值怎么确定?不断对超参数进行微调。具体的方法:
将训练样本平分为3或5或8份(视样本个数而定),将其中一份作为验证样本,其余的作为训练样本。用训练样本对模型训练好了之后,再用验证样本来调整k值,找到k的满意值。
【*】得到k值后,不能用训练集和验证集在对模型进行调整,这会破坏模型的精度;这时候就用测试集仅跑一遍来看准确率。
5、交叉验证。训练集很小的时候,我们的验证数据很少,就要使用交叉验证的方法。具体:比如将训练集平均分成5份,其中4份用来训练,1份用来验证。然后我们循环着取其中4份来训练,其中1份来验证,最后取所有5次验证结果的平均值作为算法验证结果。
6、在验证集上调优,尝试足够多的k值,尝试L1和L2两种范数计算方式。
ps:
给定向量x=(x1,x2,...xn)
L1范数:向量各个元素绝对值之和
L2范数:向量各个元素的平方求和然后求平方根
Lp范数:向量各个元素绝对值的p次方求和然后求1/p次方
L∞范数:向量各个元素求绝对值,最大那个元素的绝对值
标签:
原文地址:http://www.cnblogs.com/beihaidao/p/5938049.html