标签:

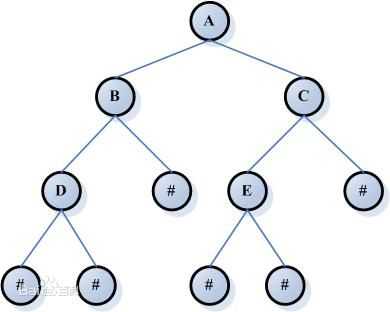
二叉树很容易理解,在这里我们一般用满二叉树:就是非叶子节点都有2个分支的树形数据结构
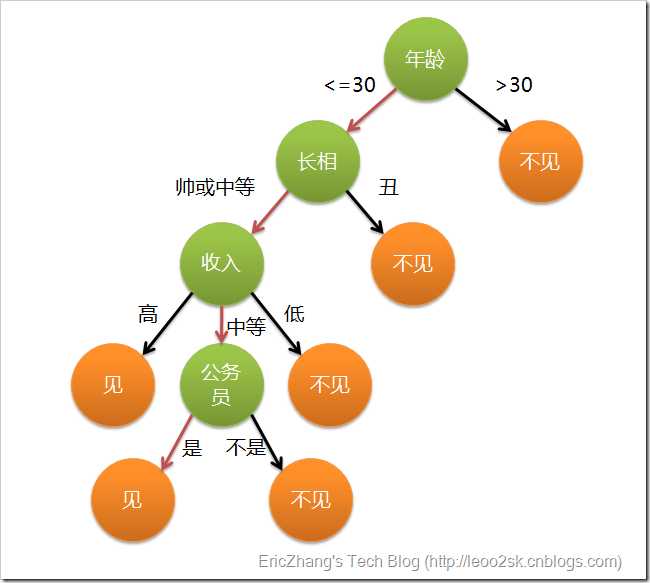
决策树最初是用来做决策用的,就好像下面的见不见相亲对象的决策过程一样;
如果把最后的决策结果看成是分类,那么决策树就可以用来分类了,例如,下面的例子就是把相亲对象分为见和不见两种。
下面通过一个例子来区分这些概念
特征,正负样本,训练集(数据),验证集(数据),预测集(数据)
我们的数据集是一百个点,如下图所示,是二维平面的100个点,这个就是我们总的数据集(全集),这些数据在文本中就是下面第二张图所示的三个字段(x坐标,y坐标,label(正样本还是负样本))
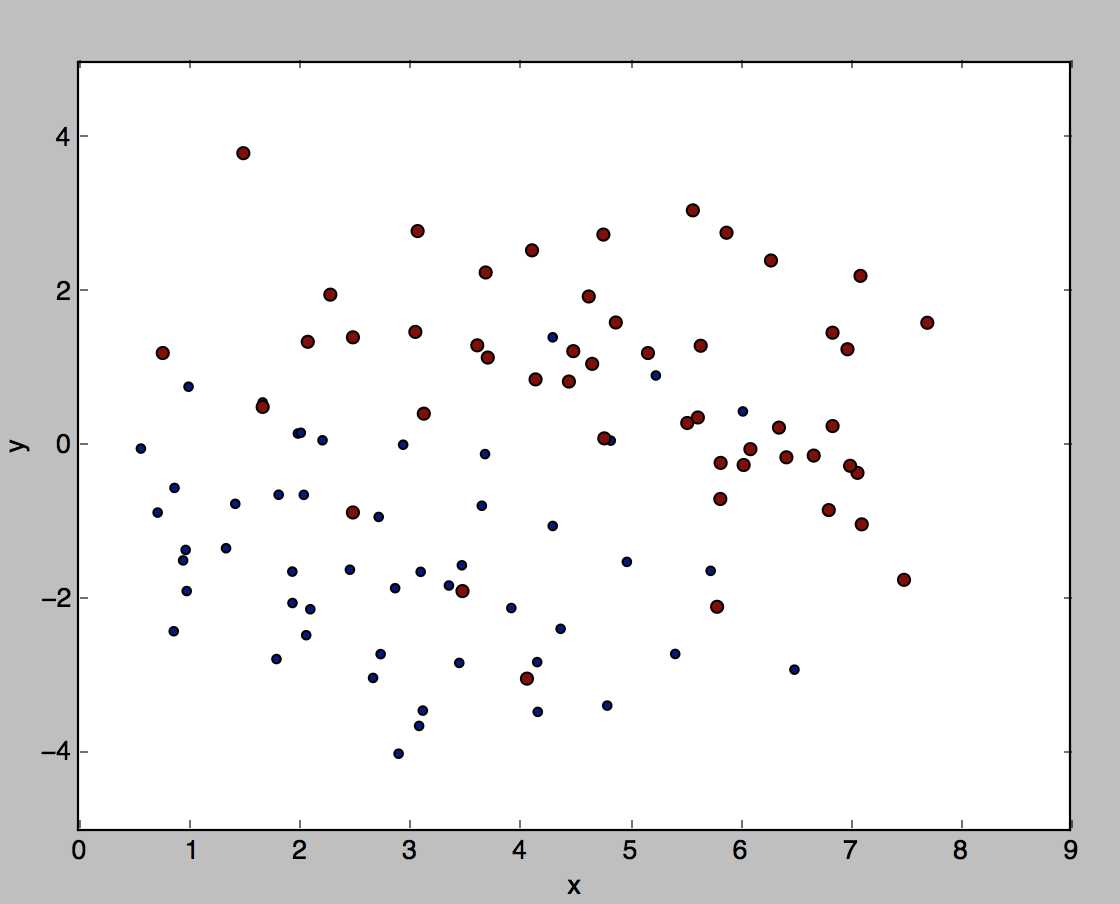
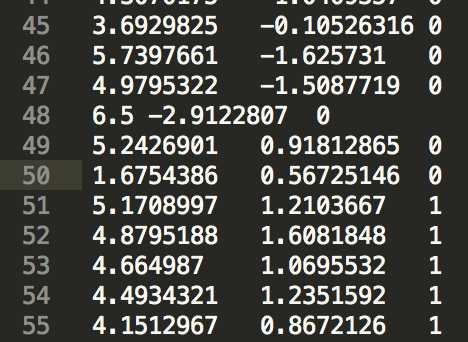
对于每个数据点来说,都有自己的x,y坐标以及自己的类别(正还是负,0或者1);
而我们的目标是通过每个数据点的x,y坐标去确定该数据点的类别,但是我们不想每来一个数据点都自己亲眼观察去判断,我们希望教会机器怎么去辨别每个数据点的类别。
我们需要告诉机器什么样的数据点的类别是1,什么样的数据点的类别是0,这就是正负样本
我们把正负样本放在一起,就组成了一个数据集,并从中抽取一部分或者全部,这就是训练集
我们要教会机器通过什么属性来区分数据点的类别,例如我们教会机器通过数据点的x,y坐标来判断数据点的类别,那么在这里x,y坐标就是特征
教会了机器区分数据点,一般我们需要验证机器区分的正确率,我们需要用一些已知类别的数据点,对比这些数据点原本的类别和机器辨别出来的类别,计算机器区分的正确率,这些数据点的特征和类别就是验证集。
训练集和验证集都是正负样本组成的集合的子集,两者数据的格式是一样的。一般来说我们可以在正负样本集调整训练集和验证集的比例。
最后,我们有一批新的数据点,我们只有这些数据点的特征(x,y坐标),我们想让机器预测这些数据点的类别,这些只有特征的数据集我们成为预测集。
验证集在验证的过程中也充当了预测集的角色,不过验证集自带类别,可以验证预测的准确性,而预测集则是完全依赖与机器的预测。
所以,我们需要保证预测集和训练集、验证集是属于同一个样本空间的,否则,预测的结果可能不如人意。
下面我们来看下模型训练过程中常见的问题
1:样本选择的问题
在这个例子中,我们是有一个全集的,我们可以看到数据整体分布,这是比较理想的;
然而很多时候,我们甚至不知道样本空间的边界在哪里,我们不知道我们抽取的正负样本是否能代表整个样本空间?
2:正负样本比例问题
在这个例子中,正负样本比例1:1,然而,在实际数据中,我们甚至不知道真实的样本空间里面正负样本的比例;
而正负样本的比例有时候会对模型的评价产生影响
3:模型评价的问题
我们一般通过验证集来检验模型的好坏,然而模型是过拟合还是欠拟合我们是很难衡量的,而过拟合还是欠拟合一般也是通过验证结果来判断,但是训练集和验证集的选择有一定的随机性,
所以,模型评价也是一个难题。
而且,对于不同的集合,对模型的要求也是不一样的,是尽量不要预测错,还是尽量找回更多,因实际情况而定。
标签:
原文地址:http://www.cnblogs.com/qwj-sysu/p/5940517.html