标签:
课程地址:https://www.coursera.org/learn/machine-learning/lecture/8SpIM/gradient-descent
首先,教授介绍了一下课程中将会用到的符号和意义:
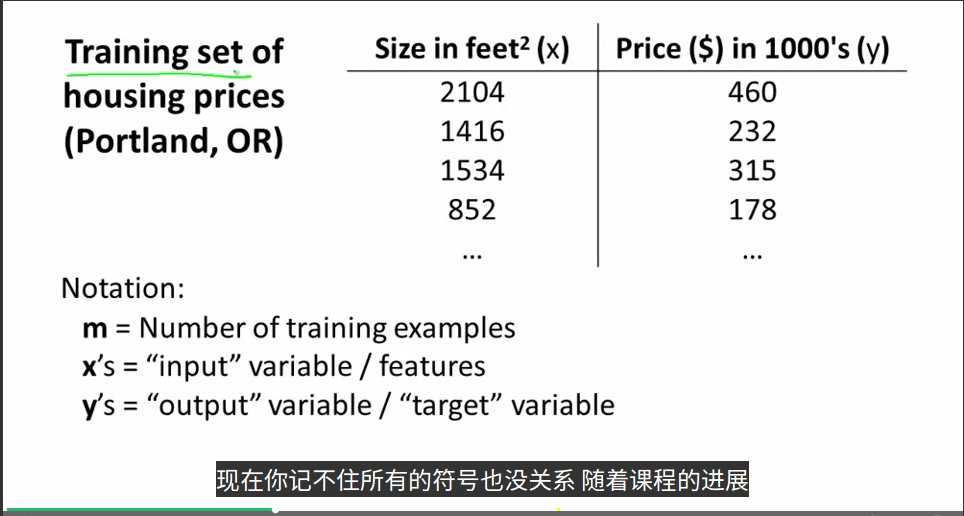
m:训练样本的数目
x:特征量
y:目标变量
(x,y):一个训练样本
(x^(i),y^(i)):i不是指数,而是指第i行的样本
Univariate linear regression:一元线性回归
整体目标函数 --> 代价函数(平方误差函数,平方误差代价函数)

梯度下降算法可以将代价函数j最小化。梯度函数是一种很常用的算法,它不仅被用在线性回归上,也被广泛地应用于机器学习领域中的众多领域之中。
下图是代价函数J中解决线性回归问题的问题概述:

我们希望通过改变theta参数的值来最小化代价函数。
这里,我们考虑有两个参数的情况,我们可以考虑到一个三维图形,两条坐标分别表示theta0和theta1。
梯度下降要做的事,就是从某个起始theta对值开始,寻找最快的下降方向往下走,在路途上也不断地寻找最快下降的方向更改路线,最后到达一个局部最低点。
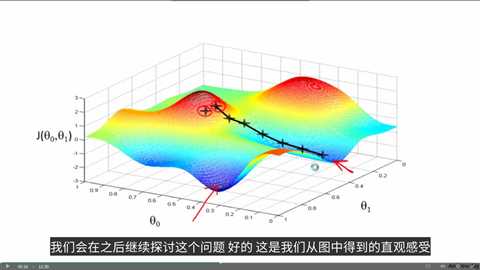
可以看到,如果起始点稍有偏差,那么我们可能会得到一个非常不同的局部最优解,这也是梯度下降的一个特点。
我们从上图中获得了梯度下降的直观感受,接下来让我们看看梯度下降的定义:

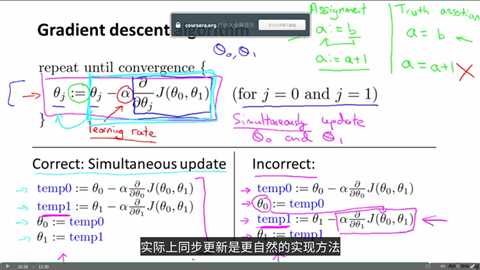
分析一下梯度下降定义公式的一些细节:
我们用“:=”来表示赋值。注意,如果我们写作“=”,表达的意识并不是赋值,而是判断为真的说明,比如a=b,就是断言a的值是等于b的。
α在这里是一个数字,被称为学习效率,在梯度下降算法中,它控制了我们下山时会卖出多大的步子。因此如果α比较大,那我们用大步子下山,如果它比较小,我们就迈着很小的小碎步下山。
在公式中,有一个很微妙的问题。在梯度下降中,我们要同时更新theta0和theta1,而不是先后更新。如果先更新了theta0,再更新theta1就会造成theta1的值出错。
《机器学习》第一周 一元回归法 | 模型和代价函数,梯度下降
标签:
原文地址:http://www.cnblogs.com/danscarlett/p/5944517.html