标签:
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。对adaBoost算法的研究以及应用大多集中于分类问题,同时也出现了一些在回归问题上的应用。就其应用adaBoost系列主要解决了: 两类问题、多类单标签问题、多类多标签问题、大类单标签问题、回归问题。它用全部的训练样本进行学习。





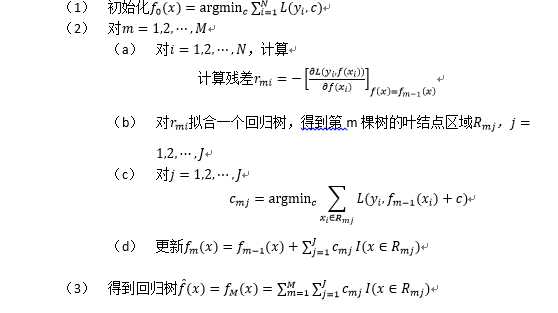
Adaboost算法优缺点:
优点
1) Adaboost是一种有很高精度的分类器
2) 可以使用各种方法构建子分类器,Adaboost算法提供的是框架
3) 当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单
4) 简单,不用做特征筛选
5) 不用担心overfitting(过度拟合)
缺点
1) 容易受到噪声干扰,这也是大部分算法的缺点
2) 训练时间过长
3) 执行效果依赖于弱分类器的选择
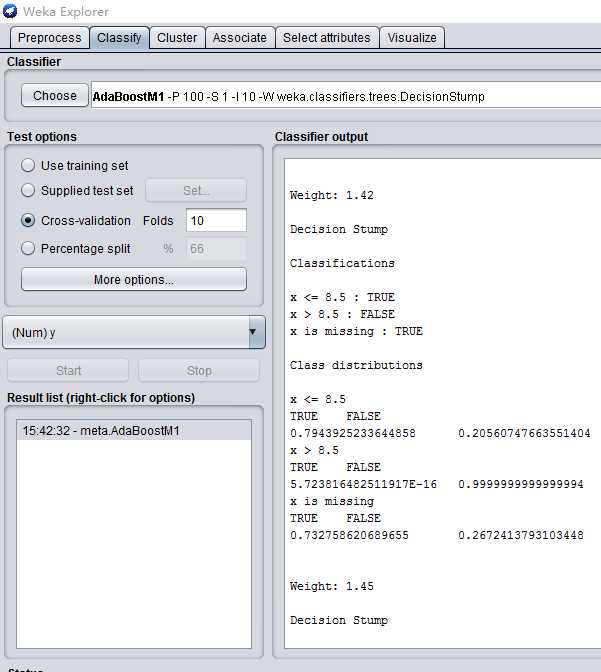
#########################Weka###########################
Adaboost m1是一个非常受欢迎的二元分类算法
#################R语言############################
library(adabag)
## rpart library should be loaded
data(iris)
iris.adaboost <- boosting(Species~., data=iris, boos=TRUE, mfinal=5)
iris.adaboost
## Data Vehicle (four classes)
data(Vehicle)
l <- length(Vehicle[,1])
sub <- sample(1:l,2*l/3)
mfinal <- 10
maxdepth <- 5
Vehicle.rpart <- rpart(Class~.,data=Vehicle[sub,],maxdepth=maxdepth)
Vehicle.rpart.pred <- predict(Vehicle.rpart,newdata=Vehicle[-sub, ],type="class")
tb <- table(Vehicle.rpart.pred,Vehicle$Class[-sub])
error.rpart <- 1-(sum(diag(tb))/sum(tb))
tb
error.rpart
Vehicle.adaboost <- boosting(Class ~.,data=Vehicle[sub, ],mfinal=mfinal, coeflearn="Zhu",
control=rpart.control(maxdepth=maxdepth))
Vehicle.adaboost.pred <- predict.boosting(Vehicle.adaboost,newdata=Vehicle[-sub, ])
Vehicle.adaboost.pred$confusion
Vehicle.adaboost.pred$error
#comparing error evolution in training and test set
errorevol(Vehicle.adaboost,newdata=Vehicle[sub, ])->evol.train
errorevol(Vehicle.adaboost,newdata=Vehicle[-sub, ])->evol.test
plot.errorevol(evol.test,evol.train)
标签:
原文地址:http://www.cnblogs.com/dudumiaomiao/p/5947456.html