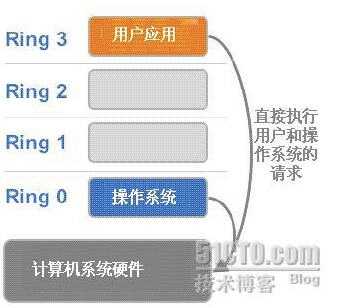
.png)
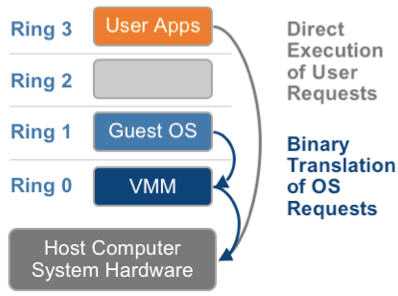
.png)
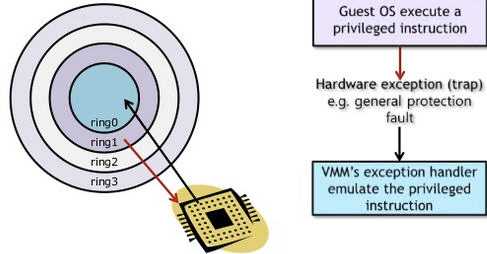
.png)
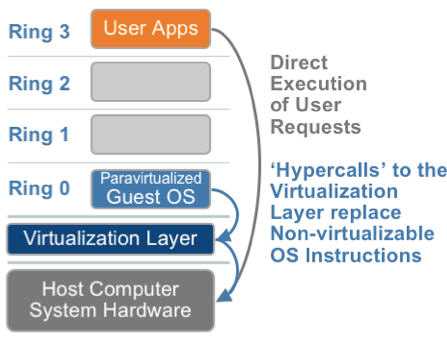
.png)
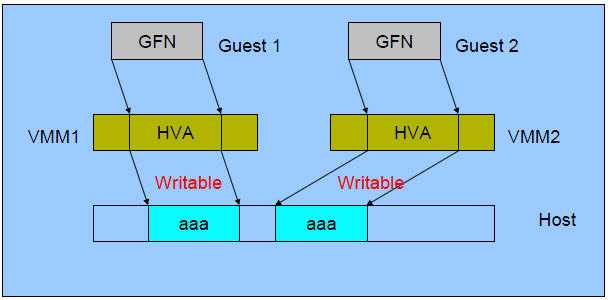
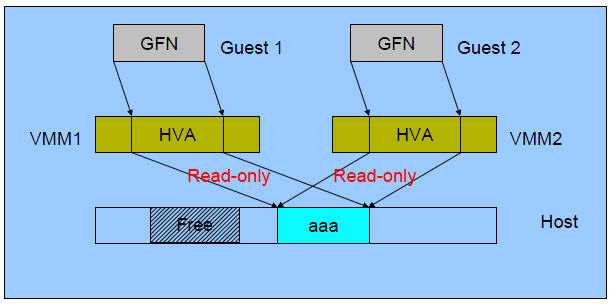
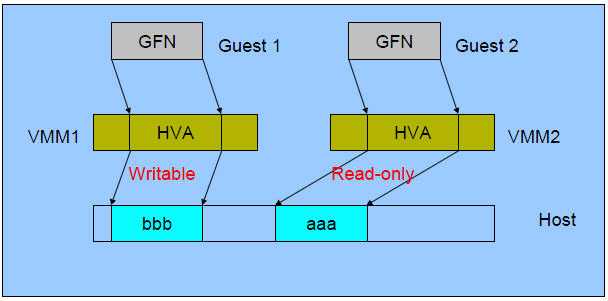
使用巨页,KVM的虚拟机的页表将使用更少的内存,并且将提高CPU的效率。最高情况下,可以提高20%的效率!
使用方法,需要三部:
mkdir /dev/hugepages
mount -t hugetlbfs hugetlbfs /dev/hugepages
#保留一些内存给巨页 sysctl vm.nr_hugepages=2048 (使用 x86_64 系统时,这相当于从物理内存中保留了2048 x 2M = 4GB 的空间来给虚拟机使用)
#给 kvm 传递参数 hugepages qemu-kvm - qemu-kvm -mem-path /dev/hugepages
也可以在配置文件里加入:
<memoryBacking> <hugepages/> </memoryBacking>
验证方式,当虚拟机正常启动以后,在物理机里查看:
cat /proc/meminfo |grep -i hugepages