标签:
专业:商业软件工程 姓名:陈楷涛 学号:201506110199
一、 实验目的
通过编写一个词法分析器,进一步了解词法之间的关系
二、 实验内容和要求
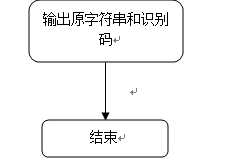
对输入的字符串进行识别,并将输出该字符串和种别码
三、 实验方法、步骤及结果测试
1. 源程序名:词法分析.c
可执行程序名:词法分析.exe
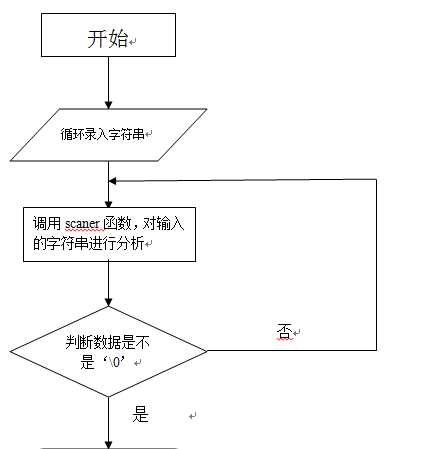
2. 原理分析及流程图
#include <stdio.h>
#include <string.h>
char prog[80],token[8],ch;
int syn,p,m,n,sum;
char *rwtab[6]={"begin","if","then","while","do","end"};
void scaner(void);
main() 主函数:循坏输入字符串和输出最后的字符串和识别码
{
p=0;
printf("\n please input a string(end with ‘#‘):\n");
do{
scanf("%c",&ch);
prog[p++]=ch;
}while(ch!=‘#‘);
p=0;
do{
scaner(); 调用scaner函数,循环输出字符串和识别码
switch(syn)
{
case 11:
printf("( %-10d%5d )\n",sum,syn);
break;
case -1:
printf("you have input a wrong string\n");
return 0;
break;
default:
printf("( %-10s%5d )\n",token,syn);
break;
}
}while(syn!=0);
}
void scaner(void) 子函数scaner:对输入的字符串进行分析
{
sum=0;
for(m=0;m<8;m++)
token[m++]= NULL;
ch=prog[p++];
m=0;
while((ch==‘ ‘)||(ch==‘\n‘))
ch=prog[p++];
if(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘)))
{
while(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘))||((ch>=‘0‘)&&(ch<=‘9‘)))
{
token[m++]=ch;
ch=prog[p++];
}
p--;
syn=10;
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{
syn=n+1;
break;
}
}
else if((ch>=‘0‘)&&(ch<=‘9‘))
{
while((ch>=‘0‘)&&(ch<=‘9‘))
{
sum=sum*10+ch-‘0‘;
ch=prog[p++];
}
syn=11;
}
else
{
switch(ch)
{
case ‘<‘:
token[m++]=ch;
ch=prog[p++];
if(ch==‘=‘)
{
syn=22;
token[m++]=ch;
}
else
{
syn=20;
p--;
}
break;
case ‘>‘:
token[m++]=ch;
ch=prog[p++];
if(ch==‘=‘)
{
syn=24;
token[m++]=ch;
}
else
{
syn=23;
p--;
}
break;
case ‘+‘:
token[m++]=ch;
ch=prog[p++];
if(ch==‘+‘)
{
syn=17;
token[m++]=ch;
}
else
{
syn=13;
p--;
}
break;
case ‘-‘:
token[m++]=ch;
ch=prog[p++];
if(ch==‘-‘)
{
syn=29;
token[m++]=ch;
}
else
{
syn=14;
p--;
}
break;
case ‘!‘:
ch=prog[p++];
if(ch==‘=‘)
{
syn=21;
token[m++]=ch;
}
else
{
syn=31;
p--;
}
break;
case ‘=‘:
token[m++]=ch;
ch=prog[p++];
if(ch==‘=‘)
{
syn=25;
token[m++]=ch;
}
else
{
syn=18;
p--;
}
break;
case ‘*‘:
syn=15;
token[m++]=ch;
break;
case ‘/‘:
syn=16;
token[m++]=ch;
break;
case ‘(‘:
syn=27;
token[m++]=ch;
break;
case ‘)‘:
syn=28;
token[m++]=ch;
break;
case ‘{‘:
syn=5;
token[m++]=ch;
break;
case ‘}‘:
syn=6;
token[m++]=ch;
break;
case ‘;‘:
syn=26;
token[m++]=ch;
break;
case ‘\"‘:
syn=30;
token[m++]=ch;
break;
case ‘#‘:
syn=0;
token[m++]=ch;
break;
case ‘:‘:
syn=17;
token[m++]=ch;
break;
default:
syn=-1;
break;
}
}
token[m++]=‘\0‘;
}
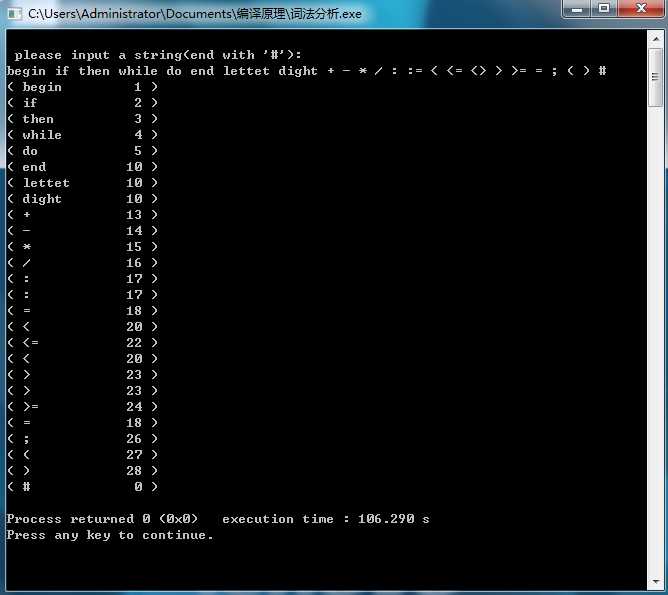
4. 运行结果及分析
四、 实验总结
心得体会:这是我第一次用C语言编写这么一个词法分析的工具,在编写这个词法分析器的过程中,我感觉我对词法分析也有了更深入的了解,但也不可避免的出现了一些问题,例如,如何原字符串进行拆分,然后一个一个进行分析 一度成为这个程序的障碍,最后,我采用了数组的方式来解决了这个问题。总而言之,这个程序为我打开了一项从未涉及过的崭新的大门,我将在这座大门后面开始我新的学习旅程。
标签:
原文地址:http://www.cnblogs.com/cktcom/p/5955030.html