标签:
有一个应用truncate表等待了一晚上,一个定时任务,跑了几年了,今天早上来发现昨晚没有执行完成,hang住了,查询发现等待事件 fast object reuse。
10.2.0.4的库
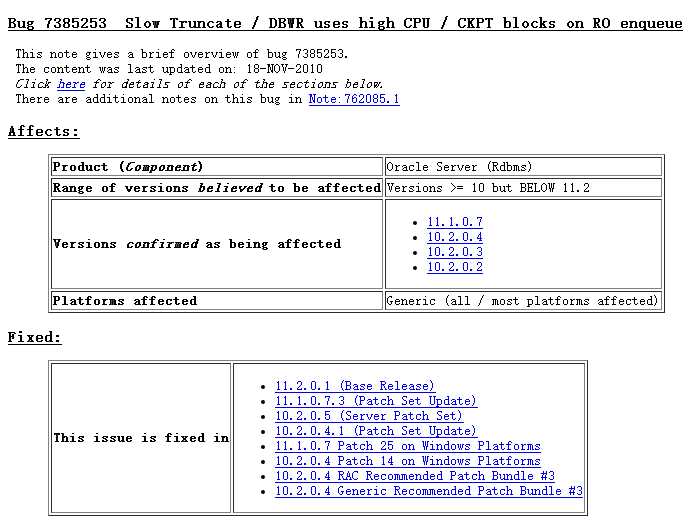
Bug 7385253 - Slow Truncate / DBWR uses high CPU / CKPT blocks on RO enqueue (文档 ID 7385253.8)
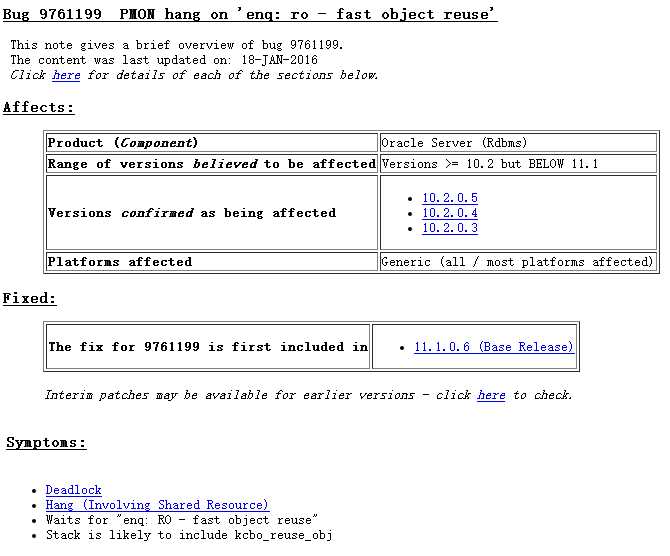
Bug 9761199 - PMON hang on ‘enq: ro - fast object reuse‘ (文档 ID 9761199.8),首先知道truncate table是DDL操作,会重置HWM,truncate table后,oracle会回收表和其表中所在的索引到initial 大小,也就是初始分配的segments大小
truncate和drop一样都是ddl语句, 操作立即生效,原数据不放到rollback segment中,不能回滚。
truncate table执行很慢可能有以下几个原因:
1.查看是不是DML操作锁定了某些记录;
2.segment header竞争;
truncate 表慢可能跟extent的数量有关系,比如说,你一个表 size 100M,每个10M ,10个extent,而又一个表 size 50M ,每个8K,6400个extent,那么,第二个表的truncate就会比第一个慢上好多
通常来说是由于extent 太多,truncate时在做回收extent的动作,这也是 local management比 dictionary management好的其中一点。如果担心下次碰到同样问题,可以考虑使用truncate table test reuse STORAGE 的语句,可以避免hung在回收extent上。就要用到分次回收的方式了, 比如说,100M的表,每次回收 20M,在感觉上可能好点。
truncate table t4 reuse STORAGE ;
alter table test_tun deallocate unused keep 80M;
alter table test_tun deallocate unused keep 60M;
alter table test_tun deallocate unused keep 40M;
alter table test_tun deallocate unused keep 20M;
truncate table test_tun drop storage;
如果truncate table 非常慢 ,可以按照以下方法来诊断:
1.请查询 相应的session 在 v$session_wait 视图中的等待事件;
2.可以用oradebug hanganalyze分析系统挂起的原因;
3.如果为了试验目的,更可以做个10046 level 8的event。
truncate的时候,dbwr占用cpu高不高?可以试一下下面文档中的workround (alter system flush buffer_cache; 后再truncate),如果生效应该就是了,你可以升到10.2.0.4.3。
是不是这个bug不好说,如果日志的大小不足导致日志切换hang住,引起dbwr的等待,出现不少free buffer busy的等待,而truncate又要做checkpoint,所以这时候前台进程也要等待dbwr,导致enqueue RO的wait变长。
MOS文档内容:


进程监控进程:负责服务器进程的管理和维护工 作,在进程失败或连接异常发生时该进程负责以下一些清理工作:
1.回滚没有提交的事务;
2.释放所持有的当前的表或行锁;
3.释放进程占用的SGA资源;
4.监视其他oracle的后台进程,在必要时重启这些后台进程;
5.向oracle TNS监听器注册刚启动的实例。如果监听器在运行,就与这个监听器通信并传递,如服务名和实例的负载等参数,如果监听器没有启动,进程监控(PMON)会定期地尝试连接监听来注册实例。
truncate表hang住(等待时间较长),出现enq:RO fast object reuse等待事件
标签:
原文地址:http://www.cnblogs.com/callmemax/p/5958571.html