标签:style blog http 使用 os io strong 数据
属性关系定义了属性之间的依赖关系,比如如果 A 有一个关联的属性 B, 那么就是 A -> B。比如,一个给定的属性关系 City -> State, 如果当前的城市是 Seattle, 那么我们一定知道 State 一定是 Washington. 通常情况下,属性之间的关系可能在原始维度表中有可能比较明显,也有可能不是很明显,但是还是可以利用起来做性能优化。比如默认情况下,所有的属性都是关联到 Key 的,这个时候的属性关系表现的就是被称之为 "Bush Attribute Relationship" - 可以理解为浓密的,比较粗野灌木丛状的这种关联关系。在这种 Bush Attribute Relationship 关系中,所有的树干都是从 Key 关键属性展开,但都同时都已自身属性结束,这就是 "灌木丛属性关系"。
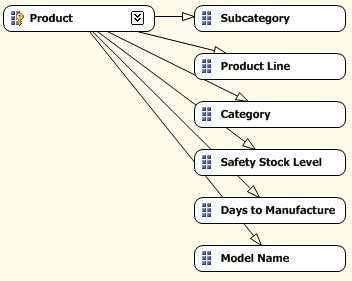
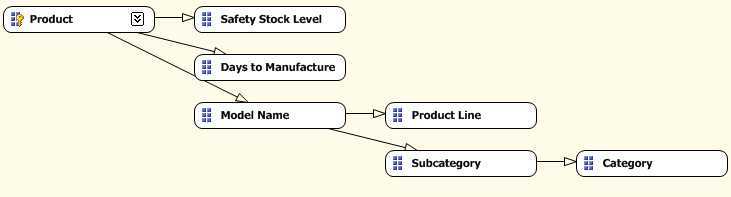
那么我们可以基于数据之间本身自有的逻辑关联来重新定义属性之间的关系以优化性能。在这种情况下,如下图所示 Model Name 定义了 Product Line 和 Subcategory (即知道了是哪一种 Model 那么就一定知道它是属于哪一个 Product Line 和 Subcategory), 而 Subcategory 定义确定了 Category (即知道它是哪一种 Subcategory 那么就一定能确定它是属于哪一种 Category; 或者理解为,这个 Subcategory 只会在一个 Category 中出现,不会同时出现在两个 Category 中)。像这种属性关系的定义一般都是多对一,或者 一对一的关联关系 -
属性之间的关系设计可以从两个方面提升性能:
可以对比上面的两幅图,比如需要获取 Subcategory 和 Category 这两个属性,包括最后做一些聚合等操作。在第一个属性关系中,在 Subcategory 和 Category 之间并没有一个显示的关系定义,查询引擎必须首先要查询到哪一个产品是属于哪一个 Subcategory,然后再确定这个产品 Product 是属于哪一个 Category,最后才能确定 Subcategory 和 Category 之间的关联关系。BIWORK 在这里开个玩笑,比如张三这条记录,记录中有一个爸爸叫李四,还有一个爷爷叫王五 (当然张三,李四和王五背后的 KEY 肯定是可以唯一的),要搞清楚李四和王五之间的关系,或者如何通过李四找到李四的爸爸,就必须首先通过李四找到他的儿子张三,然后通过张三找到他的爷爷王五,这样就知道王五是李四的爸爸了。

如果是通过这样的一种方式来确定属性之间的关系,比如说通常在 Office Excel 中通过一个层次结构去聚合和查看数据,如果这个维度比较大的话,那么这种查找关联与确定下上层次之间的关联关系的过程会非常消耗时间。相反,如果能够重新定义属性之间的这种关联关系,那么在 PROCESS 处理阶段内部索引被构建,并且索引信息中维护了他们之间的关系,因此分析服务很容易就知道哪些 Category 被哪些 Subcategory 所关联,这样效率会得到极大的提升。
同时在考虑定义属性关系的时候,也要考虑属性之间的关系是 Flexible (可变的) 还是 Rigid (固定的), 默认是 Flexible 的。
Flexible 是指在维度更新的时候,属性之间的关系是可变的。比如 BIWORK 我之前在上海工作,现在到了北京,因此 Customer -> City 这种关系就是可变的。并且,在维度增量更新的时候,之前的聚合会被删除掉然后重新计算。但是如果仅仅是新成员的增加,就不会删除已有的聚合。
Rigid 是指维度更新的时候,属性之间的关系也不改变,或者说也承诺不改变。如果发生改变了,那么在增量 Processing 处理的过程中就会发生错误。比如 Month -> Year 这种关系就是 Rigid 固定的。
但是要注意,属性关系无论是定义成 Flexible 还是 Rigid 对查询性能都没有什么影响,只是一种手段。这种设计只是确保比如 Rigid 确实要做到两个属性关系是不可变的,应该跟我们预先设计保持一致。如果出现错误,说明某些数据的改变打破了我们预先的设计,应该引起我们的注意。
有效的使用层次结构
属性如果仅仅只是保留在默认的属性层次结构中的话,那么在聚合设计阶段它们并不会主动使用到它们,不会发生真正的聚合。在查询阶段,如果包含了这些属性的引用,这个时候也还是通过主键 Key Attribute 来汇总数据。这样一来,没有利用到聚合的好处,在查询中对这些属性层次结构的使用上性能将非常慢。
为了提升查询性能,一般会通过 Aggregation Usage 属性来配置聚合属性的候选人 (这个以后再介绍)。在修改 Aggregation Usage 属性之前,还要考虑到使用用户自定义的属性层次结构。
分析服务有两种用户自定义的属性层次结构 - 自然层次结构和非自然层次结构 (Natural Hierarchy and Unnatural Hierarchy),它们各自的设计和性能特征都不相同:
自然层次结构 Natural Hierarchy - 在自然层次结构中的所有级别上的所有属性,它们与其它从层次结构顶层到底层上的其它所有属性都有着直接的或者间接的关联关系。
非自然层次结构 Unnatural Hierarchy - 在层次结构中的至少两个连续的层级上的属性,它们彼此之间是没有属性关联关系的。通常这种类型的层次结构也是用来为常用的属性创建 Drill-down 钻取导航路径,但是它本身又没有"自然层次"的特征。比如说,用户可能需要通过由性别和教育构成的层级结构来浏览数据,但是性别和教育彼此之间没有这种自然的关联关系。
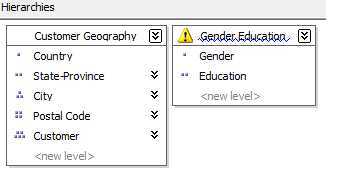
从性能的角度来考虑,自然层次结构的表现方式和非自然层次结构区别还是非常大的。在自然层级结构中,层次结构树在层次结构存储时将会被具体化或者磁盘化 Materialized。并且,参与到自然层次结构中的所有属性都会被自动的成为聚合候选属性。( 关于 Materialized 等概念可以参考索引视图,索引视图中也有这个概念。可以理解像表一样存储数据,把聚合结果和层次结构保存到磁盘上) 。
非自然层次结构不会磁盘化,并且结构中的属性并不会自动的被选为聚合候选属性。尽管没有这种自然的关联关系,但是从用户的角度来说,有这种钻取的层次路径还是非常方便的,并且在 MDX 中通过导航函数也可以非常方便的导航和计算,所以还是可以起到一定的积极作用的。
更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server)
如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章。
SSAS 系列 - 维度的优化,"灌木丛属性关系" 以及自然层次结构与非自然层次结构的概念,布布扣,bubuko.com
SSAS 系列 - 维度的优化,"灌木丛属性关系" 以及自然层次结构与非自然层次结构的概念
标签:style blog http 使用 os io strong 数据
原文地址:http://www.cnblogs.com/biwork/p/3910207.html